Welcome to the second edition of our Open Source Programs Office’s (OSPO) annual open source transparency report. In
last year's report on 2019 open source activity, we focused on discovering baselines and trends for Alphabet’s open source activities. However, this past year was unlike any other in recent history. While many continue to investigate the impact of the global pandemic on work, productivity, and behavior, we wanted to understand the pandemic’s impact on Alphabet’s participation in open source.
Our
mission within OSPO is to bring the value of open source to Google and the resources of Google to open source. While open source software remains a critical component of our infrastructure, products, and services, in 2020 we increased our focus on connecting with peers and supporting our extended communities across open source ecosystems. In addition to numerous Alphabet-led
initiatives and programs, our open source community provided
resources, funding, and technical support for projects and communities impacted by the global pandemic.
Before we jump into the data, we want to acknowledge that broad generalizations will never capture the complete context or complexities of personal experience. With these limitations in mind, we will attempt to aggregate what we learned from this past year and explore how our priorities, programs, and adjustments may have affected our measurements and reporting. For more details on the data source and methodology, see the “about this data” section below.
Open source engagement increased as employees moved to their homes
In March 2020, Alphabet closed our offices and required most employees to work from home. In addition to changing workplaces, we adapted our
internship program for virtual participation, focusing many technical projects on open source. This inflection point directly impacted our open source contributor behavior, as observed by monthly active user trends—defined as users that logged any activity in a given month:
- Before March 2020, our GitHub monthly active user counts were relatively stable: In any given month during 2019, about 45% of our yearly active contributing population logged activity on GitHub. Per month in 2019, this value was fairly consistent, with a relative standard deviation of 3%.
- More GitHub users were active after March 2020: Starting in March 2020, our monthly active users grew by more than 20% and then continued to grow into April through July with the arrival of our interns. In addition to growth, activity fluctuated more dramatically with a relative standard deviation of 19%. Removing interns, this value dropped to 13%—still significantly higher than 2019.
- Git-on-borg user patterns remained stable: On git-on-borg—our internal production Git service (more details below), more than 50% of users counted in this analysis were active per month. Activity levels were fairly stable in 2020 with a relative standard deviation of 3%, indicating that our behavior on git-on-borg was less impacted by pandemic-related changes. Note that less than 10% of our 2020 open source interns were active on git-on-borg as most worked on GitHub.
To identify more context behind this change in behavior, we explored our population, projects, and programs, in and around open source.

This chart shows Alphabet’s monthly active users on GitHub, split by total, full-time employees, and interns.
Population: Our population of contributors grew as our composition shifted
In 2020, more than 10% of Alphabet full-time employees (FTEs) actively contributed to open source projects. This percentage has remained roughly consistent over the last five years, indicating that our open source contribution has scaled with the growth of Alphabet.
In addition to our FTEs, some of Alphabet's vendors, independent contractors, temporary staff, and interns have also contributed to open source during their tenures. From 2015-2019, this group represented about 3-5% of our total population of open source contributors. In 2020, this ratio doubled to 10% as many interns shifted to focus on open source. As a result, interns represented about 9% of our overall open source contributing population in 2020.
This chart shows the aggregate per year counts of Alphabet employees, vendors, contractors, temps, and interns contributing to open source.
Scope: We created and interacted with more repositories and projects
Within Google-managed organizations, we created more than 2,000 new public repositories on GitHub, bringing our total active public repositories to over 9,000 on GitHub and over 1,500 on git-on-borg. While many of these new repositories were created within existing projects or to extend functionality of our products, more than 20% of our new GitHub repositories were created to host our
interns’ open source projects. Moving forward, we anticipate that our total public repositories under management will stabilize or even shrink as we refine our depreciation and archival policies. In addition to supporting our own projects:
- We engaged with more repositories on GitHub: In 2020, contributors at Alphabet interacted with more than 90,000 repositories on GitHub, pushing commits and/or opening pull requests on over 50,000 repositories. Removing passive interactions (WatchEvents or “stars”), we actively engaged with over 75,000 repositories in 2020.
- We surpassed our growth rates from 2019. Across all metrics listed above, we engaged with 25% more repositories than in 2019—a growth rate significantly higher than last year’s growth rate of 15%-18%. These rates are not impacted by removing the repositories that supported our interns.
- We continue to invest time in projects outside of Google: Consistent with our 2019 report, on GitHub more than 75% of repositories with pull requests opened by Alphabet contributors were outside of Google-managed organizations.
