John Palowitch and Anton Tsitsulin, Research Scientists, Google Research, Graph Mining team Graphs are very common representations of natural systems that have connected relational components, such as social networks, traffic infrastructure, molecules, and the internet. Graph neural networks (GNNs) are powerful machine learning (ML) models for graphs that leverage their inherent connections to incorporate context into predictions about items within the graph or the graph as a whole. GNNs have been effectively used to discover new drugs, help mathematicians prove theorems, detect misinformation, and improve the accuracy of arrival time predictions in Google Maps.
A surge of interest in GNNs during the last decade has produced thousands of GNN variants, with hundreds introduced each year. In contrast, methods and datasets for evaluating GNNs have received far less attention. Many GNN papers re-use the same 5–10 benchmark datasets, most of which are constructed from easily labeled academic citation networks and molecular datasets. This means that the empirical performance of new GNN variants can be claimed only for a limited class of graphs. Confounding this issue are recently published works with rigorous experimental designs that cast doubt on the performance rankings of popular GNN models reported in seminal papers.
Recent workshops and conference tracks devoted to GNN benchmarking have begun addressing these issues. The recently-introduced Open Graph Benchmark (OGB) is an open-source package for benchmarking GNNs on a handful of massive-scale graph datasets across a variety of tasks, facilitating consistent GNN experimental design. However, the OGB datasets are sourced from many of the same domains as existing datasets, such as citation and molecular networks. This means that OGB does not solve the dataset variety problem we mention above. Therefore, we ask: how can the GNN research community keep up with innovation by experimenting on graphs with the large statistical variance seen in the real-world?
To match the scale and pace of GNN research, in “GraphWorld: Fake Graphs Bring Real Insights for GNNs”, we introduce a methodology for analyzing the performance of GNN architectures on millions of synthetic benchmark datasets. Whereas GNN benchmark datasets featured in academic literature are just individual “locations” on a fully-diverse “world” of potential graphs, GraphWorld directly generates this world using probability models, tests GNN models at every location on it, and extracts generalizable insights from the results. We propose GraphWorld as a complementary GNN benchmark that allows researchers to explore GNN performance on regions of graph space that are not covered by popular academic datasets. Furthermore, GraphWorld is cost-effective, running hundreds-of-thousands of GNN experiments on synthetic data with less computational cost than one experiment on a large OGB dataset.
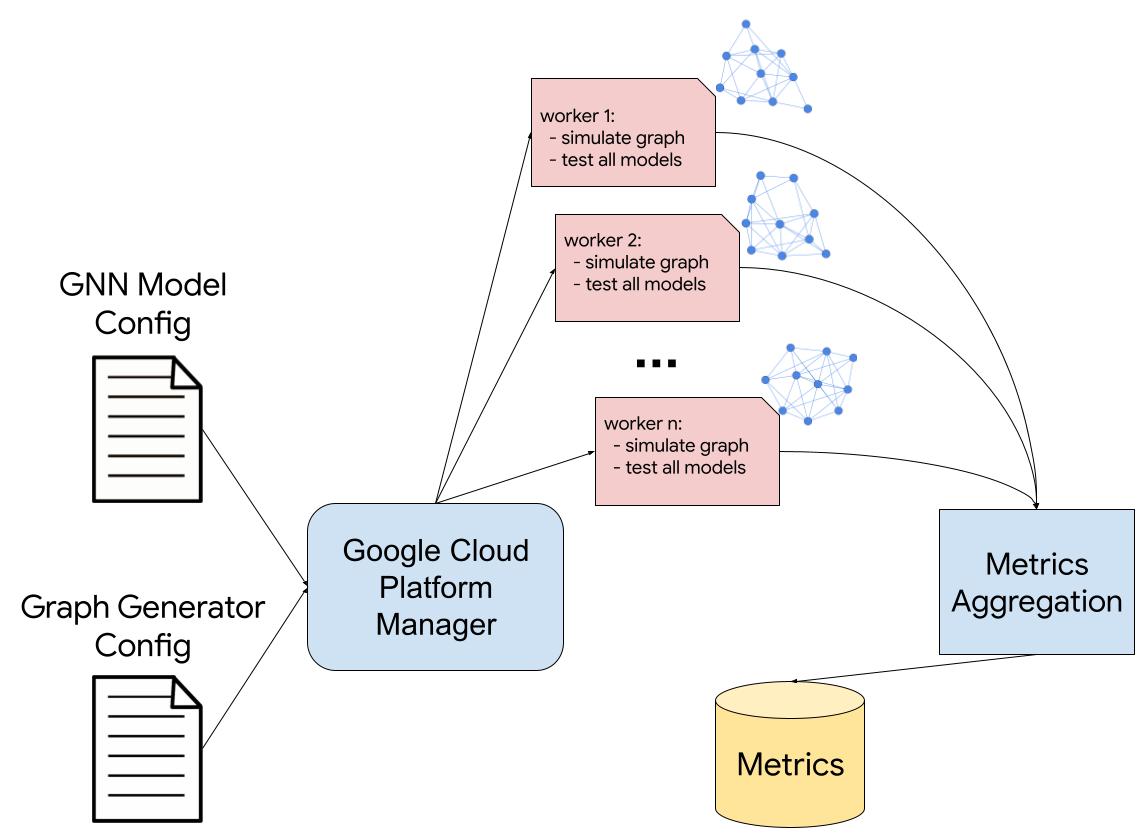 |
| Illustration of the GraphWorld pipeline. The user provides configurations for the graph generator and the GNN models to test. GraphWorld spawns workers, each one simulating a new graph with diverse properties and testing all specified GNN models. The test metrics from the workers are then aggregated and stored for the user. |
The Limited Variety of GNN Benchmark Datasets
