With February coming to a close, we’re back with another issue of our Stadia Savepoint series, giving you a summary of recent news on Stadia.
This month we announced nine new games coming to Stadia, featuring three games launching First on Stadia. That included “Spitlings,” the chaotic multi-player platformer which launched earlier this week and is the focus of our first developer Q&A with Massive Miniteam.
Stadia on Samsung, ASUS, and Razer phones.
Expanded Android support
We’ve added Stadia compatibility to 19 new phones from Samsung, ASUS, and Razer, bringing the ability to play our entire library across tens of millions of devices. See here for more info.
New games coming to Stadia
SteamWorld Dig
SteamWorld Dig 2
SteamWorld Heist
SteamWorld Quest
Lost Words: Beyond the Page
Panzer Dragoon: Remake
Serious Sam Collection
Stacks on Stacks (on Stacks)
The Division 2
Doom Eternal
Recent content launches on Stadia
Spitlings
Monster Energy Supercross - The Official Videogame 3
Borderlands 3 - Moxxi's Heist of the Handsome Jackpot
Metro Exodus - Sam’s Story
Mortal Kombat 11 - The Joker
Mortal Kombat 11 - DC Elseworlds Skin Pack
Stadia Pro updates
New games are free to active Stadia Pro subscribers in March: GRID, SteamWorld Dig 2, and SteamWorld Quest.
Existing games still available to add to your collection: Destiny 2, Farming Simulator 19 Platinum Edition, Gylt, Metro Exodus and Thumper.
Act quickly: Farming Simulator 19 Platinum Edition leaves Stadia Pro on February 29.
Ongoing discounts for Stadia Pro subscribers: Check out the web or mobile Stadia store for the latest.
That’s it for February, we’ll be back soon to share more updates. As always, stay tuned to the Stadia Community Blog, Facebook, and Twitter for the latest news.
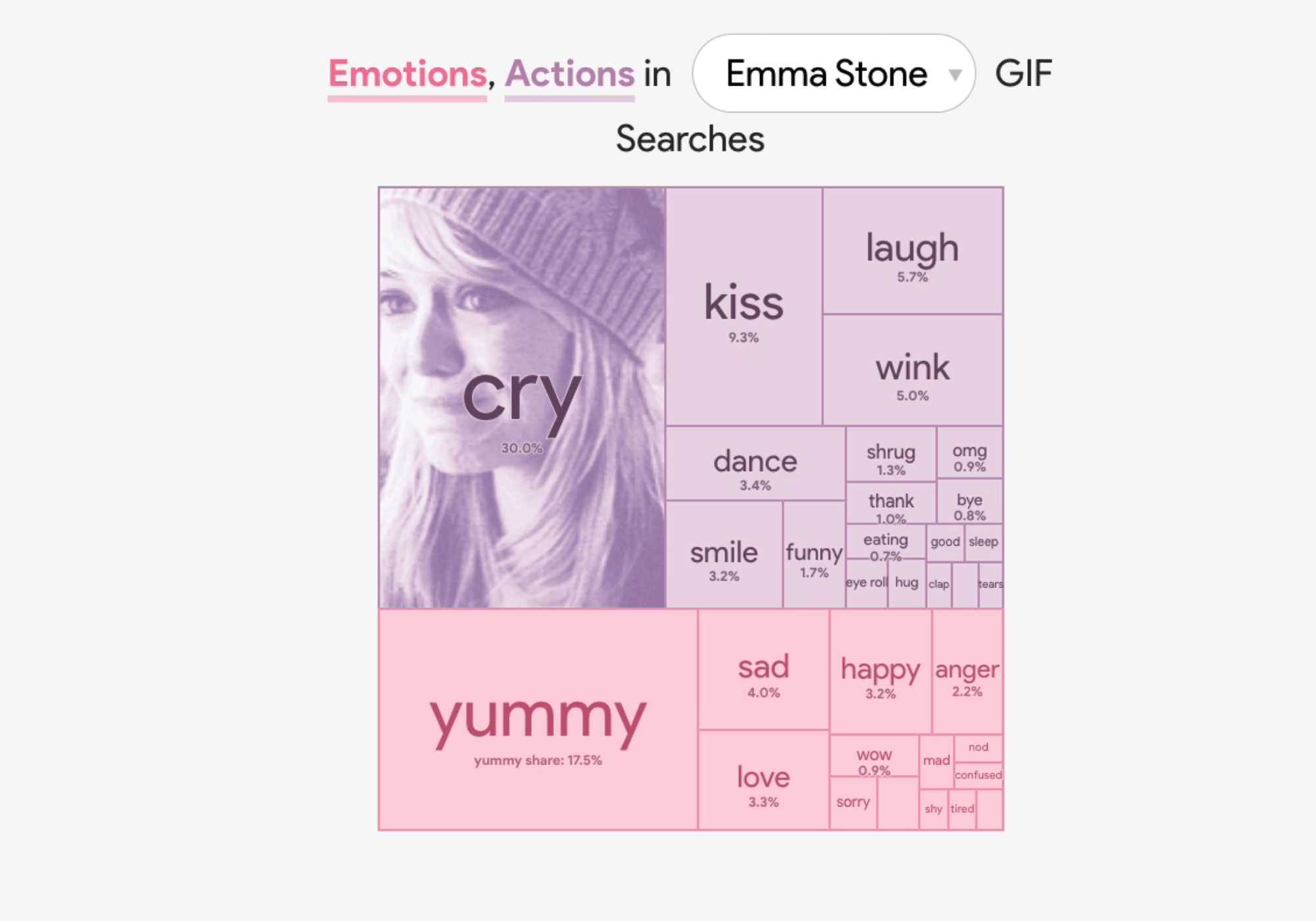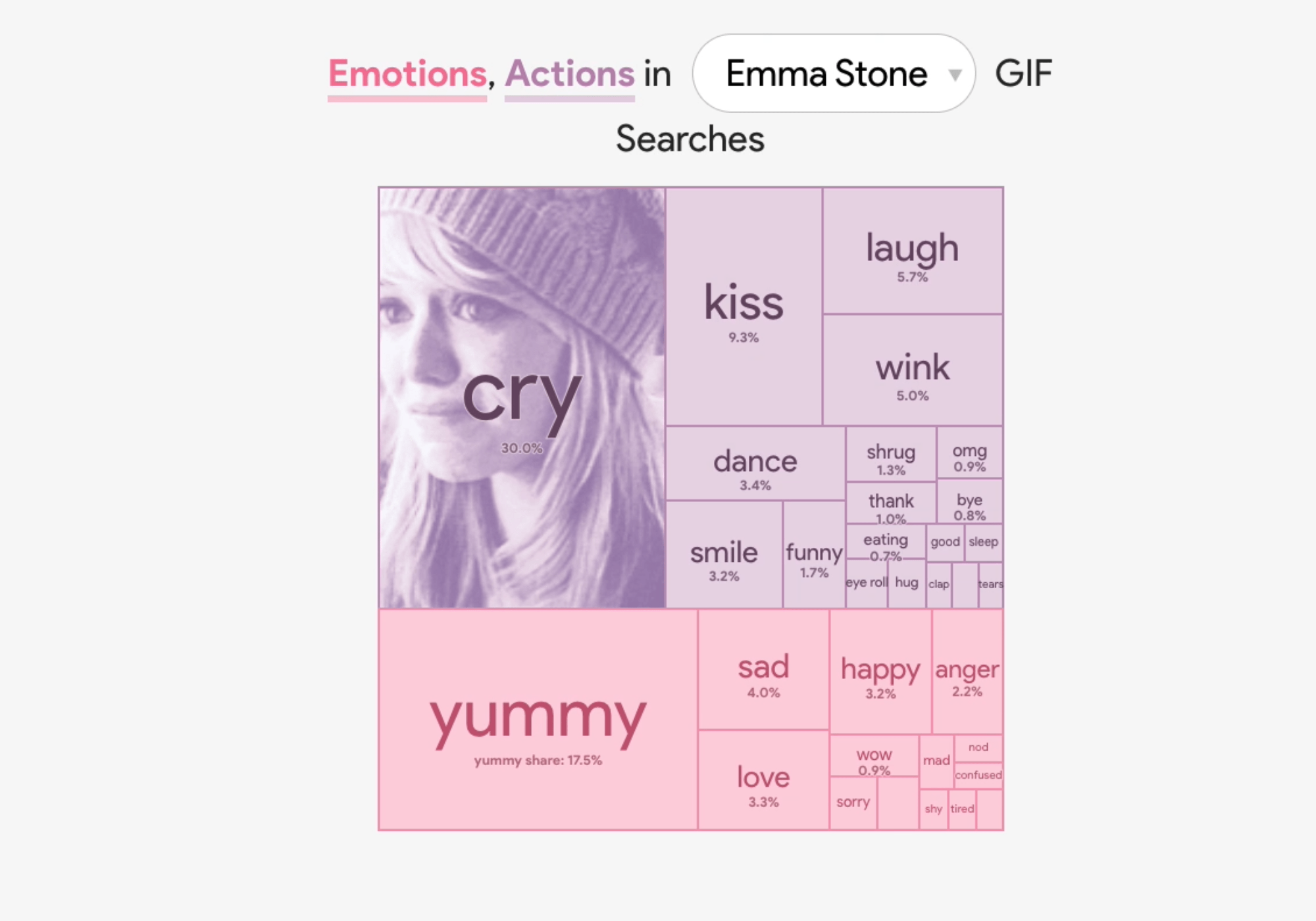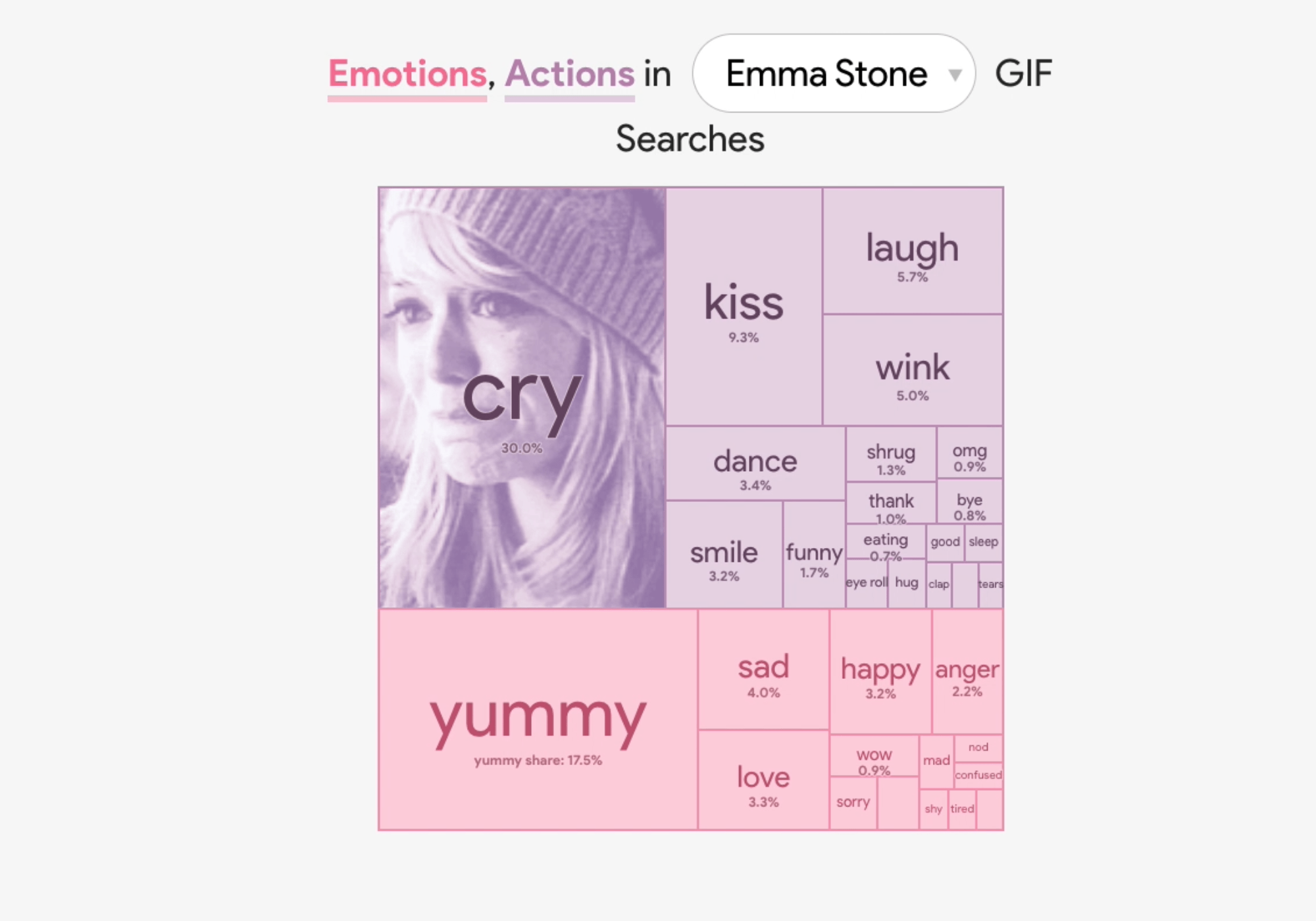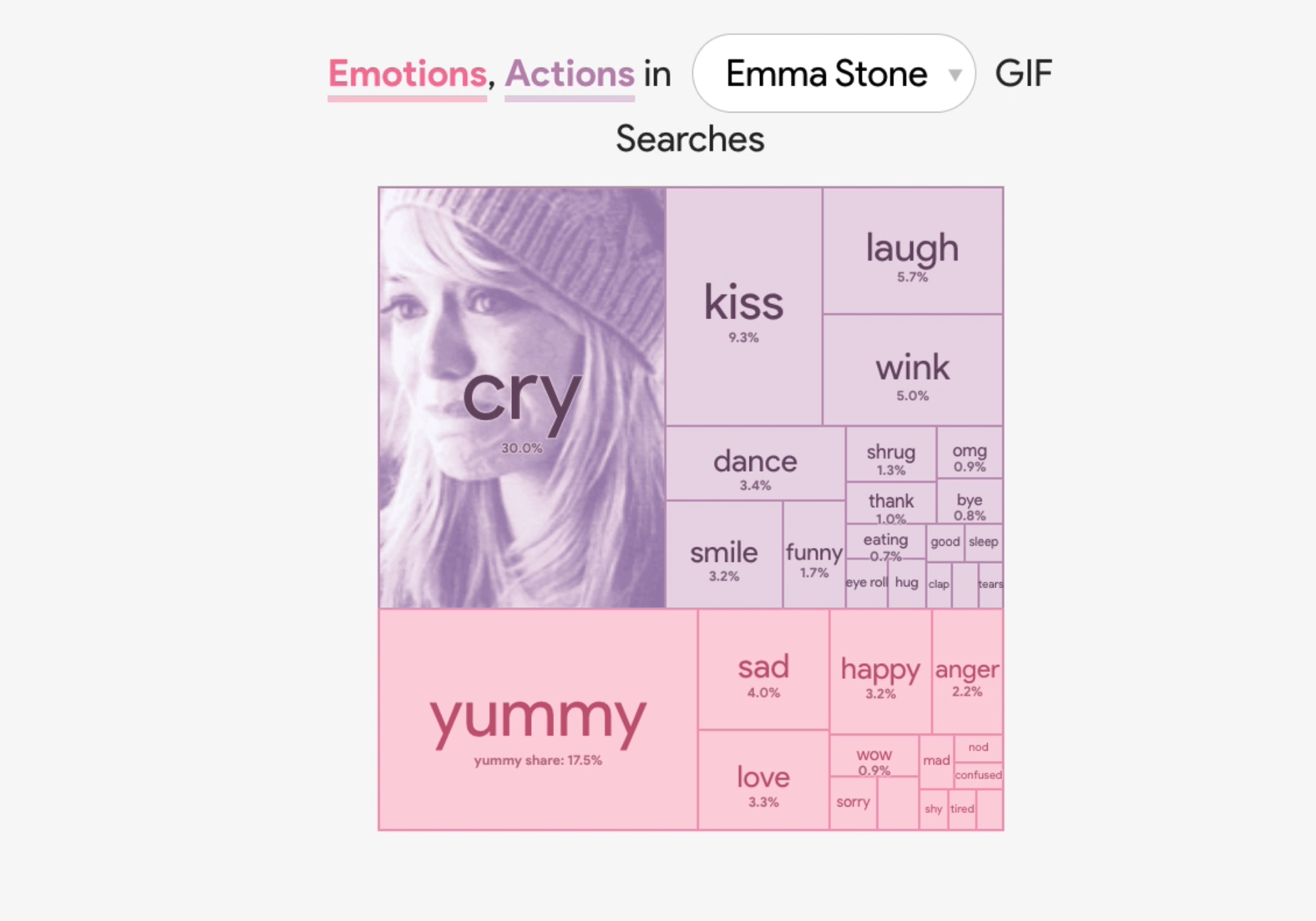
In an age when people talk all day on text and email, we’ve come to rely on the art of the GIF to convey our emotions. To recognize life’s most joyous moments—or to navigate the tricky ones—we search for the perfect GIF and hit send.
