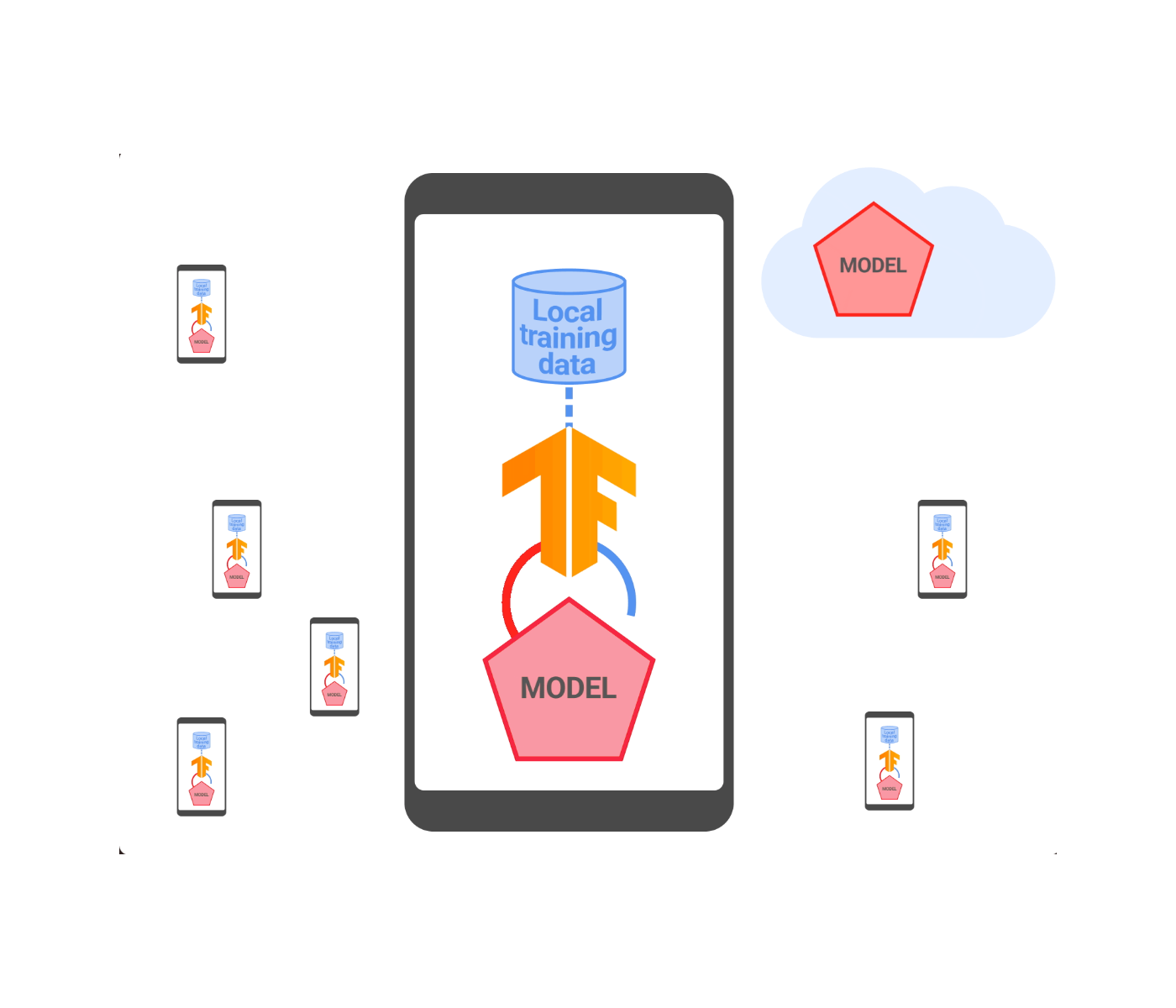
Language models (LMs) trained to predict the next word given input text are the key technology for many applications [1, 2]. In Gboard, LMs are used to improve users’ typing experience by supporting features like next word prediction (NWP), Smart Compose, smart completion and suggestion, slide to type, and proofread. Deploying models on users’ devices rather than enterprise servers has advantages like lower latency and better privacy for model usage. While training on-device models directly from user data effectively improves the utility performance for applications such as NWP and smart text selection, protecting the privacy of user data for model training is important.
 |
| Gboard features powered by on-device language models. |
In this blog we discuss how years of research advances now power the private training of Gboard LMs, since the proof-of-concept development of federated learning (FL) in 2017 and formal differential privacy (DP) guarantees in 2022. FL enables mobile phones to collaboratively learn a model while keeping all the training data on device, and DP provides a quantifiable measure of data anonymization. Formally, DP is often characterized by (ε, δ) with smaller values representing stronger guarantees. Machine learning (ML) models are considered to have reasonable DP guarantees for ε=10 and strong DP guarantees for ε=1 when δ is small.