To illustrate the motivation for GraphWorld, we compare OGB graphs to a much larger collection (5,000+) of graphs from the Network Repository. While the vast majority of Network Repository graphs are unlabelled, and therefore cannot be used in common GNN experiments, they represent a large space of graphs that are available in the real world. We computed two properties of the OGB and Network Repository graphs: the clustering coefficient (how interconnected nodes are to nearby neighbors) and the degree distribution gini coefficient (the inequality among the nodes' connection counts). We found that OGB datasets exist in a limited and sparsely-populated region of this metric space.
 |
| The distribution of graphs from the Open Graph Benchmark does not match the larger population of graphs from the Network Repository. |
Dataset Generators in GraphWorld
A researcher using GraphWorld to investigate GNN performance on a given task first chooses a parameterized generator (example below) that can produce graph datasets for stress-testing GNN models on the task. A generator parameter is an input that controls high-level features of the output dataset. GraphWorld uses parameterized generators to produce populations of graph datasets that are varied enough to test the limits of state-of-the-art GNN models.
For instance, a popular task for GNNs is node classification, in which a GNN is trained to infer node labels that represent some unknown property of each node, such as user interests in a social network. In our paper, we chose the well-known stochastic block model (SBM) to generate datasets for this task. The SBM first organizes a pre-set number of nodes into groups or "clusters", which serve as node labels to be classified. It then generates connections between nodes according to various parameters that (each) control a different property of the resulting graph.
One SBM parameter that we expose to GraphWorld is the "homophily" of the clusters, which controls the likelihood that two nodes from the same cluster are connected (relative to two nodes from different clusters). Homophily is a common phenomenon in social networks in which users with similar interests (e.g., the SBM clusters) are more likely to connect. However, not all social networks have the same level of homophily. GraphWorld uses the SBM to generate graphs with high homophily (below on the left), graphs with low homophily (below on the right), and millions more graphs with any level of homophily in-between. This allows a user to analyze GNN performance on graphs with all levels of homophily without depending on the availability of real-world datasets curated by other researchers.
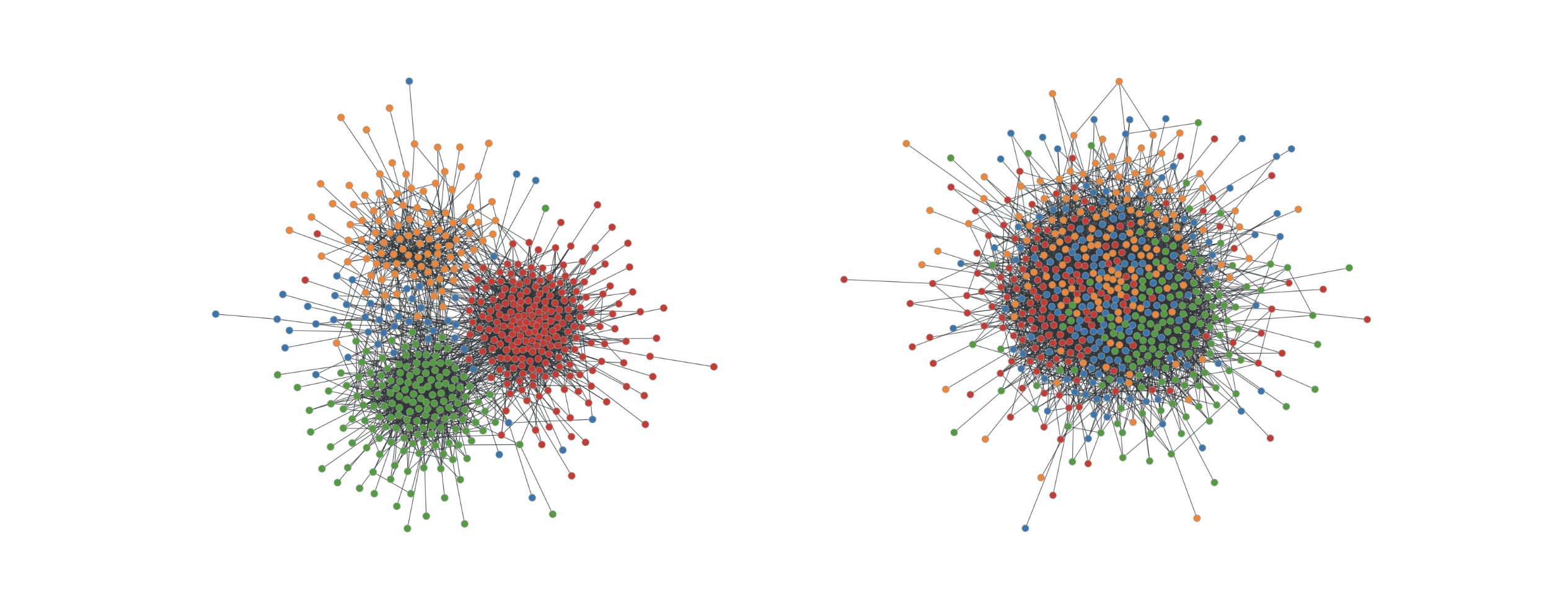 |
| Examples of graphs produced by GraphWorld using the stochastic block model. The left graph has high homophily among node classes (represented by different colors); the right graph has low homophily. |
GraphWorld Experiments and Insights
Given a task and parameterized generator for that task, GraphWorld uses parallel computing (e.g., Google Cloud Platform Dataflow) to produce a world of GNN benchmark datasets by sampling the generator parameter values. Simultaneously, GraphWorld tests an arbitrary list of GNN models (chosen by the user, e.g., GCN, GAT, GraphSAGE) on each dataset, and then outputs a massive tabular dataset joining graph properties with the GNN performance results.
