Have you ever wondered what goes into the design of your phone camera? How to keep your personal information secure on your mobile device? Or what it means to build a sustainable tech device?
Our new Made by Google podcast starts with questions like these to explore the latest thinking and design ideas behind Google devices.
Made by Google Podcast Trailer
As a former broadcast journalist, I’m excited to pick up my microphone again and talk to my fellow Googlers to explore the how, what and why of topics such as phone cameras, security, sustainability, smart homes and wearable devices.
The first episode, out today, asks how the phone camera went from a fairly useless feature to one of the most important tools we all rely on daily. I talk to Isaac Reynolds, a Pixel camera product manager, about the evolution of the phone camera and what he predicts for the future. Along the way, we get into selfies, geek out about video, and talk about our favourite features in the brand new Pixel 7 and Pixel 7 Pro. Isaac happens to be a professional photographer, and offers some unexpected photography insights and tips.
To listen and subscribe to future episodes, just search for Made by Google wherever you get your podcasts. New episodes will be released every week. Next time we’ll be getting the answers to questions about mobile security: Do we actually need to worry about cyber criminality? How does Google design devices to protect the people who use them? What steps do we need to take to protect ourselves?
We’re announcing our tentative 2023 release and sunset schedule for upcoming versions of the Google Ads API to bring greater clarity to your planning cycle. Please keep in mind that these dates are only estimates and may be adjusted going forward. Additionally, releases may be added, removed or switched between major and minor.
Todoist is the world’s top task and time management app, empowering over 30 million people to organize, plan, and collaborate on projects big and small. As a company, Todoist is committed to creating more fulfilling ways for its users to work and live—which includes access to its app across all devices.
That’s why Todoist developers adopted Compose for Wear OS to completely rebuild its app for wearables. This new UI toolkit gives developers the same easy-to-use suite that Android has made available for other devices, allowing for efficient, manageable app development.
A familiar toolkit optimized for Wear OS
Developers at Todoist already had experience with Jetpack Compose for Android mobile, which allowed them to quickly familiarize themselves with Compose for Wear OS. “When the new Wear design language and Compose for Wear OS were announced, we were thrilled,” said Rastislav Vaško, head of Android for Todoist. “It gave us new motivation and an opportunity to invest in the future of the platform.”
As with Jetpack Compose for mobile, developers can integrate customizable components directly from the Compose for Wear OS toolkit, allowing them to write code and implement design requirements much faster than with the View-based layouts they used previously. With the available documentation and hands-on guidance from the Compose for Wear OS codelab, they were able to translate their prior toolkit knowledge to the wearable platform.
“Compose for Wear OS had almost everything we needed to create our layouts,” said Rastislav. “Swipe-dismiss, TimeText, and ScalingLazyList were all components that worked very well out of the box for us, while still allowing us to make a recognizable and distinct app.” For features that were not yet available in the toolkit, the Todoist team used Google’s Horologist—a group of open-source libraries which provide Wear OS developers with features that are commonly required by developers but not yet available. From there, they used the Compose Layout Library to incorporate the fade away modifier that matched the native design guidelines.
Compose for Wear OS shifts development into overdrive
Compose for Wear OS simplifies UI development for Wear OS, letting engineers create complex screens that are both readable and maintainable because of its rich Kotlin syntax and modern declarative approach. This was a significant benefit for the production of the new Todoist application, enabling developers to achieve more in less time.
The central focus of the overhaul was to redesign all screens and interactions to conform with the latest Material Design for Wear OS. Using Compose for Wear OS, Todoist developers shifted away from WearableDrawerLayout in favor of a flatter app structure. This switch followed Material Design for Wear OS guidance and modernized the application’s layout.
Todoist developers designed each screen specifically for Wear OS devices, removing unnecessary elements that complicated the user experience.
“For wearables, we’re always thinking about what we can leave out, to keep only streamlined, focused, and quick interactions,” Rastislav said. Compose for Wear OS helped the Todoist team tremendously with both development and design, allowing them to introduce maintainable implementation while providing a consistent user experience.
