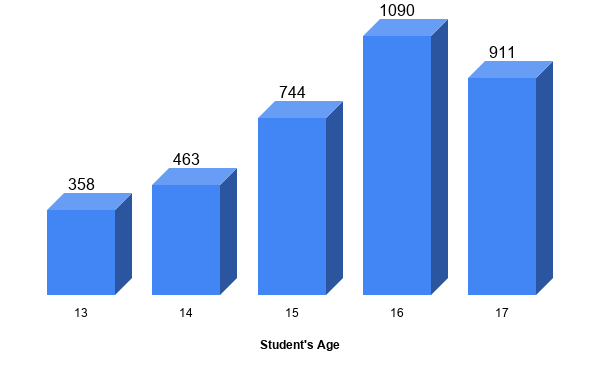
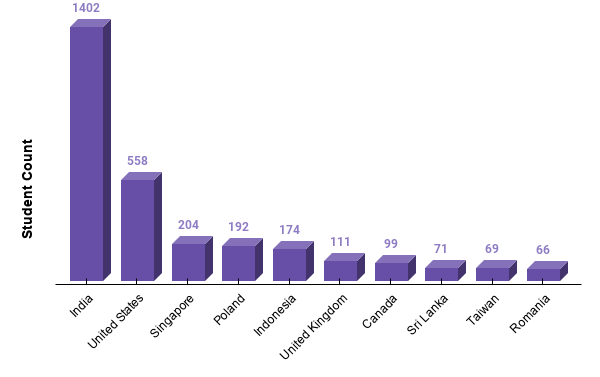
Tekton is a powerful and flexible open-source framework for creating CI/CD systems, allowing developers to build, test, and deploy across cloud providers and on-premise systems. The project recently released its Beta, which creates higher levels of stability by bringing the best features into the Pipelines Beta and brings more trust between the users and the features.

Tekton is used for infrastructure development on top of Kubernetes; it provides an open source framework for creating CI/CD systems, easily allowing developers to build, test, and deploy applications across applications.
With the new Beta functionality, users can rest assured that Beta features will not be removed, and that there will be a 9-month window dedicated to finding solutions for incompatible API changes. Since many in the Tekton community are using Tekton Pipelines to run APIs, this new release helps guarantee that any new developments on top of Tekton are reliable and optimized for best performance, with a budget of several months to make any necessary adjustments.
As platform builders require a stable API and feature set, the Beta launch includes Tasks, ClusterTasks and TaskRuns, Pipelines and PipelineRuns, to provide a foundation that users can rely on. Google created working groups in conjunction with other contributors from various companies to drive the Beta release. The team continues to churn out new Pipeline features towards a GA launch at the end of the year, while also focussing on bringing other components like metadata storage, Triggers, and the Catalog to Beta.
While initially starting as part of the Knative project from Google, in collaboration with developers from other organizations, Tekton was donated to the Continuous Delivery Foundation (CDF) in early 2019. Tekton’s initial design for the interface was even inspired by the Cloud Build API—and to this day—Google remains heavily involved in the commitment to develop Tekton, by participating in the governing board, and staffing a dedicated team invested in the success of this project. These characteristics make Tekton a prime example of a collaboration in open source.
Since its launch in February 2019, Tekton has had 3712 pull requests from 262 contributors across 39 companies spanning 16 countries. Many widely used projects across the open source industry are built on Tekton:
- Puppet Project Nebula
- Jenkins X
- Red Hat OpenShift Pipelines
- IBM Cloud Continuous Delivery
- Kabanero – open source project led by IBM
- Rio – open source project led by Rancher
- Kf – open source project led by Google
kubectl apply -f
https://storage.googleapis.com/tekton-releases/pipeline/latest/release.yaml
You can jump right in by saving this Task to a file called task.yaml:
apiVersion: tekton.dev/v1beta1
kind: Task
metadata:
name: hello-world
spec:
You can jump right in by saving this Task to a file called task.yaml:
apiVersion: tekton.dev/v1beta1
kind: Task
metadata:
name: hello-world
spec:
steps:
- image: ubuntu
script: |
echo "hello world"
Tasks are one of the most important building blocks of Tekton! Head over to tektoncd/catalog for more examples of reusable Tasks.
To run the hello-world Task, first apply it to your cluster with kubectl:
- image: ubuntu
script: |
echo "hello world"
Tasks are one of the most important building blocks of Tekton! Head over to tektoncd/catalog for more examples of reusable Tasks.
To run the hello-world Task, first apply it to your cluster with kubectl:
kubectl apply -f task.yaml
The easiest way to start running our Task is to use the Tekton command line tool, tkn. Install tkn using the right method for your OS, and you can run your Task with:
tkn task start hello-world --showlog
That’s just a taste of Tekton! At tekton.dev/try the community is hard at work adding interactive tutorials that let you try Tekton in a virtual environment. And you can dump straight into the docs at tekton.dev/docs and join the Tekton community at github.com/tektoncd/community.
Congratulations to all the contributors who made this Beta release possible!
By Radha Jhatakia and Christie Wilson, Google Open Source