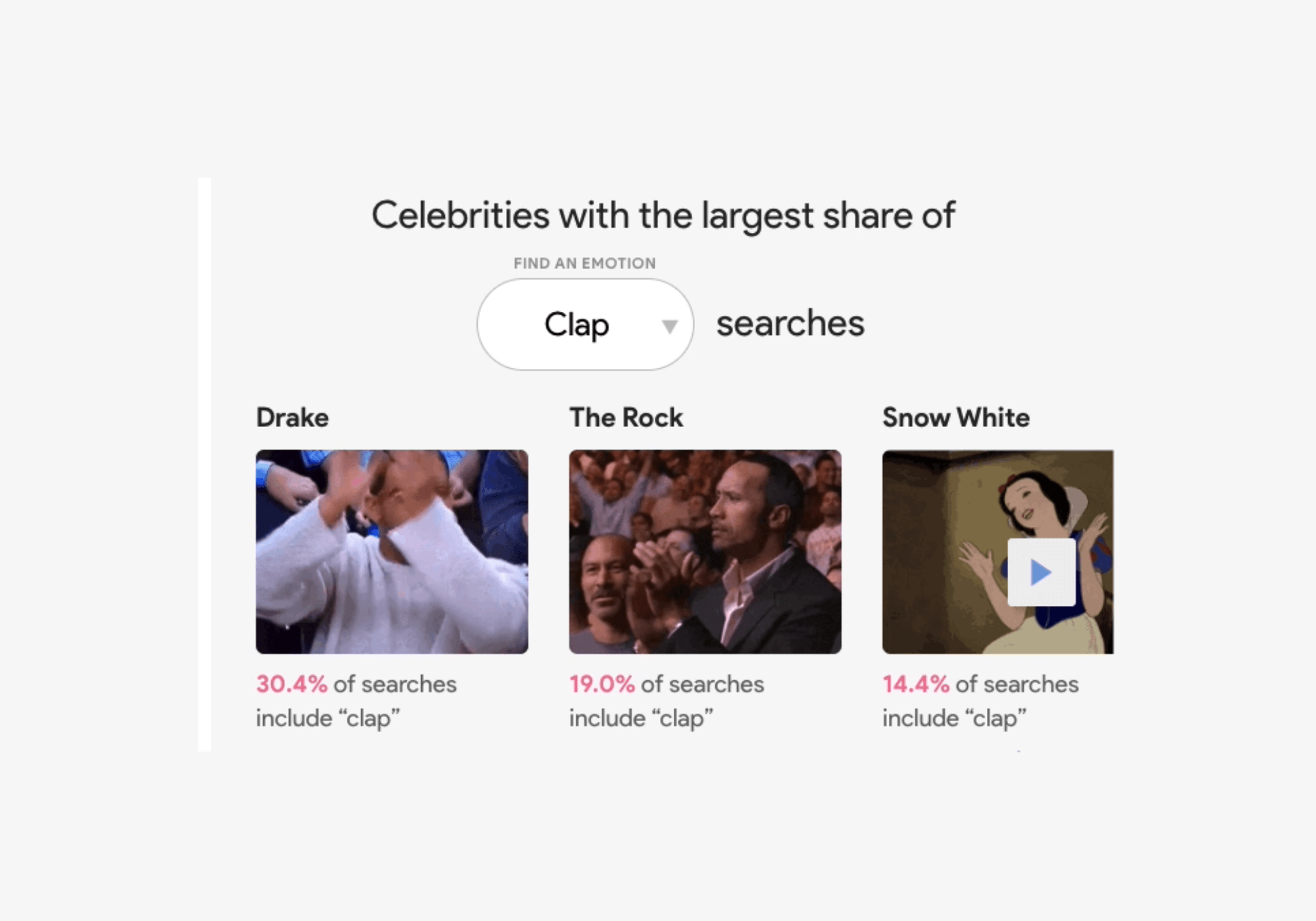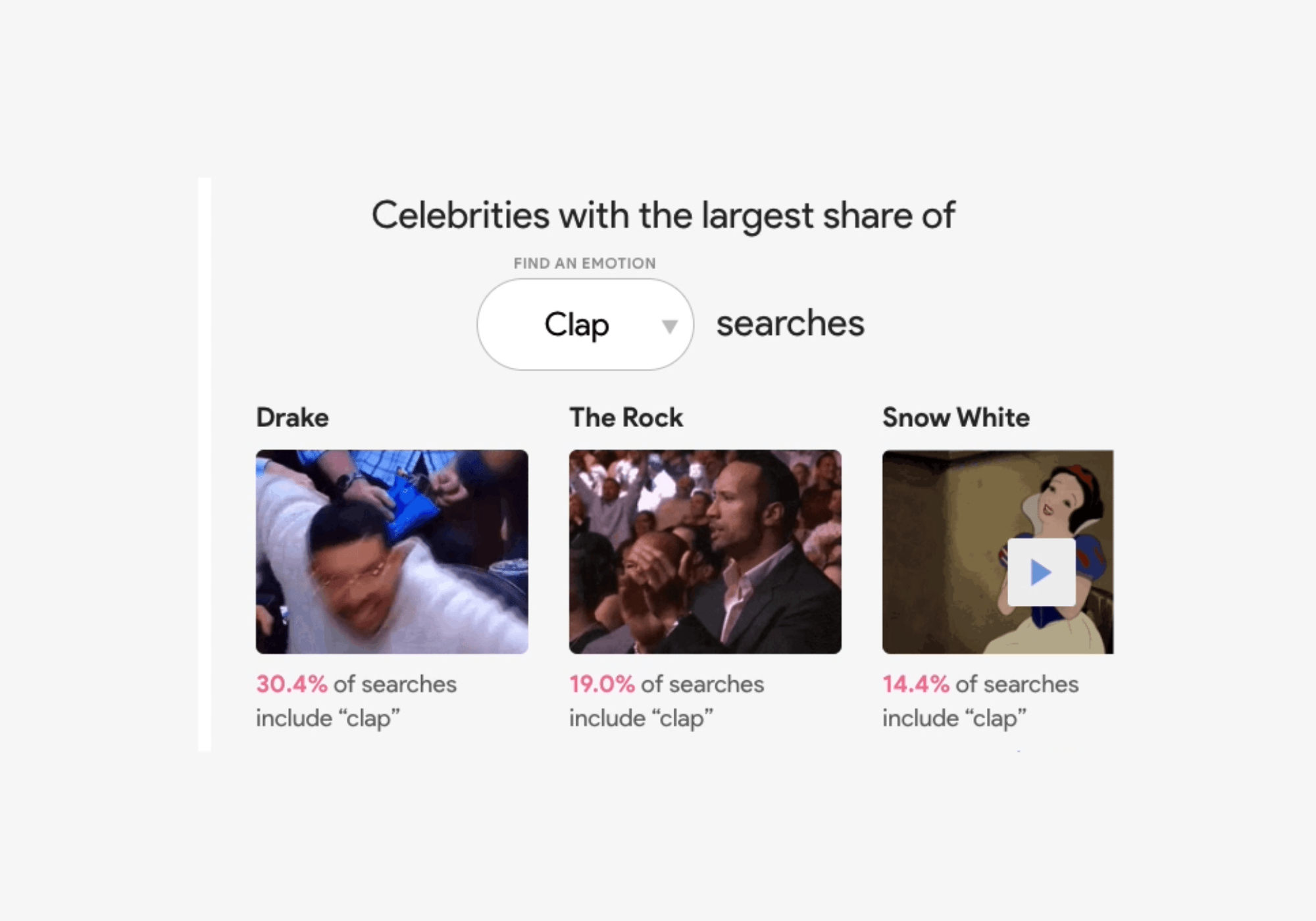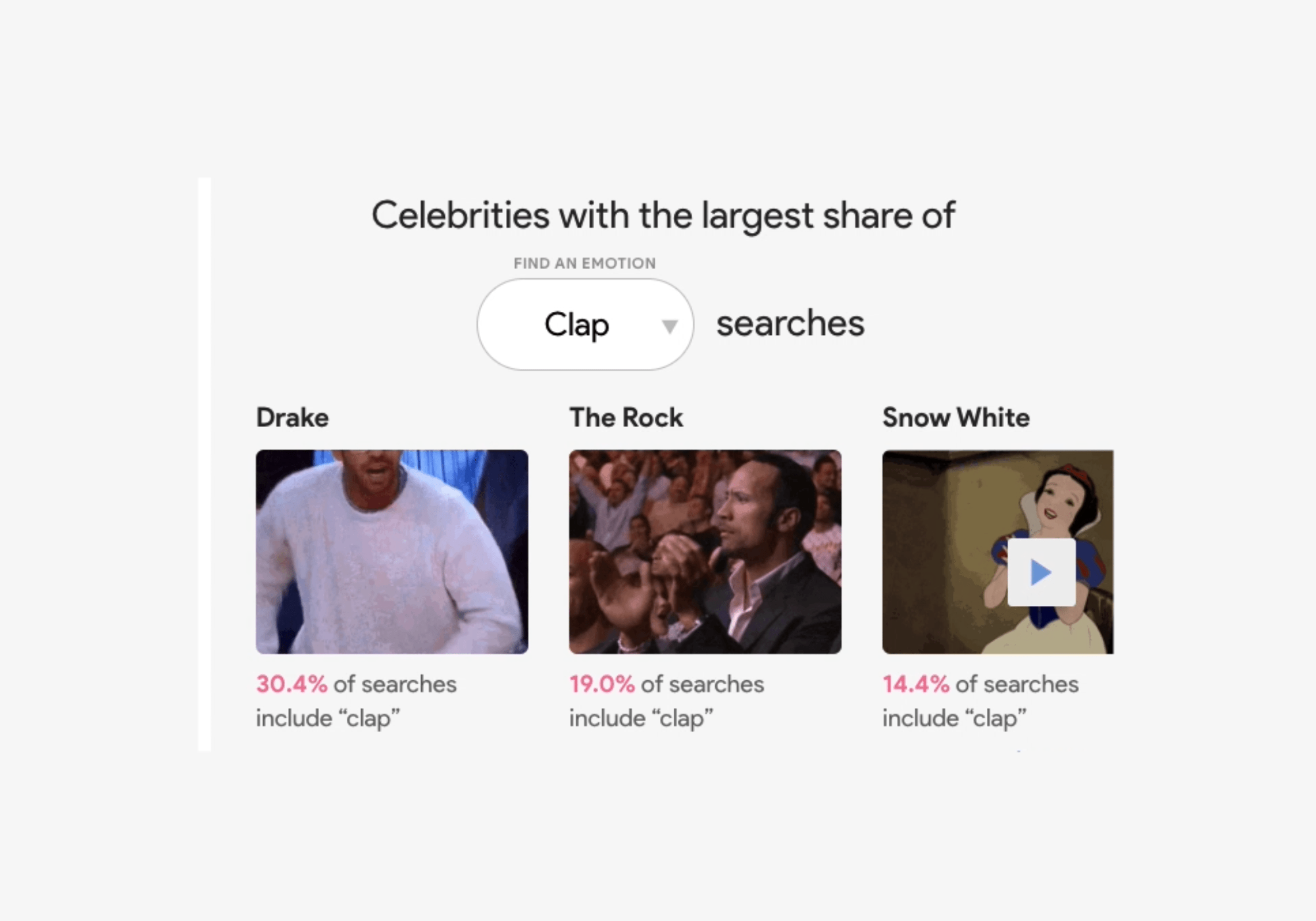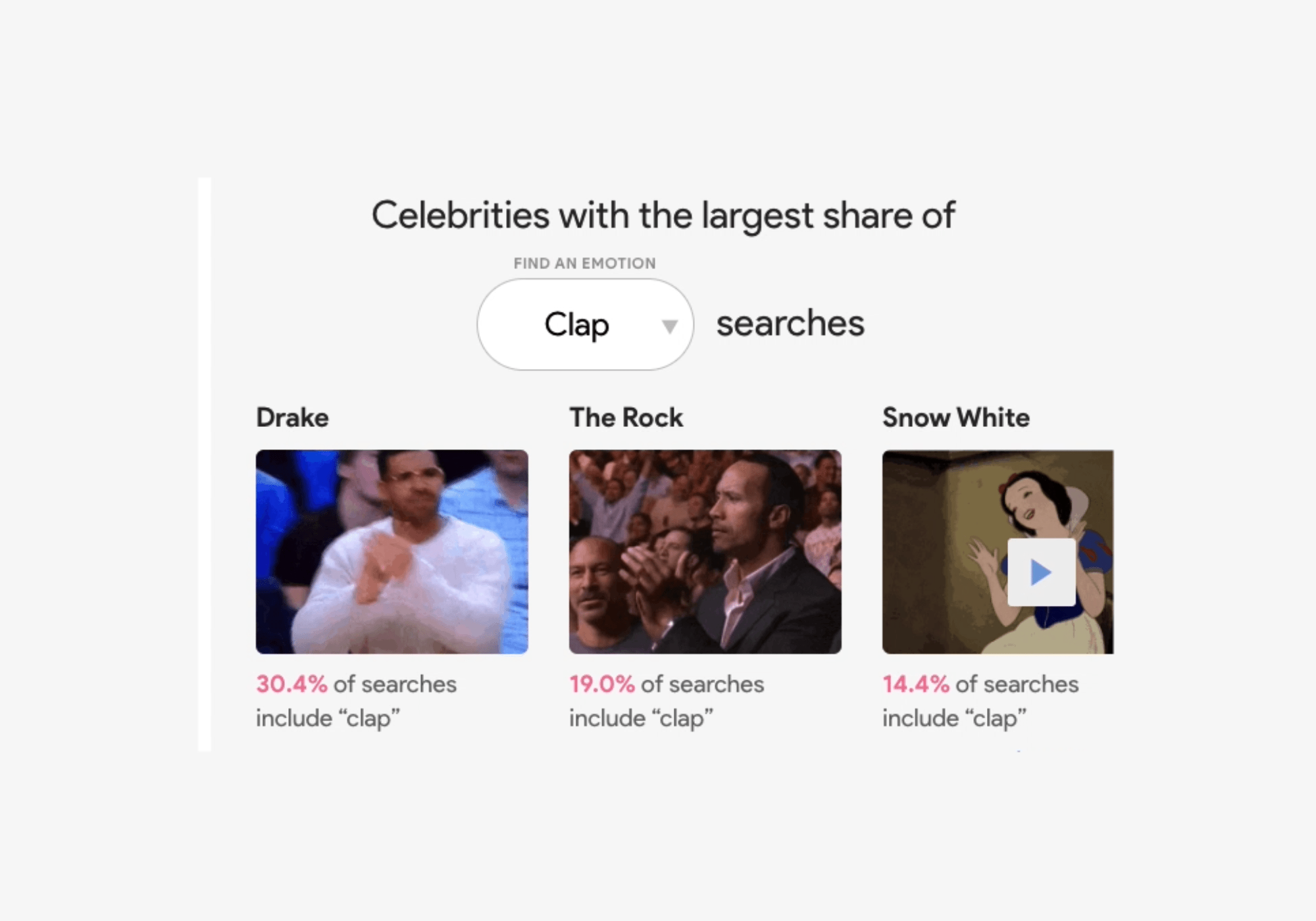
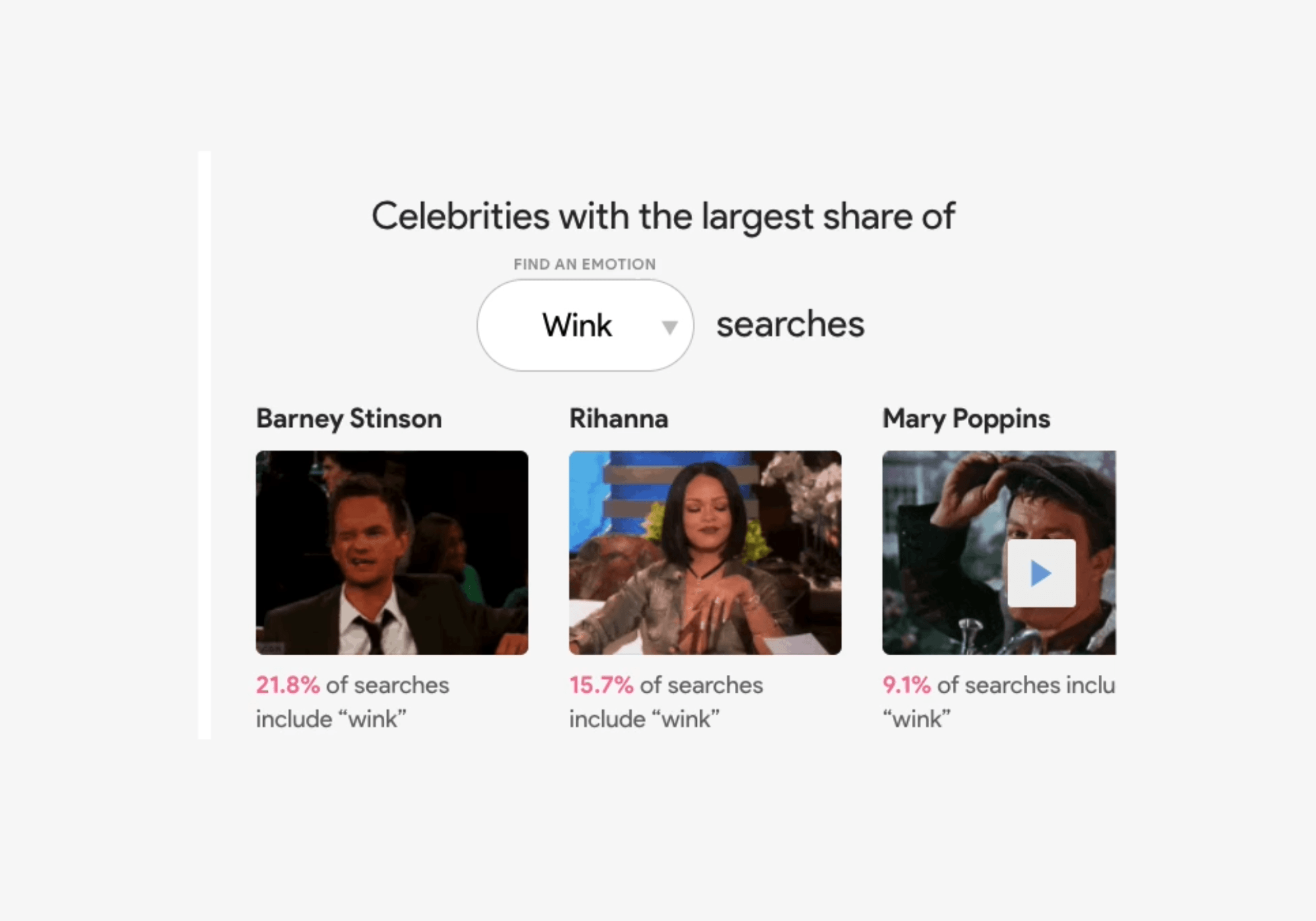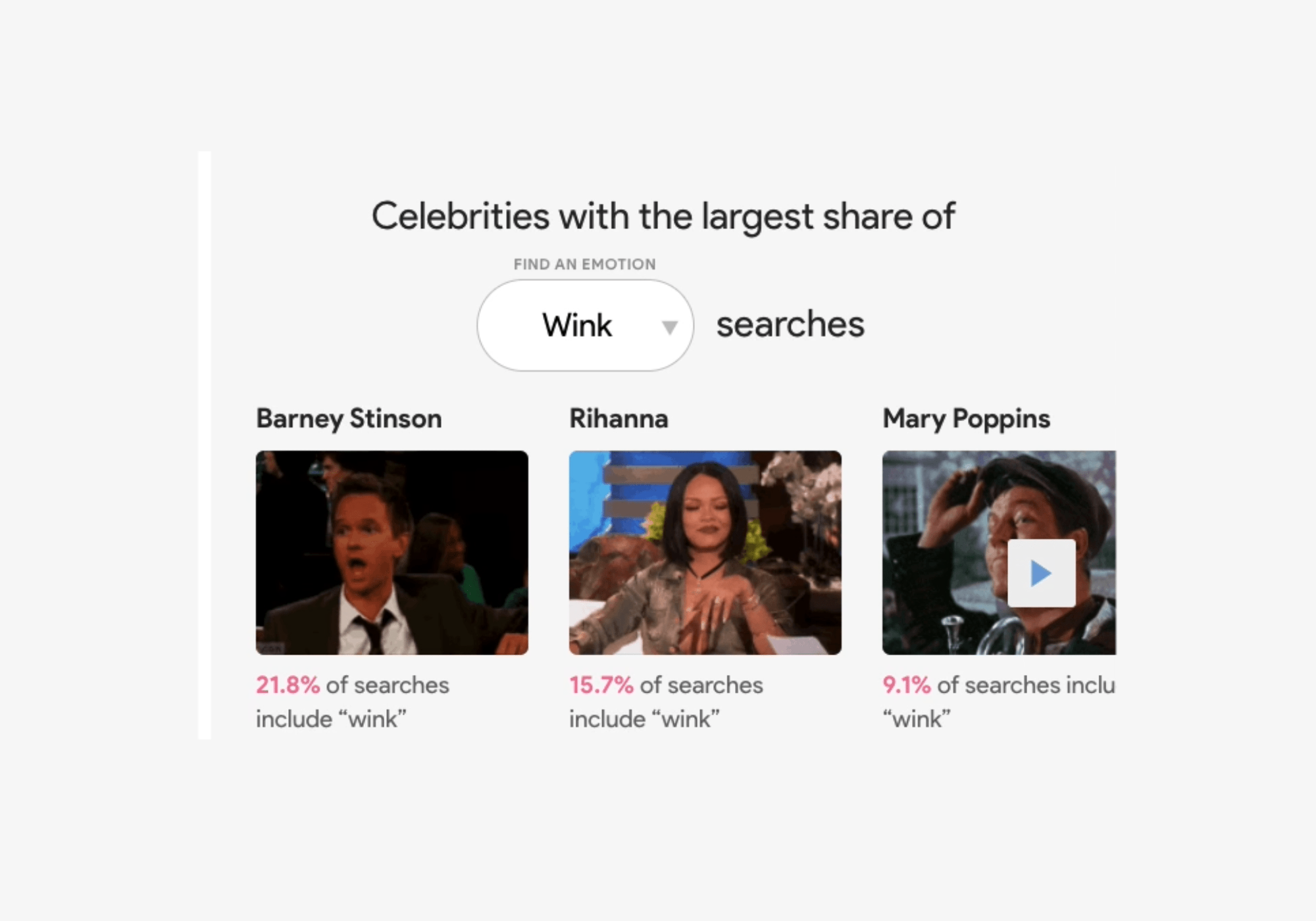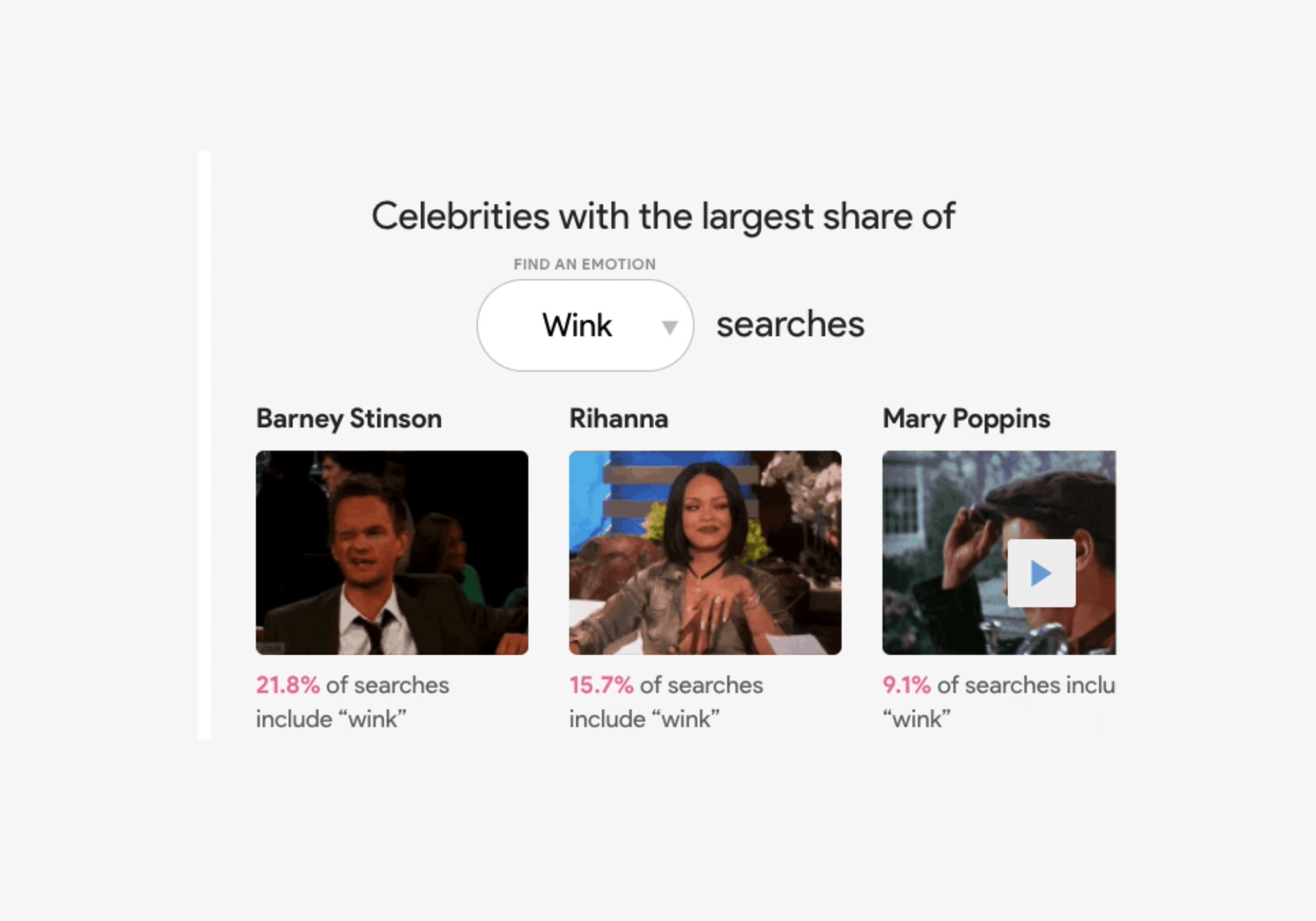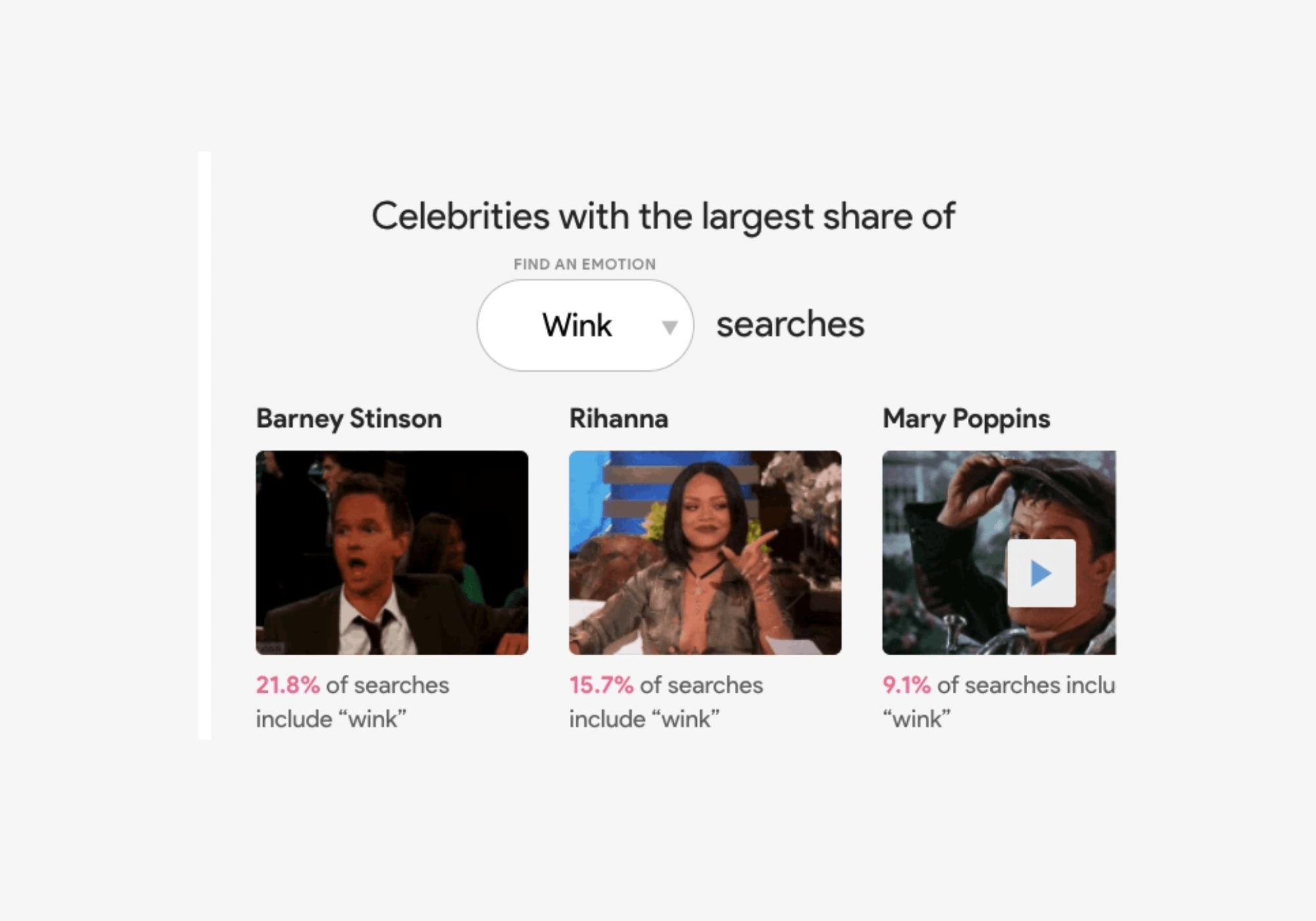
The Google Trends team looked at GIF search trends from Tenor (Google’s search engine for GIFs and stickers) to see which celebrity gifs are most commonly associated with certain emotions or reactions. Good news for GIF-lovers: they made made a nifty data visualization tool that you can explore. Search for a specific celebrity like Justin Timberlake, and you’ll see that 42 percent of Justin Timberlake GIF searches are for “happy.” Or filter by emotion, like “surprised” to find out which celebrity has the largest share of those searches (spoiler alert, it's Pikachu).
Search by celebrity or by emotion.
Even better news for GIF lovers: you can use this tool to figure out how to deal with any situation that you may encounter. Imagine a friend coming to you with one of the problems listed below. There’s a celebrity GIF out there with the appropriate response.
Q:How do I let someone know they’ve upset me without making it a big deal? A:Emma knows it best, you’re not made of stone. It’s ok to let them know how you feel.
Q: How can I be more supportive of my teammates when they do a good job at work? A: Put your hands together for these celebs who have the largest share of “clap” searches.
Q:What should I do on those days when everything is going wrong? A:In or out of the office, we’ve got just the thing: Stanley Hudson, who is the king of laughing it off.
Q: My best friend takes me too seriously. How do I make sure he understands I’m joking? A: Some people need visual cues; a quick wink can help you deliver your punchline.