Behavior: Contribution activities increased, elevated by our interns
To take a closer look at our behavior, we explored all
event types across GitHub Archive, grouping events into the following categories:
| Category groups | GitHub Event Types |
| Code | PushEvent, PullRequestEvent, ForkEvent |
| Code Review | PullRequestReviewEvent, PullRequestReviewCommentEvent, CommitCommentEvent |
| Issue | IssuesEvent, IssueCommentEvent |
| Maintenance and administration | MemberEvent, CreateEvent, DeleteEvent, ReleaseEvent, PublicEvent |
| Wiki/Doc | GollumEvent |
| Star | WatchEvent |
Exploring trends across event types, we found that:
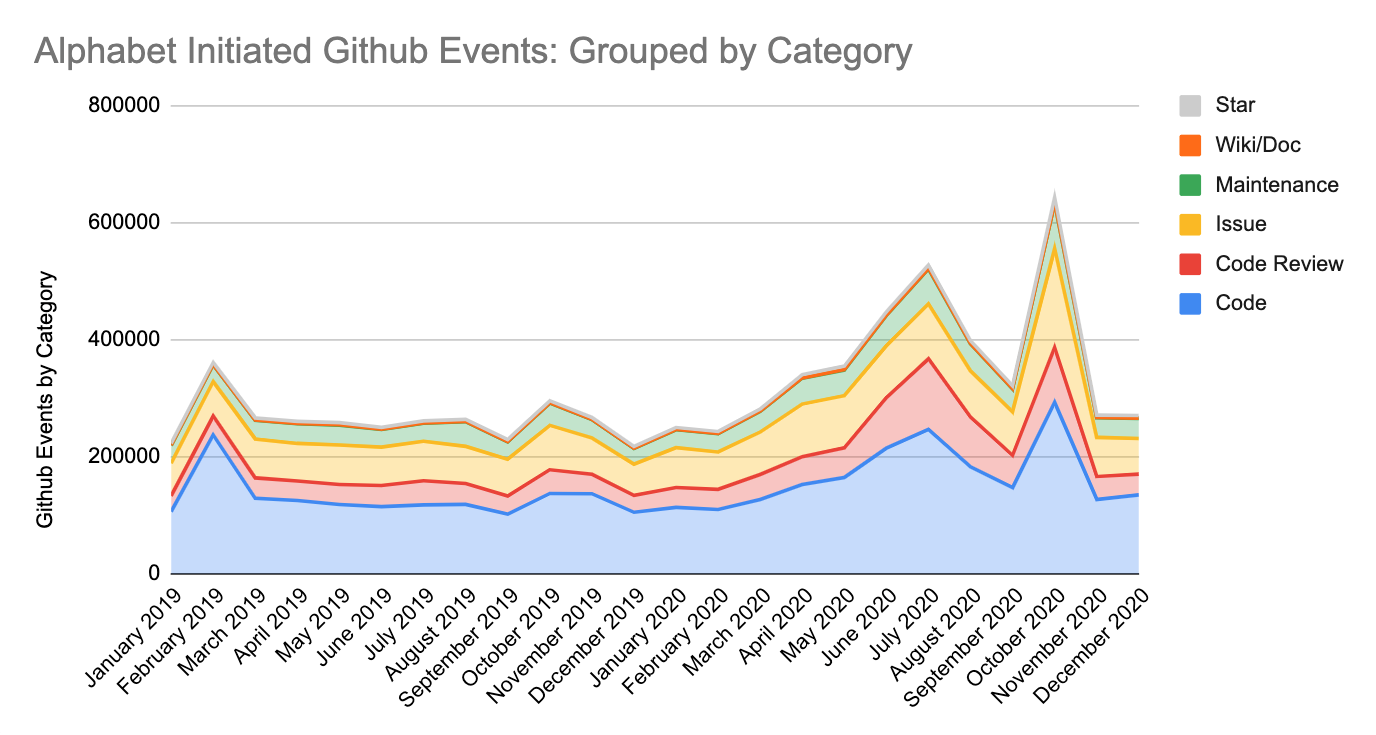
- GitHub activity grew across all event types: This is not surprising given our growth in the contributing population and repository counts described above. More specifically, in 2020, contributors at Alphabet created more than 780,000 issue comments, and opened over 240,000 pull requests on GitHub. Compared to 2019, we generated 32% more issue comments and opened 50% more pull requests in 2020. Removing WatchEvents, in 2020 our overall activity on GitHub grew by more than 35%.
- Interns bolstered our growth on GitHub: While in previous years, full-time Alphabet employees were responsible for over 97% of all reported activity on GitHub, in 2020 interns opened more than 10% of Alphabet’s total pull requests on this platform.
- git-on-borg’s growth rate was consistent with 2019: Where our GitHub activity growth rates increased, our submitted and reviewed changes on git-on-borg grew by 17%, consistent with our 2018-2019 year-over-year growth on this platform and on GitHub. This consistent trajectory once again implies that individuals working on git-on-borg did not significantly change their behavior as a result of the global pandemic. Please note, that the activity pulled from git-on-borg for this analysis was only from Google managed projects where GitHub logs also included non-Google organizations and personal activity.

This chart shows per-month counts of activities initiated by the Alphabet community on GitHub.
Note: not showing “PullRequestReviewEvent”, which GitHub Archive started collecting in August 2020.
Changes: What drove this change in behavior?
While 2020 behavior cannot be separated from the impact of the global pandemic, we were curious if we could isolate specific programs and externalities that would explain the uptick in monthly active users and spikes in logged activities. Again, acknowledging the limitations of aggregate analysis, we found evidence that these measurements were impacted by:
- Intern hosts: In May-Sept, we welcomed more than 1000 interns and set them to work on open source projects. In addition to intern-driven activities, teams that hosted interns had to interact with these projects in public channels, which contributed to additional individuals logging actions on GitHub between April and September.
