Posted by Arun Kandoor, Software Engineer, Google Research The increasing demand for machine learning (ML) model inference on-device (for mobile devices, tablets, etc.) is driven by the rise of compute-intensive applications, the need to keep certain data on device for privacy and security reasons, and the desire to provide services when a network connection may not be available. However, on-device inference introduces a myriad of challenges, ranging from modeling to platform support requirements. These challenges relate to how different architectures are designed to optimize memory and computation, while still trying to maintain the quality of the model. From a platform perspective, the issue is identifying operations and building on top of them in a way that can generalize well across different product use cases.
In previous research, we combined a novel technique for generating embeddings (called projection-based embeddings) with efficient architectures like QRNN (pQRNN) and proved them to be competent for a number of classification problems. Augmenting these with distillation techniques provides an additional bump in end-to-end quality. Although this is an effective approach, it is not scalable to bigger and more extensive vocabularies (i.e., all possible Unicode or word tokens that can be fed to the model). Additionally, the output from the projection operation itself doesn’t contain trainable weights to take advantage of pre-training the model.
Token-free models presented in ByT5 are a good starting point for on-device modeling that can address pre-training and scalability issues without the need to increase the size of the model. This is possible because these approaches treat text inputs as a stream of bytes (each byte has a value that ranges from 0 to 255) that can reduce the vocabulary size for the embedding tables from ~30,000 to 256. Although ByT5 presents a compelling alternative for on-device modeling, going from word-level representation to byte stream representation increases the sequence lengths linearly; with an average word length of four characters and a single character having up to four bytes, the byte sequence length increases proportionally to the word length. This can lead to a significant increase in inference latency and computational costs.
We address this problem by developing and releasing three novel byte-stream sequence models for the SeqFlowLite library (ByteQRNN, ByteTransformer and ByteFunnelTransformer), all of which can be pre-trained on unsupervised data and can be fine-tuned for specific tasks. These models leverage recent innovations introduced by Charformer, including a fast character Transformer-based model that uses a gradient-based subword tokenization (GBST) approach to operate directly at the byte level, as well as a “soft” tokenization approach, which allows us to learn token boundaries and reduce sequence lengths. In this post, we focus on ByteQRNN and demonstrate that the performance of a pre-trained ByteQRNN model is comparable to BERT, despite being 300x smaller.
Sequence Model Architecture
We leverage pQRNN, ByT5 and Charformer along with platform optimizations, such as in-training quantization (which tracks minimum and maximum float values for model activations and weights for quantizing the inference model) that reduces model sizes by one-fourth, to develop an end-to-end model called ByteQRNN (shown below). First, we use a ByteSplitter operation to split the input string into a byte stream and feed it to a smaller embedding table that has a vocabulary size of 259 (256 + 3 additional meta tokens).
The output from the embedding layer is fed to the GBST layer, which is equipped with in-training quantization and combines byte-level representations with the efficiency of subword tokenization while enabling end-to-end learning of latent subwords. We “soft” tokenize the byte stream sequences by enumerating and combining each subword block length with scores (computed with a quantized dense layer) at each strided token position (i.e., at token positions that are selected at regular intervals). Next, we downsample the byte stream to manageable sequence length and feed it to the encoder layer.
The output from the GBST layer can be downsampled to a lower sequence length for efficient encoder computation or can be used by an encoder, like Funnel Transformer, which pools the query length and reduces the self-attention computation to create the ByteFunnelTransformer model. The encoder in the end-to-end model can be replaced with any other encoder layer, such as the Transformer from the SeqFlowLite library, to create a ByteTransformer model.
 |
| A diagram of a generic end-to-end sequence model using byte stream input. The ByteQRNN model uses a QRNN encoder from the SeqFlowLite library. |
In addition to the input embeddings (i.e., the output from the embedding layer described above), we go a step further to build an effective sequence-to-sequence (seq2seq) model. We do so by taking ByteQRNN and adding a Transformer-based decoder model along with a quantized beam search (or tree exploration) to go with it. The quantized beam search module reduces the inference latency when generating decoder outputs by computing the most likely beams (i.e., possible output sequences) using the logarithmic sum of previous and current probabilities and returns the resulting top beams. Here the system uses a more efficient 8-bit integer (uint8) format, compared to a typical single-precision floating-point format (float32) model.
The decoder Transformer model uses a merged attention sublayer (MAtt) to reduce the complexity of the decoder self-attention from quadratic to linear, thereby lowering the end-to-end latency. For each decoding step, MAtt uses a fixed-size cache for decoder self-attention compared to the increasing cache size of a traditional transformer decoder. The following figure illustrates how the beam search module interacts with the decoder layer to generate output tokens on-device using an edge device (e.g., mobile phones, tablets, etc.).
 |
| A comparison of cloud server decoding and on-device (edge device) implementation. Left: Cloud server beam search employs a Transformer-based decoder model with quadratic time self-attention in float32, which has an increasing cache size for each decoding step. Right: The edge device implementation employs a quantized beam search module along with a fixed-size cache and a linear time self-attention computation. |
Evaluation
After developing ByteQRNN, we evaluate its performance on the civil_comments dataset using the area under the curve (AUC) metric and compare it to a pre-trained ByteQRNN and BERT (shown below). We demonstrate that the fine-tuned ByteQRNN improves the overall quality and brings its performance closer to the BERT models, despite being 300x smaller. Since SeqFlowLite models support in-training quantization that reduces model sizes by one-fourth, the resulting models scale well to low-compute devices. We chose multilingual data sources that related to the task for pre-training both BERT and byte stream models to achieve the best possible performance.