One of my fondest childhood memories is sitting on my dad’s lap and using a program on our old desktop computer to learn multiplication tables. It jump-started my love for math and science and showed me how technology could make learning exciting.
Educational tools have only improved over the years since I first experienced them. Thanks to educator feedback and companies building tools to help solve real problems in classrooms, they’re better than ever. Today, Feb. 27, thousands of educators across the world are celebrating the use of technology in the classroom by participating in Digital Learning Day. Whether in the classroom or at home, technology can help provide access, increase engagement and help educators and students open up new possibilities for learning. This technology has also helped many students learn the basic digital skills needed for work and life.
As part of our Grow With Google initiative--which helps ensure opportunities created by technology are available to everyone--Applied Digital Skills has curated a collection of our most popular lessons, which include everything from creating a resume to understanding your digital footprint. Applied Digital Skills is Google’s free, online, video-based curriculum that provides training on basic digital skills for learners of all ages. To date, this resource has helped over 1 million students learn digital skills and empowered thousands of educators to teach them in a fun and engaging way.
It’s important to make sure everyone has access to these skills, and community leaders are making sure this happens. Valamere Mikler is the founder of She Ran Tech, a community initiative that encourages digital proficiency and empowerment for women and girls from underserved areas. “Our focus is on data privacy and technology, particularly with girls and young women to educate them on the alternatives to social media trolling, oversharing, idle web surfing and so on,” says Mikler. She’s incorporated Applied Digital Skills lessons into her organization’s internship, as well as its workshops and recommended resources. “We want to get them into technology,” she says. “We are fighting for equity here and this initiative is a way to empower them.”