In our paper, we describe GraphWorld pipelines for node classification, link prediction, and graph classification tasks, each featuring different dataset generators. We found that each pipeline took less time and computational resources than state-of-the-art experiments on OGB graphs, which means that GraphWorld is accessible to researchers with low budgets.
The animation below visualizes GNN performance data from the GraphWorld node classification pipeline (using the SBM as the dataset generator). To illustrate the impact of GraphWorld, we first map classic academic graph datasets to an x-y plane that measures the cluster homophily (x-axis) and the average of the node degrees (y-axis) within each graph (similar to the scatterplot above that includes the OGB datasets, but with different measurements). Then, we map each simulated graph dataset from GraphWorld to the same plane, and add a third z-axis that measures GNN model performance over each dataset. Specifically, for a particular GNN model (like GCN or GAT), the z-axis measures the mean reciprocal rank of the model against the 13 other GNN models evaluated in our paper, where a value closer to 1 means the model is closer to being the top performer in terms of node classification accuracy.
The animation illustrates two related conclusions. First, GraphWorld generates regions of graph datasets that extend well-beyond the regions covered by the standard datasets. Second, and most importantly, the rankings of GNN models change when graphs become dissimilar from academic benchmark graphs. Specifically, the homophily of classic datasets like Cora and CiteSeer are high, meaning that nodes are well-separated in the graph according to their classes. We find that as GNNs traverse toward the space of less-homophilous graphs, their rankings change quickly. For example, the comparative mean reciprocal rank of GCN moves from higher (green) values in the academic benchmark region to lower (red) values away from that region. This shows that GraphWorld has the potential to reveal critical headroom in GNN architecture development that would be invisible with only the handful of individual datasets that academic benchmarks provide.
 |
| Relative performance results of three GNN variants (GCN, APPNP, FiLM) across 50,000 distinct node classification datasets. We find that academic GNN benchmark datasets exist in GraphWorld regions where model rankings do not change. GraphWorld can discover previously unexplored graphs that reveal new insights about GNN architectures. |
Conclusion
GraphWorld breaks new ground in GNN experimentation by allowing researchers to scalably test new models on a high-dimensional surface of graph datasets. This allows fine-grained analysis of GNN architectures against graph properties on entire subspaces of graphs that are distal from Cora-like graphs and those in the OGB, which appear only as individual points in a GraphWorld dataset. A key feature of GraphWorld is its low cost, which enables individual researchers without access to institutional resources to quickly understand the empirical performance of new models.
With GraphWorld, researchers can also investigate novel random/generative graph models for more-nuanced GNN experimentation, and potentially use GraphWorld datasets for GNN pre-training. We look forward to supporting these lines of inquiry with our open-source GraphWorld repository and follow-up projects.
Acknowledgements
GraphWorld is joint work with Brandon Mayer and Bryan Perozzi from Google Research. Thanks to Tom Small for visualizations.