"Since we rebuilt our app with Compose for Wear OS, Todoist’s growth rate of installations on Google Play increased by 50%."
An elevated user and developer experience
The developers at Todoist rapidly and efficiently created a refreshed application for Wear OS using Jetpack Compose. The modern tooling; intuitive APIs; and host of resources, documentation, and samples made for a smooth design and development process that required less code and accelerated the delivery of a new, functional user experience.
Since the app was revamped, the growth rate for Todoist installs on Google Play has increased 50%, and the team has received positive feedback from internal teams and on social media.
The team at Todoist is looking forward to discovering what else Compose for Wear OS can do for its application. They saw the refresh as an investment in the future of wearables and are excited for the additional opportunities and feature offerings provided by devices running Wear OS 3.
Transform your app with Compose for Wear OS
Todoist completely rebuilt and redesigned its Wear OS application with Compose for Wear OS, improving both the user and developer experience.
The Beta channel has been updated to 107.0.5304.29 for Windows,Mac and Linux.
A full list of changes in this build is available in the log. Interested in switching release channels? Find out how here. If you find a new issues, please let us know by filing a bug. The community help forum is also a great place to reach out for help or learn about common issues.
Posted by Zalán Borsos, Research Software Engineer, and Neil Zeghidour, Research Scientist, Google Research
Generating realistic audio requires modeling information represented at different scales. For example, just as music builds complex musical phrases from individual notes, speech combines temporally local structures, such as phonemes or syllables, into words and sentences. Creating well-structured and coherent audio sequences at all these scales is a challenge that has been addressed by coupling audio with transcriptions that can guide the generative process, be it text transcripts for speech synthesis or MIDI representations for piano. However, this approach breaks when trying to model untranscribed aspects of audio, such as speaker characteristics necessary to help people with speech impairments recover their voice, or stylistic components of a piano performance.
In “AudioLM: a Language Modeling Approach to Audio Generation”, we propose a new framework for audio generation that learns to generate realistic speech and piano music by listening to audio only. Audio generated by AudioLM demonstrates long-term consistency (e.g., syntax in speech, melody in music) and high fidelity, outperforming previous systems and pushing the frontiers of audio generation with applications in speech synthesis or computer-assisted music. Following our AI Principles, we've also developed a model to identify synthetic audio generated by AudioLM.
From Text to Audio Language Models In recent years, language models trained on very large text corpora have demonstrated their exceptional generative abilities, from open-ended dialogue to machine translation or even common-sense reasoning. They have further shown their capacity to model other signals than texts, such as natural images. The key intuition behind AudioLM is to leverage such advances in language modeling to generate audio without being trained on annotated data.
However, some challenges need to be addressed when moving from text language models to audio language models. First, one must cope with the fact that the data rate for audio is significantly higher, thus leading to much longer sequences — while a written sentence can be represented by a few dozen characters, its audio waveform typically contains hundreds of thousands of values. Second, there is a one-to-many relationship between text and audio. This means that the same sentence can be rendered by different speakers with different speaking styles, emotional content and recording conditions.
To overcome both challenges, AudioLM leverages two kinds of audio tokens. First, semantic tokens are extracted from w2v-BERT, a self-supervised audio model. These tokens capture both local dependencies (e.g., phonetics in speech, local melody in piano music) and global long-term structure (e.g., language syntax and semantic content in speech, harmony and rhythm in piano music), while heavily downsampling the audio signal to allow for modeling long sequences.
However, audio reconstructed from these tokens demonstrates poor fidelity. To overcome this limitation, in addition to semantic tokens, we rely on acoustic tokens produced by a SoundStream neural codec, which capture the details of the audio waveform (such as speaker characteristics or recording conditions) and allow for high-quality synthesis. Training a system to generate both semantic and acoustic tokens leads simultaneously to high audio quality and long-term consistency.