Valamere and I know firsthand the positive impact technology can have on learning experiences. Dive into our new collection of Digital Learning Day lessons to get started yourself, and use the momentum to embrace educational technology all year round.
Editor’s Note: France’s Chauvet Cave contains some of the world’s oldest prehistoric drawings. It’s so delicate that it’s closed to the public, but thanks to our partner, the Syndicat Mixte de la Grotte Chauvet, you can now step into the world of our ancient ancestors through Google Search’s augmented reality feature as well as virtual reality. One of these ancient ancestors, who has asked to remain anonymous, has time-traveled 36,000 years to share what the cave was like back then.
We began our journey to the big cave days ago. Today we arrive and settle near the stone arch that spans the river. We light a fire, signalling to our people up near the caves that we’re here. We’ve brought small stone tools with us to sew the arrowheads we use for hunting. Perhaps we’ll be able to trade them.
There’s plenty of moonlight, so once we’ve made camp I venture out, hiking up to the cave’s entrance to greet the others. The children are still awake, playing with their toys but also listening intently to the lions roaring in the distance. There used to be bears living here too, but they’re long gone.
The closer I get to its entrance, the more the dark cave seems to draw me in, so I light a torch and step inside. After a short walk, the fire illuminates where we—and those before us—have left our marks. Here, someone scraped the clay, exposed the limestone and painted their world, long before we arrived. My favorites are the horses—I think one is afraid, another is playing, and a third one, the curious one, has pricked up its ears inquiringly.