As of today, all NWP neural network LMs in Gboard are trained with FL with formal DP guarantees, and all future launches of Gboard LMs trained on user data require DP. These 30+ Gboard on-device LMs are launched in 7+ languages and 15+ countries, and satisfy (ɛ, δ)-DP guarantees of small δ of 10-10 and ɛ between 0.994 and 13.69. To the best of our knowledge, this is the largest known deployment of user-level DP in production at Google or anywhere, and the first time a strong DP guarantee of ɛ < 1 is announced for models trained directly on user data.
Privacy principles and practices in Gboard
In “Private Federated Learning in Gboard”, we discussed how different privacy principles are currently reflected in production models, including:
- Transparency and user control: We provide disclosure of what data is used, what purpose it is used for, how it is processed in various channels, and how Gboard users can easily configure the data usage in learning models.
- Data minimization: FL immediately aggregates only focused updates that improve a specific model. Secure aggregation (SecAgg) is an encryption method to further guarantee that only aggregated results of the ephemeral updates can be accessed.
- Data anonymization: DP is applied by the server to prevent models from memorizing the unique information in individual user’s training data.
- Auditability and verifiability: We have made public the key algorithmic approaches and privacy accounting in open-sourced code (TFF aggregator, TFP DPQuery, DP accounting, and FL system).
A brief history
In recent years, FL has become the default method for training Gboard on-device LMs from user data. In 2020, a DP mechanism that clips and adds noise to model updates was used to prevent memorization for training the Spanish LM in Spain, which satisfies finite DP guarantees (Tier 3 described in “How to DP-fy ML“ guide). In 2022, with the help of the DP-Follow-The-Regularized-Leader (DP-FTRL) algorithm, the Spanish LM became the first production neural network trained directly on user data announced with a formal DP guarantee of (ε=8.9, δ=10-10)-DP (equivalent to the reported ρ=0.81 zero-Concentrated-Differential-Privacy), and therefore satisfies reasonable privacy guarantees (Tier 2).
Differential privacy by default in federated learning
In “Federated Learning of Gboard Language Models with Differential Privacy”, we announced that all the NWP neural network LMs in Gboard have DP guarantees, and all future launches of Gboard LMs trained on user data require DP guarantees. DP is enabled in FL by applying the following practices:
- Pre-train the model with the multilingual C4 dataset.
- Via simulation experiments on public datasets, find a large DP-noise-to-signal ratio that allows for high utility. Increasing the number of clients contributing to one round of model update improves privacy while keeping the noise ratio fixed for good utility, up to the point the DP target is met, or the maximum allowed by the system and the size of the population.
- Configure the parameter to restrict the frequency each client can contribute (e.g., once every few days) based on computation budget and estimated population in the FL system.
- Run DP-FTRL training with limits on the magnitude of per-device updates chosen either via adaptive clipping, or fixed based on experience.
SecAgg can be additionally applied by adopting the advances in improving computation and communication for scales and sensitivity.
 |
| Federated learning with differential privacy and (SecAgg). |
Reporting DP guarantees
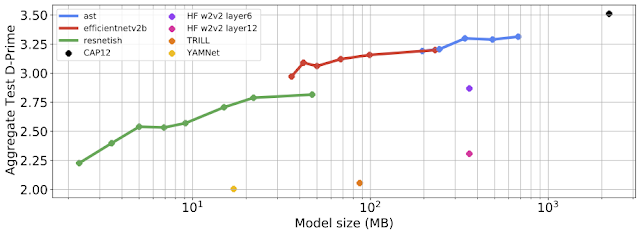
The DP guarantees of launched Gboard NWP LMs are visualized in the barplot below. The x-axis shows LMs labeled by language-locale and trained on corresponding populations; the y-axis shows the ε value when δ is fixed to a small value of 10-10 for (ε, δ)-DP (lower is better). The utility of these models are either significantly better than previous non-neural models in production, or comparable with previous LMs without DP, measured based on user-interactions metrics during A/B testing. For example, by applying the best practices, the DP guarantee of the Spanish model in Spain is improved from ε=8.9 to ε=5.37. SecAgg is additionally used for training the Spanish model in Spain and English model in the US. More details of the DP guarantees are reported in the appendix following the guidelines outlined in “How to DP-fy ML”.
