Video understanding is a challenging problem. Because a video contains spatio-temporal data, its
feature representation is required to abstract both appearance and motion information. This is not only essential for automated understanding of the semantic content of videos, such as web-video classification or sport activity recognition, but is also crucial for robot perception and learning. Just like humans, an input from a robot’s camera is seldom a static snapshot of the world, but takes the form of a continuous video.
The abilities of today’s deep learning models are greatly dependent on their neural architectures.
Convolutional neural networks (CNNs) for videos are normally built by manually extending known 2D architectures such as
Inception and
ResNet to 3D or by carefully designing two-stream CNN architectures that fuse together both appearance and motion information. However, designing an optimal video architecture to best take advantage of spatio-temporal information in videos still remains an open problem. Although neural architecture search (e.g.,
Zoph et al,
Real et al) to discover good architectures has been
widely explored for images, machine-optimized neural architectures for videos have not yet been developed. Video CNNs are typically computation- and memory-intensive, and designing an approach to efficiently search for them while capturing their unique properties has been difficult.
In response to these challenges, we have conducted a series of studies into automatic searches for more optimal network architectures for video understanding. We showcase three different neural architecture evolution algorithms: learning layers and their module configuration (
EvaNet); learning multi-stream connectivity (
AssembleNet); and building computationally efficient and compact networks (
TinyVideoNet). The video architectures we developed outperform existing hand-made models on multiple public datasets by a significant margin, and demonstrate a 10x~100x improvement in network runtime.
EvaNet: The First Evolved Video Architectures
EvaNet, which we introduce in “
Evolving Space-Time Neural Architectures for Videos” at
ICCV 2019, is the very first attempt to design neural architecture search for video architectures. EvaNet is a module-level architecture search that focuses on finding types of spatio-temporal convolutional layers as well as their optimal sequential or parallel configurations. An
evolutionary algorithm with mutation operators is used for the search, iteratively updating a population of architectures. This allows for parallel and more efficient exploration of the search space, which is necessary for video architecture search to consider diverse spatio-temporal layers and their combinations. EvaNet evolves multiple modules (at different locations within the network) to generate different architectures.
Our experimental results confirm the benefits of such video CNN architectures obtained by evolving heterogeneous modules. The approach often finds that non-trivial modules composed of multiple parallel layers are most effective as they are faster and exhibit superior performance to hand-designed modules. Another interesting aspect is that we obtain a number of similarly well-performing, but diverse architectures as a result of the evolution, without extra computation. Forming an ensemble with them further improves performance. Due to their parallel nature, even an ensemble of models is computationally more efficient than the other standard video networks, such as
(2+1)D ResNet. We have open sourced the
code.

Examples of various EvaNet architectures. Each colored box (large or small) represents a layer with the color of the box indicating its type: 3D conv. (blue), (2+1)D conv. (orange), iTGM (green), max pooling (grey), averaging (purple), and 1x1 conv. (pink). Layers are often grouped to form modules (large boxes). Digits within each box indicate the filter size.
AssembleNet: Building Stronger and Better (Multi-stream) models
In “
AssembleNet: Searching for Multi-Stream Neural Connectivity in Video Architectures”, we look into a new method of fusing different sub-networks with different input modalities (e.g.,
RGB and
optical flow) and temporal resolutions. AssembleNet is a “family” of learnable architectures that provide a generic approach to learn the “connectivity” among feature representations across input modalities, while being optimized for the target task. We introduce a general formulation that allows representation of various forms of multi-stream CNNs as
directed graphs, coupled with an efficient evolutionary algorithm to explore the high-level network connectivity. The objective is to learn better feature representations across appearance and motion visual clues in videos. Unlike previous hand-designed
two-stream models that use late fusion or fixed intermediate fusion, AssembleNet evolves a population of overly-connected, multi-stream, multi-resolution architectures while guiding their mutations by
connection weight learning. We are looking at four-stream architectures with various intermediate connections for the first time — 2 streams per RGB and optical flow, each one at different temporal resolutions.
The figure below shows an example of an AssembleNet architecture, found by evolving a pool of random initial multi-stream architectures over 50~150 rounds. We tested AssembleNet on two very popular video recognition datasets:
Charades and
Moments-in-Time (MiT). Its performance on MiT is the first above 34%. The performances on Charades is even more impressive at 58.6% mean Average Precision (mAP), whereas previous best known results are 42.5 and 45.2.

The representative AssembleNet model evolved using the Moments-in-Time dataset. A node corresponds to a block of spatio-temporal convolutional layers, and each edge specifies their connectivity. Darker edges mean stronger connections. AssembleNet is a family of learnable multi-stream architectures, optimized for the target task.