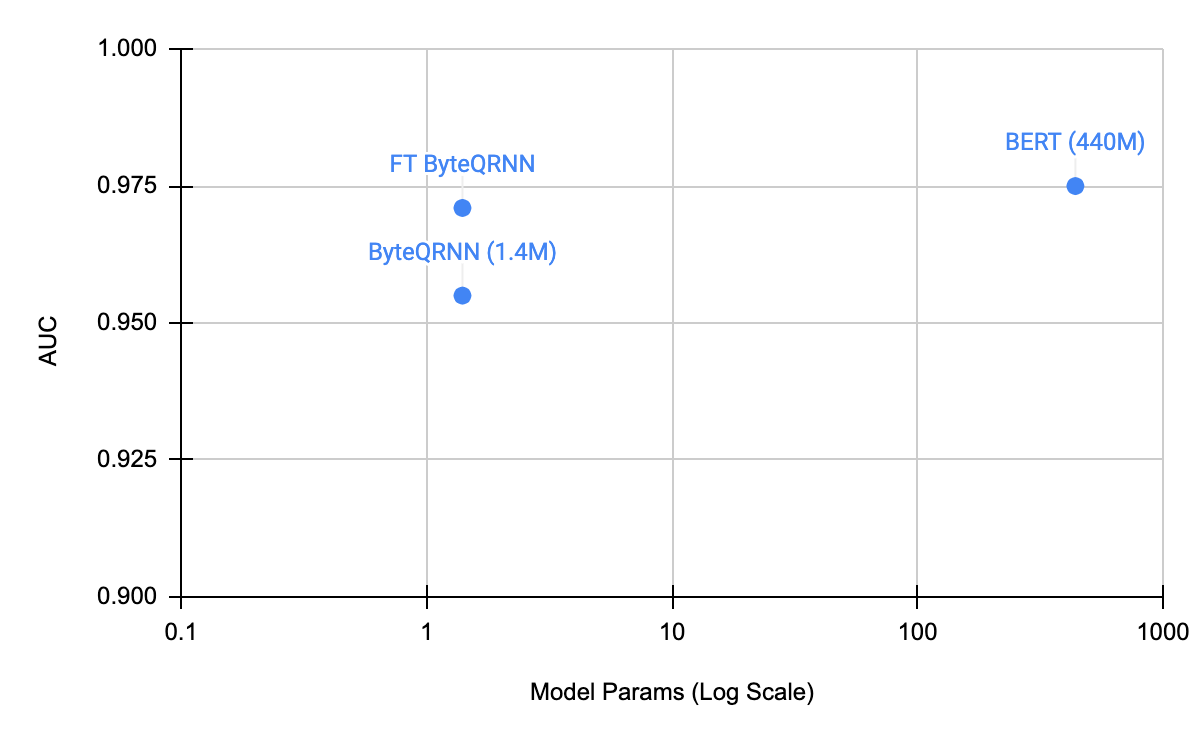 |
| Comparison of ByteQRNN with fine-tuned ByteQRNN and BERT on the civil_comments dataset. |
Conclusion
Following up on our previous work with pQRNN, we evaluate byte stream models for on-device use to enable pre-training and thereby improve model performance for on-device deployment. We present an evaluation for ByteQRNN with and without pre-training and demonstrate that the performance of the pre-trained ByteQRNN is comparable to BERT, despite being 300x smaller. In addition to ByteQRNN, we are also releasing ByteTransformer and ByteFunnelTransformer, two models which use different encoders, along with the merged attention decoder model and the beam search driver to run the inference through the SeqFlowLite library. We hope these models will provide researchers and product developers with valuable resources for future on-device deployments.
Acknowledgements
We would like to thank Khoa Trinh, Jeongwoo Ko, Peter Young and Yicheng Fan for helping with open-sourcing and evaluating the model. Thanks to Prabhu Kaliamoorthi for all the brainstorming and ideation. Thanks to Vinh Tran, Jai Gupta and Yi Tay for their help with pre-training byte stream models. Thanks to Ruoxin Sang, Haoyu Zhang, Ce Zheng, Chuanhao Zhuge and Jieying Luo for helping with the TPU training. Many thanks to Erik Vee, Ravi Kumar and the Learn2Compress leadership for sponsoring the project and their support and encouragement. Finally, we would like to thank Tom Small for the animated figure used in this post.