Near the familiar mammoth, a new image catches my eye—perhaps some of our young hunters have depicted this lion to celebrate their success.
The fresco is so enormous, it’s impossible to take it all in. I step back to try and comprehend its meaning. There are cave lions, reindeer and stags, all seeming to move in the play of light and shadow. Just a few lines, drawn by practiced hands, and somehow we have a masterpiece.
Then there are the handprints left by those who came before us. I stand on my toes and stretch to match my own hand to the imprints on the cold rock, and suddenly I feel compelled to leave my mark too. I’ve never been chosen as a painter, but I’m alone and feeling daring, so I dip my hand into the red paint that’s been left out, rise back to my toes, and add my handprint to the others on the wall.
As it dries, I draw back and watch as the animals and the handprints fade into the darkness. Who knows how long they’ve all been here, and how long they’ll remain?
Another note from the editor: if you enjoyed hearing from our anonymous cave ancestor, check out the following images of the cave she described, or find out more in Google Arts & Culture’s latest exhibit “Chauvet: Meet our Ancestors.”
When you search for the Chauvet Cave on Google Search, the AR in Search features let you view and interact with a 3D model of a fresco in the cave. Use your smartphone to place it directly into your own space, to get a sense of scale and detail.
A torch lights up a cave painting_3.jpg
“Chauvet - The Dawn of Art” is a virtual reality experience available on HTC vive that guides visitors through the Chauvet Cave.
Narrated by Daisy Ridley (English version) or Cécile de France (French version), it shows you 12 stations within the cave. No worries if you don’t have a VR headset - this Youtube 360 video version is equally immersive.