A figure comparing AssembleNet with state-of-the-art, hand-designed models on Charades (left) and Moments-in-Time (right) datasets. AssembleNet-50 or AssembleNet-101 has an equivalent number of parameters to a two-stream ResNet-50 or ResNet-101.
Tiny Video Networks: The fastest video understanding networks
In order for a video CNN model to be useful for devices operating in a real-world environment, such as that needed by robots, real-time, efficient computation is necessary. However, achieving state-of-the-art results on video recognition tasks currently requires extremely large networks, often with tens to hundreds of convolutional layers, that are applied to many input frames. As a result, these networks often suffer from very slow runtimes, requiring at least 500+ ms per 1-second video snippet on a contemporary GPU and 2000+ ms on a CPU. In
Tiny Video Networks, we address this by automatically designing networks that provide comparable performance at a fraction of the computational cost. Our Tiny Video Networks (TinyVideoNets) achieve competitive accuracy and run efficiently, at real-time or better speeds, within 37 to 100 ms on a CPU and 10 ms on a GPU per ~1 second video clip, achieving hundreds of times faster speeds than the other human-designed contemporary models.
These performance gains are achieved by explicitly considering the model run-time during the architecture evolution and forcing the algorithm to explore the search space while including spatial or temporal resolution and channel size to reduce computations. The below figure illustrates two simple, but very effective architectures, found by TinyVideoNet. Interestingly the learned model architectures have fewer convolutional layers than typical video architectures: Tiny Video Networks prefers lightweight elements, such as
2D pooling,
gating layers, and
squeeze-and-excitation layers. Further, TinyVideoNet is able to jointly optimize parameters and runtime to provide efficient networks that can be used by future network exploration.


TinyVideoNet (TVN) architectures evolved to maximize the recognition performance while keeping its computation time within the desired limit. For instance, TVN-1 (top) runs at 37 ms on a CPU and 10ms on a GPU. TVN-2 (bottom) runs at 65ms on a CPU and 13ms on a GPU.

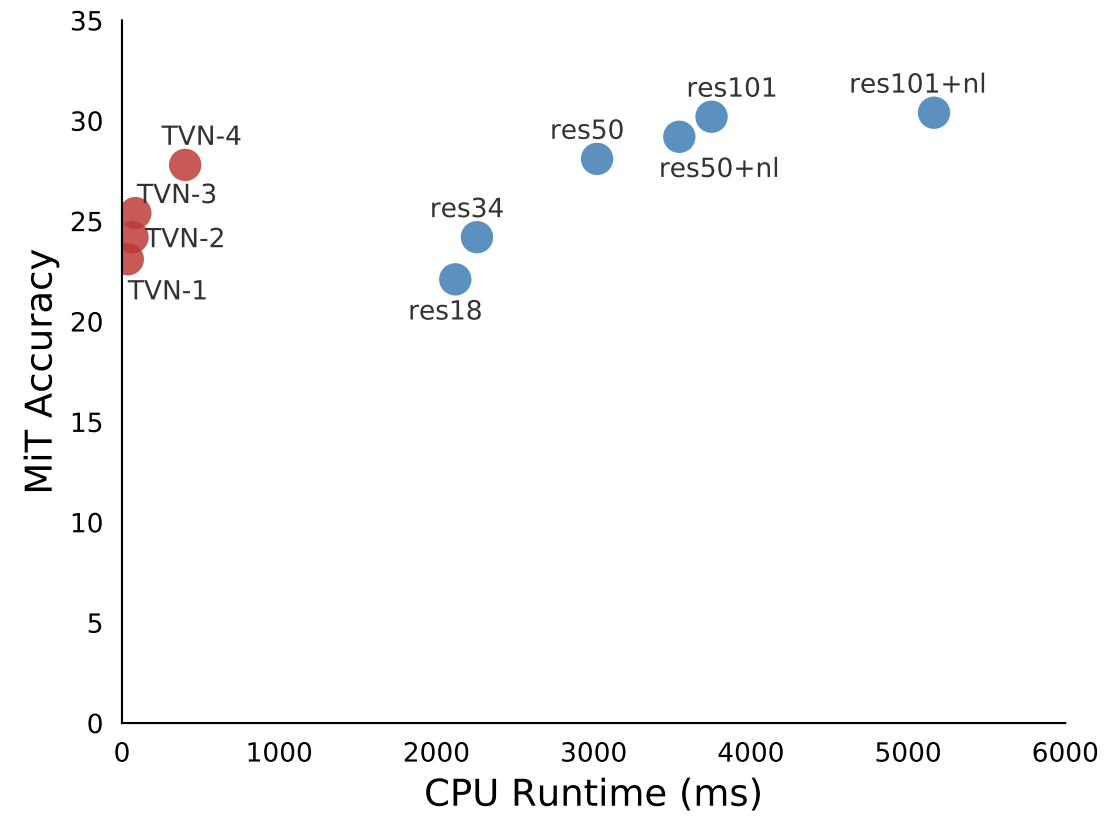
CPU runtime of TinyVideoNet models compared to prior models (left) and runtime vs. model accuracy of TinyVideoNets compared to (2+1)D ResNet models (right). Note that TinyVideoNets take a part of this time-accuracy space where no other models exist, i.e., extremely fast but still accurate.
Conclusion
To our knowledge, this is the very first work on neural architecture search for video understanding. The video architectures we generate with our new evolutionary algorithms outperform the best known hand-designed CNN architectures on public datasets, by a significant margin. We also show that learning computationally efficient video models, TinyVideoNets, is possible with architecture evolution. This research opens new directions and demonstrates the promise of machine-evolved CNNs for video understanding.
Acknowledgements
This research was conducted by Michael S. Ryoo, AJ Piergiovanni, and Anelia Angelova. Alex Toshev and Mingxing Tan also contributed to this work. We thank Vincent Vanhoucke, Juhana Kangaspunta, Esteban Real, Ping Yu, Sarah Sirajuddin, and the Robotics at Google team for discussion and support.