Training an Audio-Only Language Model AudioLM is a pure audio model that is trained without any text or symbolic representation of music. AudioLM models an audio sequence hierarchically, from semantic tokens up to fine acoustic tokens, by chaining several Transformer models, one for each stage. Each stage is trained for the next token prediction based on past tokens, as one would train a text language model. The first stage performs this task on semantic tokens to model the high-level structure of the audio sequence.
In the second stage, we concatenate the entire semantic token sequence, along with the past coarse acoustic tokens, and feed both as conditioning to the coarse acoustic model, which then predicts the future tokens. This step models acoustic properties such as speaker characteristics in speech or timbre in music.
In the third stage, we process the coarse acoustic tokens with the fine acoustic model, which adds even more detail to the final audio. Finally, we feed acoustic tokens to the SoundStream decoder to reconstruct a waveform.
After training, one can condition AudioLM on a few seconds of audio, which enables it to generate consistent continuation. In order to showcase the general applicability of the AudioLM framework, we consider two tasks from different audio domains:
Speech continuation, where the model is expected to retain the speaker characteristics, prosody and recording conditions of the prompt while producing new content that is syntactically correct and semantically consistent.
Piano continuation, where the model is expected to generate piano music that is coherent with the prompt in terms of melody, harmony and rhythm.
In the video below, you can listen to examples where the model is asked to continue either speech or music and generate new content that was not seen during training. As you listen, note that everything you hear after the gray vertical line was generated by AudioLM and that the model has never seen any text or musical transcription, but rather just learned from raw audio. We release more samples on this webpage.
To validate our results, we asked human raters to listen to short audio clips and decide whether it is an original recording of human speech or a synthetic continuation generated by AudioLM. Based on the ratings collected, we observed a 51.2% success rate, which is not statistically significantly different from the 50% success rate achieved when assigning labels at random. This means that speech generated by AudioLM is hard to distinguish from real speech for the average listener.
Our work on AudioLM is for research purposes and we have no plans to release it more broadly at this time. In alignment with our AI Principles, we sought to understand and mitigate the possibility that people could misinterpret the short speech samples synthesized by AudioLM as real speech. For this purpose, we trained a classifier that can detect synthetic speech generated by AudioLM with very high accuracy (98.6%). This shows that despite being (almost) indistinguishable to some listeners, continuations generated by AudioLM are very easy to detect with a simple audio classifier. This is a crucial first step to help protect against the potential misuse of AudioLM, with future efforts potentially exploring technologies such as audio “watermarking”.
Conclusion We introduce AudioLM, a language modeling approach to audio generation that provides both long-term coherence and high audio quality. Experiments on speech generation show not only that AudioLM can generate syntactically and semantically coherent speech without any text, but also that continuations produced by the model are almost indistinguishable from real speech by humans. Moreover, AudioLM goes well beyond speech and can model arbitrary audio signals such as piano music. This encourages the future extensions to other types of audio (e.g., multilingual speech, polyphonic music, and audio events) as well as integrating AudioLM into an encoder-decoder framework for conditioned tasks such as text-to-speech or speech-to-speech translation.
Acknowledgments The work described here was authored by Zalán Borsos, Raphaël Marinier, Damien Vincent, Eugene Kharitonov, Olivier Pietquin, Matt Sharifi, Olivier Teboul, David Grangier, Marco Tagliasacchi and Neil Zeghidour. We are grateful for all discussions and feedback on this work that we received from our colleagues at Google.
We recently announced that Top content bid adjustments are no longer available for any campaigns. To align with this change, Google Ads API will make the following changes starting November 1, 2022.
If you need to retrieve the existing values for these fields for future reference, we recommend that you download these values before November 1, 2022.
If you have any questions or need additional help, contact us using any of the following support options:
The internet has been around for quite a while now, but, like any technology, it continues to grow and evolve. In recent years, the industry has seen huge strides in both internet speed and reliability. These innovations are necessary to support the increasing complexity of online technology, including new ways of delivering the internet like fiber optics, satellite, wireless, and others.