Image of a cave painting with felines
The “alcove of the felines” is the central part of the Horses Fresco, one of the masterpieces of Chauvet Cave.
This is the 3D model of a bear skull that was placed on a block of stone in the cave. It was staged deliberately, meant to be seen this way, and has not moved for 36,000 years.
Hi everyone! We've just released Chrome Beta 81 (81.0.4044.34) for Android: it's now available on Google Play.
You can see a partial list of the changes in the Git log. For details on new features, check out the Chromium blog, and for details on web platform updates, check here.
If you find a new issue, please let us know by filing a bug.
The beta channel has been updated to 81.0.4044.34for Windows, Mac, and, Linux.
A full list of changes in this build is available in the log. Interested in switching release channels? Find out how here. If you find a new issue, please let us know by filing a bug. The community help forum is also a great place to reach out for help or learn about common issues.
Posted by Jordi Pont-Tuset, Research Scientist, Google Research
Open Images is the largest annotated image dataset in many regards, for use in training the latest deep convolutional neural networks for computer vision tasks. With the introduction of version 5 last May, the Open Images dataset includes 9M images annotated with 36M image-level labels, 15.8M bounding boxes, 2.8M instance segmentations, and 391k visual relationships. Along with the dataset itself, the associated Open Images Challenges have spurred the latest advances in object detection, instance segmentation, and visual relationship detection.
Today, we are happy to announce the release of Open Images V6, which greatly expands the annotation of the Open Images dataset with a large set of new visual relationships (e.g., “dog catching a flying disk”), human action annotations (e.g., “woman jumping”), and image-level labels (e.g., “paisley”). Notably, this release also adds localized narratives, a completely new form of multimodal annotations that consist of synchronized voice, text, and mouse traces over the objects being described. In Open Images V6, these localized narratives are available for 500k of its images. Additionally, in order to facilitate comparison to previous works, we also release localized narratives annotations for the full 123k images of the COCO dataset.
Localized Narratives One of the motivations behind localized narratives is to study and leverage the connection between vision and language, typically done via image captioning — images paired with human-authored textual descriptions of their content. One of the limitations of image captioning, however, is the lack of visual grounding, that is, localization on the image of the words in the textual description. To mitigate that, some previous works have a-posteriori drawn the bounding boxes for the nouns present in the description. In contrast, in localized narratives, every word in the textual description is grounded.
Different levels of grounding between image content and captioning. Left to Right: Caption to whole image (COCO); nouns to boxes (Flickr30k Entities); each word to a mouse trace segment (localized narratives). Image sources: COCO, Flickr30k Entities, and Sapa, Vietnam by Rama.
Localized narratives are generated by annotators who provide spoken descriptions of an image while they simultaneously move their mouse to hover over the regions they are describing. Voice annotation is at the core of our approach since it directly connects the description with the regions of the image it is referencing. To make the descriptions more accessible, the annotators manually transcribed their description, which was then aligned with the automatic speech transcription result. This recovers the timestamps for the description, ensuring that the three modalities (speech, text, and mouse trace) are correct and synchronized.
Alignment of manual and automatic transcriptions. Icons based on an original design from Freepik.
Speaking and pointing simultaneously are very intuitive, which allowed us to give the annotators very vague instructions about the task. This creates potential avenues of research for studying how people describe images. For example, we observed different styles when indicating the spatial extent of an object — circling, scratching, underlining, etc. — the study of which could bring valuable insights for the design of new user interfaces.
To get a sense of the amount of additional data these localized narratives represent, the total length of mouse traces is ~6400 km long, and if read aloud without stopping, all the narratives would take ~1.5 years to listen to!
New Visual Relationships, Human Actions, and Image-Level Annotations In addition to the localized narratives, in Open Images V6 we increased the types of visual relationship annotations by an order of magnitude (up to 1.4k), adding for example “man riding a skateboard”, “man and woman holding hands”, and “dog catching a flying disk”.
People in images have been at the core of computer vision interests since its inception and understanding what those people are doing is of utmost importance for many applications. That is why Open Images V6 also includes 2.5M annotations of humans performing standalone actions, such as “jumping”, “smiling”, or “laying down”.
Finally, we also added 23.5M new human-verified image-level labels, reaching a total of 59.9M over nearly 20,000 categories.