- Tenured employees. To investigate other drivers of the March 2020 uplift in GitHub monthly active users, we filtered out interns and individuals that were new to Alphabet in 2020, which led us to believe that this increase could mostly be attributed to existing employees increasing their time on GitHub.
- Hacktoberfest: During Hacktoberfest (October 2020), we saw a significant spike in activity with the largest uptick concentrated in issue-related activities, as open source contributors at Alphabet responded to activities initiated during this event.
We also interviewed open source contributors around the organization to understand how their professional and personal open source activity may have been impacted due to COVID-19. Although each case was unique, common themes were:
- Remote work: With most teams working remotely, some reported that they relied more heavily on asynchronous tooling for collaboration and code review, which would yield additional logged activities on hosting platforms.
- Open source as a personal outlet: For others, open source provided a place to create and socialize outside of work. This trend was also reported in GitHub’s Octoberverse report on productivity which showed an uptick in open source activity outside of traditional work hours.
Please note, that Alphabet’s aggregate experience does not translate to behavioral or productivity trends in specific projects that we work on. For example, leading up to Kubernetes’ 1.19 release in May 2020, community leaders
reported declining engagement, measured by a 15% decline in daily pull request reviews across Kubernetes organizations compared to the 2019 average.
Beyond code: We continue to invest in all aspects of open source
Alphabet relies on the health and availability of open source projects, and as such we continue to invest in security and sustainability across the supply chain, from
respectful language updates in our own projects to:
- Mentorship and community engagement: In its 16th year of the program, Google’s 2020 Summer of Code program had 1,106 students from 65 countries successfully complete the program under the guidance of over 2,000 mentors. In its second year, Season of Docs sponsored 87 technical writers working on 48 projects with the support of over 100 mentors. And with in-person events postponed until further notice, we launched the Google Open Source Live monthly series to connect with our extended community, hosting 5 events last year, 7 so far in 2021, and more planned in the final quarters of 2021.
- Improving open source stability and security: Security challenges are never going to disappear, and we must work together to maintain the security of the open source software we collectively depend on. In 2020, Google co-founded the OpenSSF to collaborate on tools and frameworks to improve open source security. As part of this community, we released Criticality Score and provided significant contributions to project Scorecards to help users, contributors, companies, and communities generate relative criticality metrics for projects that they depend on. Additionally, in 2020 the OSS-Fuzz project nearly doubled the number of supported projects to more than 400 projects, and identified more than 25,000 bugs. In addition to the main effort, the Fuzz team hosted interns, launched the Atheris Python Fuzzer, and ramped up a FuzzBench service to help academic researchers run large scale experiments on their fuzzing tools.
Despite perpetual uncertainty, we will continue to invest in the open source ecosystem as we value the connection, collaboration and community even when we are kept apart by a global pandemic. Learn more about our open source initiatives at
opensource.google.
About the data:
- Data source: These data represent activities on repositories hosted on GitHub and our internal production Git service git-on-borg. These sources represent a subset of open source activity currently tracked by our OSPO.
- GitHub: We continue to use GitHub Archive as the primary source for GitHub data, which is available as a public dataset on BigQuery. Alphabet activity within GitHub is identified by self-registered accounts, which we estimate underreports actual activity. This year we decided to generate this report from Monthly Tables instead of Yearly Tables in order to explore contribution patterns within the year.
- git-on-borg: This is our primary platform for internal projects and some of our larger, long running public projects like Android and Chromium. While we continue to develop on this platform, most of our open source activity has moved to GitHub to increase exposure and encourage community growth.
- Distinct event types: Note that git-on-borg and GitHub APIs produce distinct sets of events—as such we will report activity metrics per platform. Where GitHub Event logs capture a wide range of activity from code creation and review to issue creation and comments, the Gerrit Event stream (used by git-on-borg) only captures code changes and reviews.
- Driven by humans: We have created many automated bots and systems that can propose changes on various hosting platforms. We have intentionally filtered these data to focus on human-initiated activities.
- Business and personal: Activity on GitHub reflects a mixture of Alphabet projects, third party projects, experimental efforts, and personal projects. Our metrics report on all of the above unless otherwise specified.
- Alphabet contributors: Please note that unless additional detail is specified, activity counts attributed to Alphabet open source contributors will include our full-time employees as well as our extended Alphabet community (temps, vendors, contractors, and interns).
- Active counts: Where possible, we will show ‘active users’ defined by logged activity within a specified timeframe (i.e. in month, year, etc) and ‘active repositories’ as those that have not been archived.
- Activity types: This year we explore GitHub activity types in more detail. Note that in some cases we have removed “Watch Events” or articulated this as passive engagement. Additionally, GitHub added an event type “PullRequestReviewEvent” that started logging activity in August 2020, but we chose to remove this from our charts and aggregate counts as it invalidates year over year comparisons.
By Sophia Vargas, Research Analyst – Google Open Source Programs Office