Google Fiber’s fiber optic network allows us to stay on the cutting edge of internet technology and advancements — it’s the reason why we’re so able to quickly upgrade our networks and provide faster and more reliable service. How does it allow us to be so nimble?
What is fiber optic internet?
In the last post of our Fast Forward series, Tom talked about how traditional cable internet was built on copper wires which was originally intended to transmit television broadcasts, whereas fiber optic internet is a series of ultra-thin glass tubes that transmits data at the speed of light.
Part of what makes fiber optic internet unique is its ability to be quickly upgraded in order to accommodate for new technological advancements and the needs of evolving tech in everyday households. When we need to upgrade our network to accommodate increased speed, we don’t have to change the fiber lines in the ground.
So what needs to be upgraded to make the internet faster?
While we don’t have to change out the fiber optics every time an advancement in speed is made, we do have to swap out the technology in our huts that deliver the “last mile” (i.e. the distance that connects your home or business to the central infrastructure of the internet). We house our equipment in huts and cabinets throughout each metro area. This includes tech like our Passive Optical Networks (PONs).
PONs use fiber optic lines to provide Ethernet connectivity from a main data source to endpoints, like your home network. At Google Fiber, we currently use what is referred to as a GPON in most of our huts. The GPON allows us to offer up to two gigabits download speed and up to one gigabit upload speed to our customers (the “G” in “GPON” stands for “gigabit”). When we started building our network, this was new technology.
But technology rarely stays the “latest” for long. The internet is ready to take its next step, and with that progress comes XGS-PON (x = roman numeral 10, g = gPON, s = symmetrical). Each XGS-PON can provide 64 households with up to 10 gigabit upload and download speeds (yep, symmetrical!). That means in order for us to upgrade our network speeds, we don’t have to go underground or completely rearrange our network, but we do have to switch out our GPON gear for XGS-PON in every hut (like we did in the picture below to start testing this in Kansas City).
What we’re doing now
As you can see, we’re already working behind the scenes to build a network that can stay ahead of demand, both as our speed offerings and as demand for internet bandwidth and speed increases because of new technology, more users and new devices come online. We’re constantly monitoring and planning many months ahead to predict and adapt to the changes in demand on our networks.
When a lot of people were working, going to school, and doing everything else over the internet from home during the height of the pandemic, internet services needed to adjust. Because we actively monitor our networks for these types of changes (rather than only reacting when things go bad), we actively adjusted our network to meet the new demand of users before you even knew you needed it (read more about that here).
And we’re continuing that proactive approach, even as the world gets “back to the new normal.” Our newest cities are being built with the ability to accommodate the ever increasing speed demands, and we’re updating our networks in all our cities to be able to accelerate as technology continues to evolve. We’re proud to build our networks with the future in mind and a team dedicated to improving our customers’ experience every day.
Posted by Scott Li, Network Engineering Manager, and Jennifer Poscic, Network Acquisition & Service Delivery Manager
To improve build speed and provide stable APIs, the Transform APIs will be removed in Android Gradle plugin (AGP) version 8.0. Most use cases have replacement APIs which are available starting from AGP version 7.2. Read on for more details.
The Android developer community's top request has been to improve build speed while making sure Android Gradle plugin (AGP) has a solid, stable, and well supported API.
To improve build speed starting from AGP 7.2, we have stabilized the Artifacts API and updated the Instrumentation API. For common use cases, these APIs replace the Transform APIs, which cause longer build times and are gone in AGP 8.0.
This article walks you through transitioning off the Transform APIs, whether you're working on a Gradle plugin or an application.
Guidance for Gradle plugins
To improve build times, we split Transform's functionality into the following APIs that are optimized for common use cases:
The Instrumentation API lets you transform and analyze compiled app classes using ASM callbacks. For example use this API to add custom traces to methods or classes for additional or custom logging.