Conclusion Open Images V6 is a significant qualitative and quantitative step towards improving the unified annotations for image classification, object detection, visual relationship detection, and instance segmentation, and takes a novel approach in connecting vision and language with localized narratives. We hope that Open Images V6 will further stimulate progress towards genuine scene understanding.
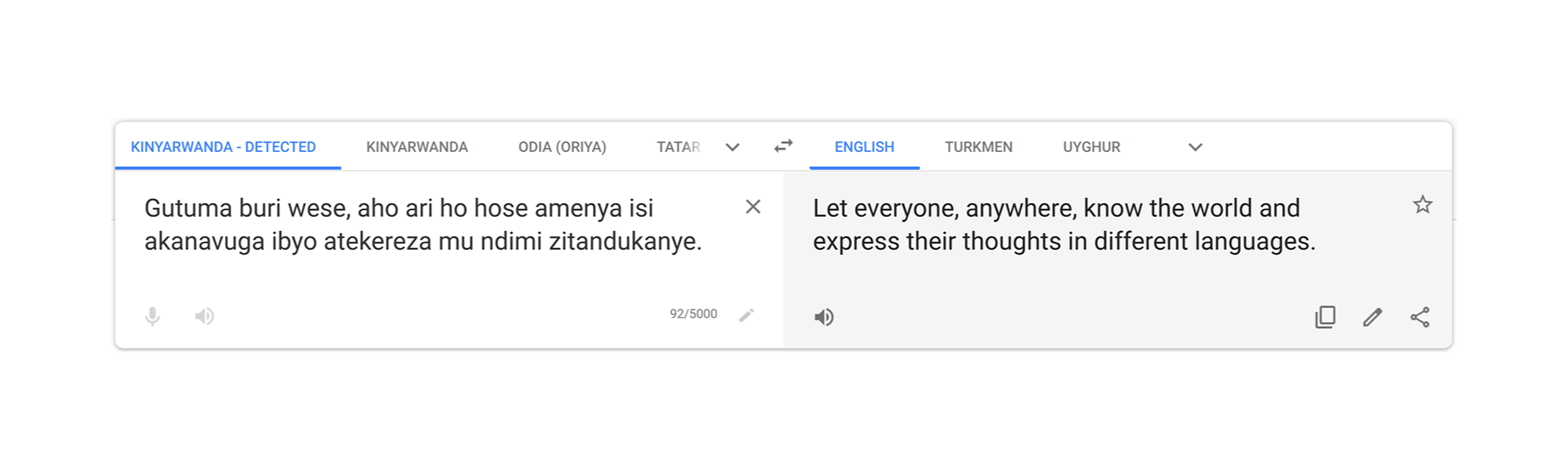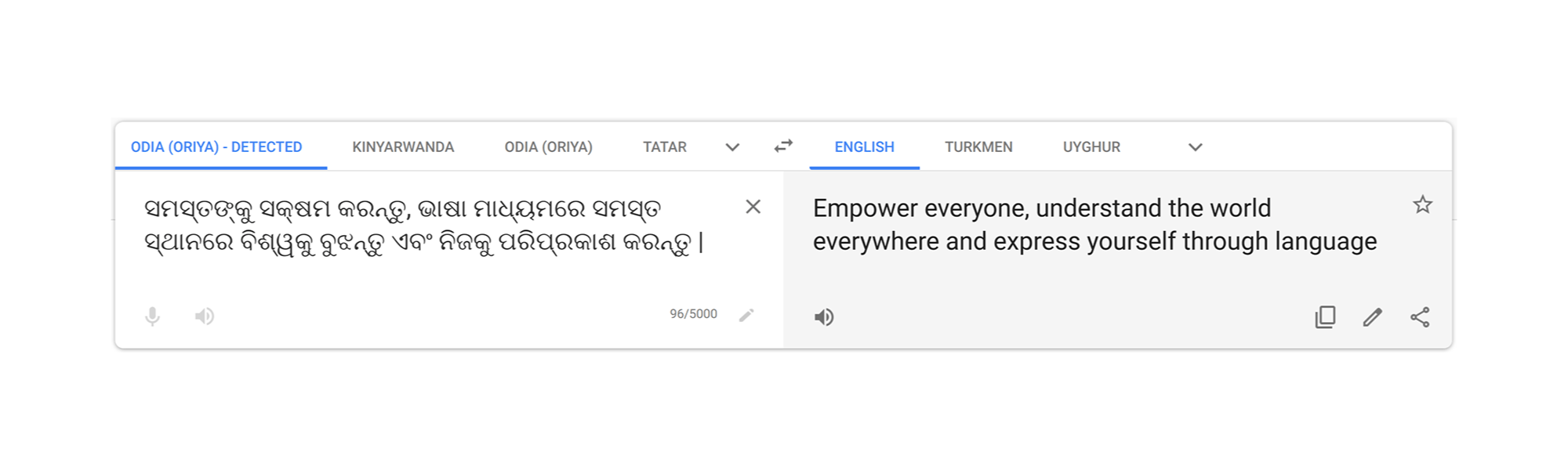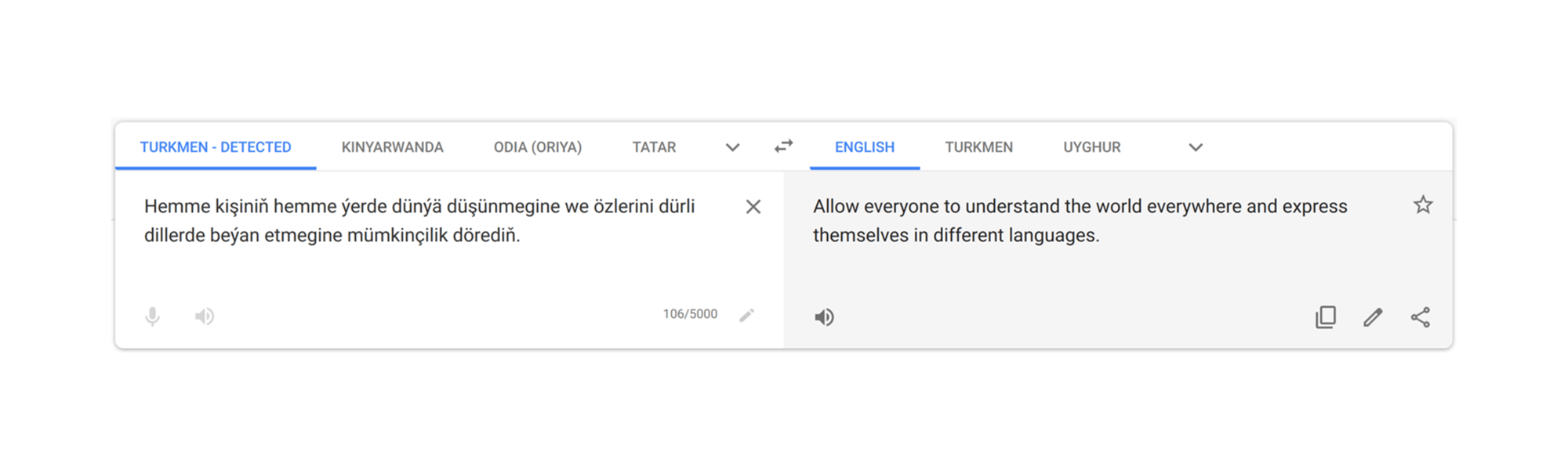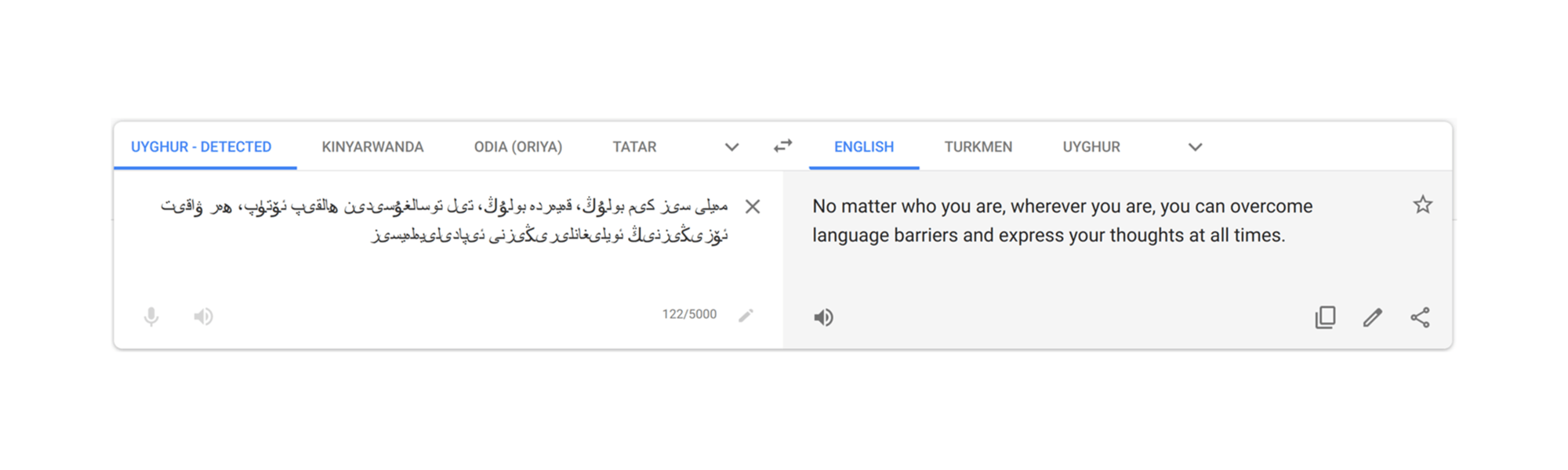
Millions of people around the world use Google Translate, whether in a verbal conversation, or while navigating a menu or reading a webpage online. Translate learns from existing translations, which are most often found on the web. Languages without a lot of web content have traditionally been challenging to translate, but through advancements in our machine learning technology, coupled with active involvement of the Google Translate Community, we’ve added support for five languages: Kinyarwanda, Odia (Oriya), Tatar, Turkmen and Uyghur. These languages, spoken by more than 75 million people worldwide, are the first languages we’ve added to Google Translate in four years, and expand the capabilities of Google Translate to 108 languages.
Translate supports both text translation and website translation for each of these languages. In addition, Translate supports virtual keyboard input for Kinyarwanda, Tatar and Uyghur. Below you can see our team motto, “Enable everyone, everywhere to understand the world and express themselves across languages,” translated into the five new languages.
If you speak any of these languages and are interested in helping, please join the Google Translate Community and improve our translations.
Millions of people around the world use Google Translate, whether in a verbal conversation, or while navigating a menu or reading a webpage online. Translate learns from existing translations, which are most often found on the web. Languages without a lot of web content have traditionally been challenging to translate, but through advancements in our machine learning technology, coupled with active involvement of the Google Translate Community, we’ve added support for five languages: Kinyarwanda, Odia (Oriya), Tatar, Turkmen and Uyghur. These languages, spoken by more than 75 million people worldwide, are the first languages we’ve added to Google Translate in four years, and expand the capabilities of Google Translate to 108 languages.
Translate supports both text translation and website translation for each of these languages. In addition, Translate supports virtual keyboard input for Kinyarwanda, Tatar and Uyghur. Below you can see our team motto, “Enable everyone, everywhere to understand the world and express themselves across languages,” translated into the five new languages.
If you speak any of these languages and are interested in helping, please join the Google Translate Community and improve our translations.
The 12th annual Doodle for Google competition is underway, and we’re asking students across the country to unleash their creativity and show us their interpretation of this year’s theme, “I show kindness by…”. Submissions are due by March 13.
This year we’re excited to announce our panel of stellar guest judges who will help us choose the contest finalists and winners. They have each made showing kindness a guiding principle in their lives. Teacher of the year Rodney Robinson, works to create a positive environment and to empower his students. In 2015 he started teaching at Virgie Binford Education Center, a school inside the Richmond Juvenile Detention Center, in an effort to better understand and prevent students from entering the school-to-prison pipeline.
Joining Rodney as a judge is acclaimed author and illustrator Mari Andrew. Mari values optimism, resilience and vulnerability in her work and has inspired over 1 million devoted fans through her art and writing, where she beautifully covers these subjects. In her New York Times Bestseller book, “Am I There Yet?: The Loop-de-loop, Zigzagging Journey to Adulthood,” she uses poignant essays and illustrations to help her readers feel less alone as they experience the trials and tribulations of life.
Last but certainly not least, the multifaceted entertainer and late-night host Lilly Singh will also join our guest judge panel. Lilly has amassed a global audience of millions through her social channels and work in entertainment—she uses her platform to uplift others. In 2017, UNICEF appointed Lilly as one of their Goodwill Ambassadors. She also created her #GirlLove initiative to inspire positivity among women and support each other's voices encouraging upward mobility.
RodneyRobinson_headshot_2.jpg_201811151549.jpg
Teacher of the Year Rodney Robinson.
MariAndrew_headshot.jpg
Author and illustrator Mari Andrew.
Lilly Singh – Ryan Pfluger Jpeg (1).jpg
Entertainer and late-night host Lilly Singh.
Kindness means something different to everyone, whether it’s starting a community garden, standing up for a friend or doing chores around the home—so it’s up to you how to interpret this year’s theme.
With Rodney, Mari and Lilly’s help, we’ll select five National Finalists who will win a $5,000 college scholarship and a trip to our Mountainview headquarters. One National Winner will receive: a $30,000 college scholarship, a $50,000 technology package for their school or non-profit and their artwork featured on the Google homepage for a day.
We can’t wait to see how you show kindness. Let’s get Doodling!