Towards stronger DP guarantees
The ε~10 DP guarantees of many launched LMs are already considered reasonable for ML models in practice, while the journey of DP FL in Gboard continues for improving user typing experience while protecting data privacy. We are excited to announce that, for the first time, production LMs of Portuguese in Brazil and Spanish in Latin America are trained and launched with a DP guarantee of ε ≤ 1, which satisfies Tier 1 strong privacy guarantees. Specifically, the (ε=0.994, δ=10-10)-DP guarantee is achieved by running the advanced Matrix Factorization DP-FTRL (MF-DP-FTRL) algorithm, with 12,000+ devices participating in every training round of server model update larger than the common setting of 6500+ devices, and a carefully configured policy to restrict each client to at most participate twice in the total 2000 rounds of training in 14 days in the large Portuguese user population of Brazil. Using a similar setting, the es-US Spanish LM was trained in a large population combining multiple countries in Latin America to achieve (ε=0.994, δ=10-10)-DP. The ε ≤ 1 es-US model significantly improved the utility in many countries, and launched in Colombia, Ecuador, Guatemala, Mexico, and Venezuela. For the smaller population in Spain, the DP guarantee of es-ES LM is improved from ε=5.37 to ε=3.42 by only replacing DP-FTRL with MF-DP-FTRL without increasing the number of devices participating every round. More technical details are disclosed in the colab for privacy accounting.
 |
| DP guarantees for Gboard NWP LMs (the purple bar represents the first es-ES launch of ε=8.9; cyan bars represent privacy improvements for models trained with MF-DP-FTRL; tiers are from “How to DP-fy ML“ guide; en-US* and es-ES* are additionally trained with SecAgg). |
Discussion and next steps
Our experience suggests that DP can be achieved in practice through system algorithm co-design on client participation, and that both privacy and utility can be strong when populations are large and a large number of devices' contributions are aggregated. Privacy-utility-computation trade-offs can be improved by using public data, the new MF-DP-FTRL algorithm, and tightening accounting. With these techniques, a strong DP guarantee of ε ≤ 1 is possible but still challenging. Active research on empirical privacy auditing [1, 2] suggests that DP models are potentially more private than the worst-case DP guarantees imply. While we keep pushing the frontier of algorithms, which dimension of privacy-utility-computation should be prioritized?
We are actively working on all privacy aspects of ML, including extending DP-FTRL to distributed DP and improving auditability and verifiability. Trusted Execution Environment opens the opportunity for substantially increasing the model size with verifiable privacy. The recent breakthrough in large LMs (LLMs) motivates us to rethink the usage of public information in private training and more future interactions between LLMs, on-device LMs, and Gboard production.
Acknowledgments
The authors would like to thank Peter Kairouz, Brendan McMahan, and Daniel Ramage for their early feedback on the blog post itself, Shaofeng Li and Tom Small for helping with the animated figures, and the teams at Google that helped with algorithm design, infrastructure implementation, and production maintenance. The collaborators below directly contribute to the presented results:
Research and algorithm development: Galen Andrew, Stanislav Chiknavaryan, Christopher A. Choquette-Choo, Arun Ganesh, Peter Kairouz, Ryan McKenna, H. Brendan McMahan, Jesse Rosenstock, Timon Van Overveldt, Keith Rush, Shuang Song, Thomas Steinke, Abhradeep Guha Thakurta, Om Thakkar, and Yuanbo Zhang.
Infrastructure, production and leadership support: Mingqing Chen, Stefan Dierauf, Billy Dou, Hubert Eichner, Zachary Garrett, Jeremy Gillula, Jianpeng Hou, Hui Li, Xu Liu, Wenzhi Mao, Brett McLarnon, Mengchen Pei, Daniel Ramage, Swaroop Ramaswamy, Haicheng Sun, Andreas Terzis, Yun Wang, Shanshan Wu, Yu Xiao, and Shumin Zhai.