The Artifacts API gives access to files or directories, whether temporary or final, that are produced by AGP during the build. Use this API to:
Add additional generated classes to the app,such as glue code for dependency injection.
Implement transformations based on whole program analysis, when all classes can be transformed together in a single task. This is only available starting from AGP 7.4.0-alpha06. The build.gradle.kts file in the “modifyProjectClasses'' Gradle recipe shows how to do it.
Make sure that you update your plugins to be AGP 8.0 compliant before updating your app to AGP 8.0. If the relevant plugins are not compliant, please create a bug that includes a link to this post and send it to the plugin authors.
Several commonly used plugins have already migrated to use these new APIs, including the Hilt Gradle plugin.
Share your feedback
If your use case is not covered by any of the new APIs, please file a bug.
We encourage you to get started with making your plugins compatible with the new AGP APIs. Getting started now means that you have enough time to familiarize yourself with the APIs, share your feedback and then upgrade your dependencies and plugins.
Posted by Jeana Jorgensen, Senior Director, Cloud Product Marketing and Sustainability, Google
Google Cloud Next is coming up on October 11 - 13. Register at no cost today and join us live to explore what’s new and what’s coming next in Google Cloud.
You’ll find lots of developer-specific content in the Developer Zone. Here’s a preview of what we’ve curated for you this year.
A developer keynote to get you thinking about the future
For the Next developer keynote we’re going to share our top 10 cloud technology predictions that we believe could come true by the end of 2025.
Hear from our experts who are on the cutting edge of many of these technology trends, whether it's AI, data and analytics, or modern cloud infrastructure:
Jeanine Banks, VP of Developer Products and Community
Erik Brewer, VP of Infrastructure and Google Fellow
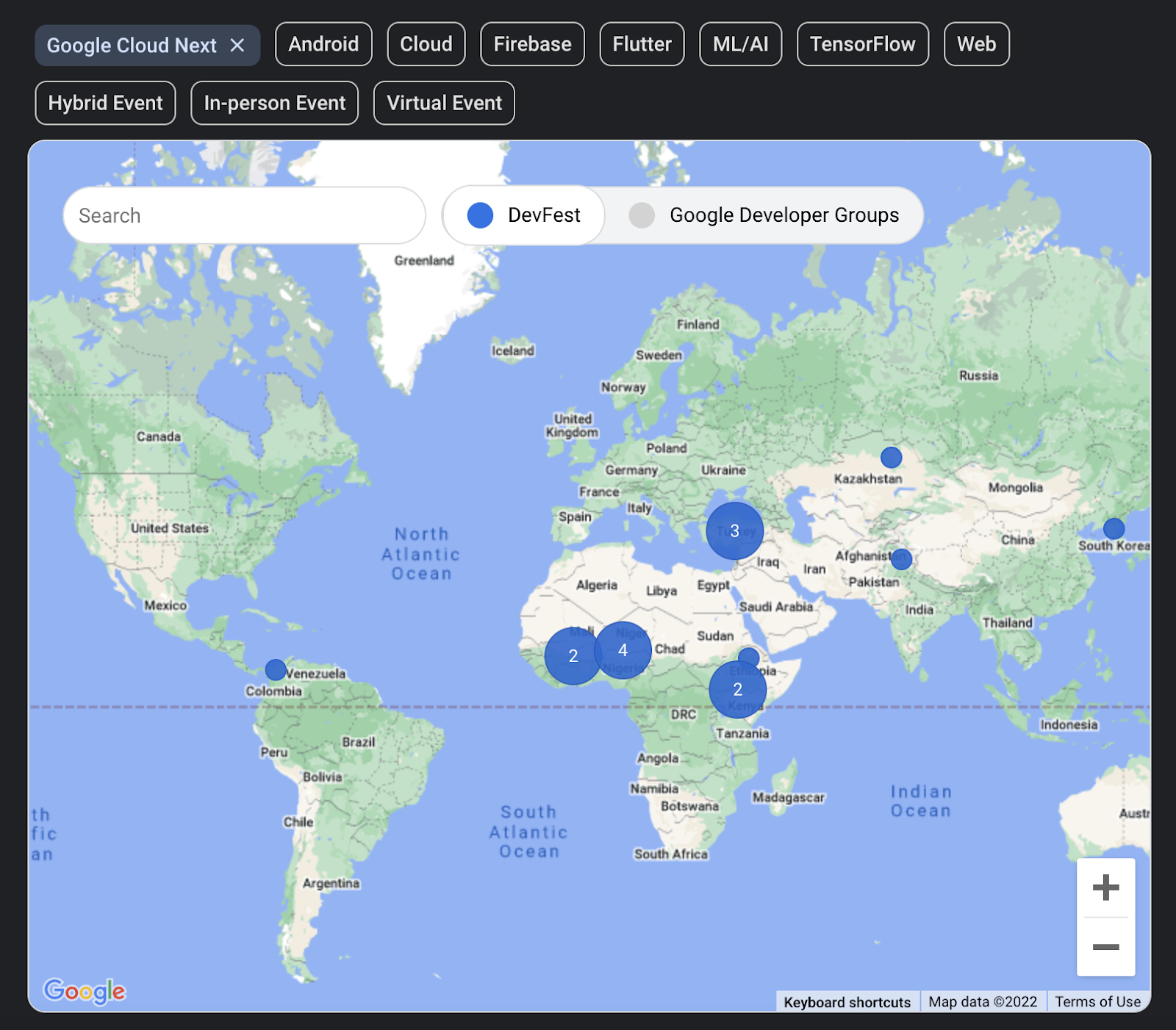
DevFests are local tech conferences hosted by Google Developer Groups around the world during Next ‘22. The content of each one will vary to suit the local developer community. You might find hands-on labs, technical talks, or simply a chance to connect.
To find a DevFest near you, visit the DevFest page and filter the map by Google Cloud Next. You can RSVP via the map interface. Quick side tip…this is separate from Next registration.
In the challenge, you can use Drone Racing League (DRL) race data and Google Cloud analytics tools to predict race outcomes and then provide tips to DRL pilots to help enhance their season performance. Compete for the chance to win a trip to the season finale of the 2022-23 DRL Algorand World Championship and be celebrated on stage.
Google Clout Challenge
Spice up the middle of your week with a no-cost, 20-minute competition posted each Wednesday until October 10. All challenges will take place in Google Cloud Skills Boost. And as a new user, you can get 30 days of no-cost access to Google Cloud Skills Boost* – plenty of time to complete the whole challenge.
Test your knowledge against your fellow developers and race the clock to see how fast you can complete the challenge. The faster you go, the higher your score.
Can you top your last score?
To participate, follow these three steps:
Enroll - Go to our website, click the link to the weekly challenge, and enroll in the quest using your Google Cloud Skills Boost account.
Play - Attempt the challenge as many times as you want. Remember the faster you are, the higher your score!
Share - Share your score card on Twitter/LinkedIn using #GoogleClout
Win - Complete all 10 weekly challenges to earn exclusive #GoogleClout badges
*Requires credit card
Innovator Hive livestreams to get the latest tech news
Innovator Hive livestreams are your unique opportunity to hear from Google Cloud executives and engineers as we announce the latest innovations. Join any livestream to explore technical content featuring new Google Cloud technologies.
Save your seat at Next
We at Google are getting excited for Next ‘22. It’s this year’s big moment to dive into the latest innovations, hear from Google experts, get inspired by what your peers are doing with technology, and try out some new skills.
There’s so much good stuff lined up – all we’re missing at this point is some #GoogleClout badge boasting, drone stat analyzing, technology-minded people to geek out with. Register for Next ‘22 today and join the fun live in October.
As digital advertising changes, it's essential for advertisers to stay ahead of the curve while meeting people's expectations. Consumers want privacy but they also want relevant ads. In fact, 62% of consumers in the US consider it important to have a personalized experience with a brand.[96be74]We don’t believe this should be rocket science for programmatic advertisers. This is why we are building simple, off-the-shelf solutions in Display & Video 360 with first-party data and machine learning. We’re announcing two of these solutions today, optimized targeting and Exchange Provided Identifiers.
Optimized targeting helps advertisers expand reach across relevant audiences and increase return on investment with the touch of just a button. Exchange Provided Identifier, also known as EPID, provides Display & Video 360 with new signals which will be used to automatically future-proof frequency management tools. In the future, EPIDs will be powering a variety of other marketing use cases in Display & Video 360 with no action required by advertisers.
Programmatic buys automatically powered with publishers’ data
Advertisers increasingly rely on publishers' first-party data to enrich their marketing strategies. That’s why we’re evolving our programmatic technology to organically inform Display & Video 360 solutions with those valuable signals.
You may be familiar with Publisher Provided Identifiers, also known as PPIDs, which became available for publishers to use programmatically last year. PPID allows publishers to send Google Ad Manager a first-party identifier for marketing use-cases. EPID expands on this technology. It makes it available to more exchanges, publishers, or vendors looking to share their first-party identifiers with Display & Video 360’s backend to improve the quality of programmatic ads served on their respective properties. EPIDs from a given exchange or publisher cannot be used to inform marketing strategies outside of that publisher’s inventory. This protects people from being tracked across the web.
Earlier this year, we started testing this feature and receiving EPIDs from several publishers and exchanges, including Magnite. Based on partner feedback, we began improving this feature. We’re excited to grow our list of partners and progressively enhance advertisers’ programmatic campaigns with these new durable signals.
In the coming months, EPID will be used to inform Display & Video 360 users’ frequency management solutions. This will ensure brands can continue avoiding ad repetition while maximizing reach efficiency even when third-party cookies go away. Advertisers won’t have to make any changes in their account since EPIDs will be organically embedded in Display & Video’s technology. Brands and agencies will automatically benefit from EPID when setting frequency goals.
In the near future, EPID will be used as a signal for building Google audience segments in Display & Video 360. This will give advertisers a chance to deliver more personalized ads on publishers’ sites for which EPIDs are received. Down the line, EPID will also help brands unlock other core advertising functionalities, like cross-device reach on a domain by domain basis, and invalid traffic prevention in a privacy-safe way.
Expand reach across audiences more easily
Reaching the right people with a message is one thing. But to be successful, advertisers have to reach enough of these people and scale their audience strategy. This is where machine learning and optimized targeting come in.
Optimized targeting lets advertisers find new and relevant customers likely to convert within their campaign goals. Campaign settings, such as manually-selected audiences including first-party data and Google audiences, influence the machine learning algorithm. Optimized targeting then uses machine learning to expand reach across other relevant groups without relying on third-party cookies.
Because it uses the same goals as our automated and custom bidding solutions, optimized targeting reaches people most likely to drive impressions, clicks, or conversions as defined and customized by the advertiser to drive business outcomes. This ultimately leads to better performance and increased conversions. In our early tests, we found that advertisers who use optimized targeting in Display & Video 360 can see, on average, a 25% improvement in their campaign objectives when using Google audiences and can see, on average, a 55% improvement when using first-party data.[4f8fcc]
In Display & Video 360, optimized targeting is currently available for YouTube Video Action campaigns and will expand beyond YouTube to all display and video campaigns in the coming months. Once launched, new eligible display and video campaigns will be opted into optimized targeting with the ability to opt out.
We are continuing to create Display & Video 360 solutions that will allow marketers to successfully reach and influence their most relevant audiences, while ensuring consumers feel safe online. EPID and optimized targeting are two of many new audience tools and features we are building for programmatic buyers.