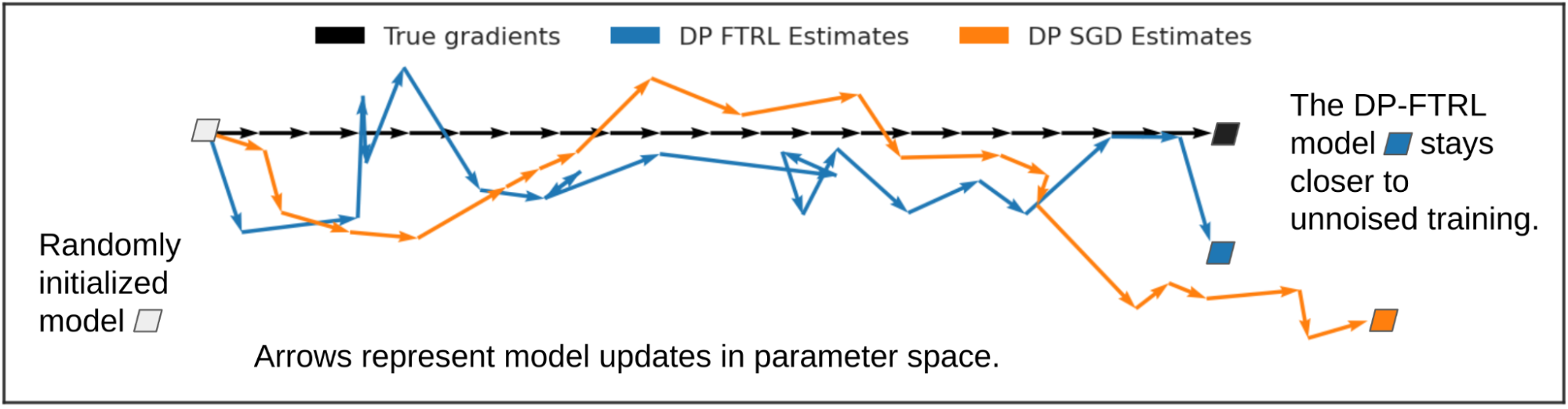
When people converse with one another, context and references play a critical role in driving their conversation more efficiently. For instance, if one asks the question “Who wrote Romeo and Juliet?” and, after receiving an answer, asks “Where was he born?”, it is clear that ‘he’ is referring to William Shakespeare without the need to explicitly mention him. Or if someone mentions “python” in a sentence, one can use the context from the conversation to determine whether they are referring to a type of snake or a computer language. If a virtual assistant cannot robustly handle context and references, users would be required to adapt to the limitation of the technology by repeating previously shared contextual information in their follow-up queries to ensure that the assistant understands their requests and can provide relevant answers.
In this post, we present a technology currently deployed on Google Assistant that allows users to speak in a natural manner when referencing context that was defined in previous queries and answers. The technology, based on the latest machine learning (ML) advances, rephrases a user’s follow-up query to explicitly mention the missing contextual information, thus enabling it to be answered as a stand-alone query. While Assistant considers many types of context for interpreting the user input, in this post we are focusing on short-term conversation history.
Context Handling by Rephrasing
One of the approaches taken by Assistant to understand contextual queries is to detect if an input utterance is referring to previous context and then rephrase it internally to explicitly include the missing information. Following on from the previous example in which the user asked who wrote Romeo and Juliet, one may ask follow-up questions like “When?”. Assistant recognizes that this question is referring to both the subject (Romeo and Juliet) and answer from the previous query (William Shakespeare) and can rephrase “When?” to “When did William Shakespeare write Romeo and Juliet?”
While there are other ways to handle context, for instance, by applying rules directly to symbolic representations of the meaning of queries, like intents and arguments, the advantage of the rephrasing approach is that it operates horizontally at the string level across any query answering, parsing, or action fulfillment module.
 |
| Conversation on a smart display device, where Assistant understands multiple contextual follow-up queries, allowing the user to have a more natural conversation. The phrases appearing at the bottom of the display are suggestions for follow-up questions that the user can select. However, the user can still ask different questions. |
A Wide Variety of Contextual Queries
The natural language processing field, traditionally, has not put much emphasis on a general approach to context, focusing on the understanding of stand-alone queries that are fully specified. Accurately incorporating context is a challenging problem, especially when considering the large variety of contextual query types. The table below contains example conversations that illustrate query variability and some of the many contextual challenges that Assistant’s rephrasing method can resolve (e.g., differentiating between referential and non-referential cases or identifying what context a query is referencing). We demonstrate how Assistant is now able to rephrase follow-up queries, adding contextual information before providing an answer.
 |
System Architecture
At a high level, the rephrasing system generates rephrasing candidates by using different types of candidate generators. Each rephrasing candidate is then scored based on a number of signals, and the one with the highest score is selected.
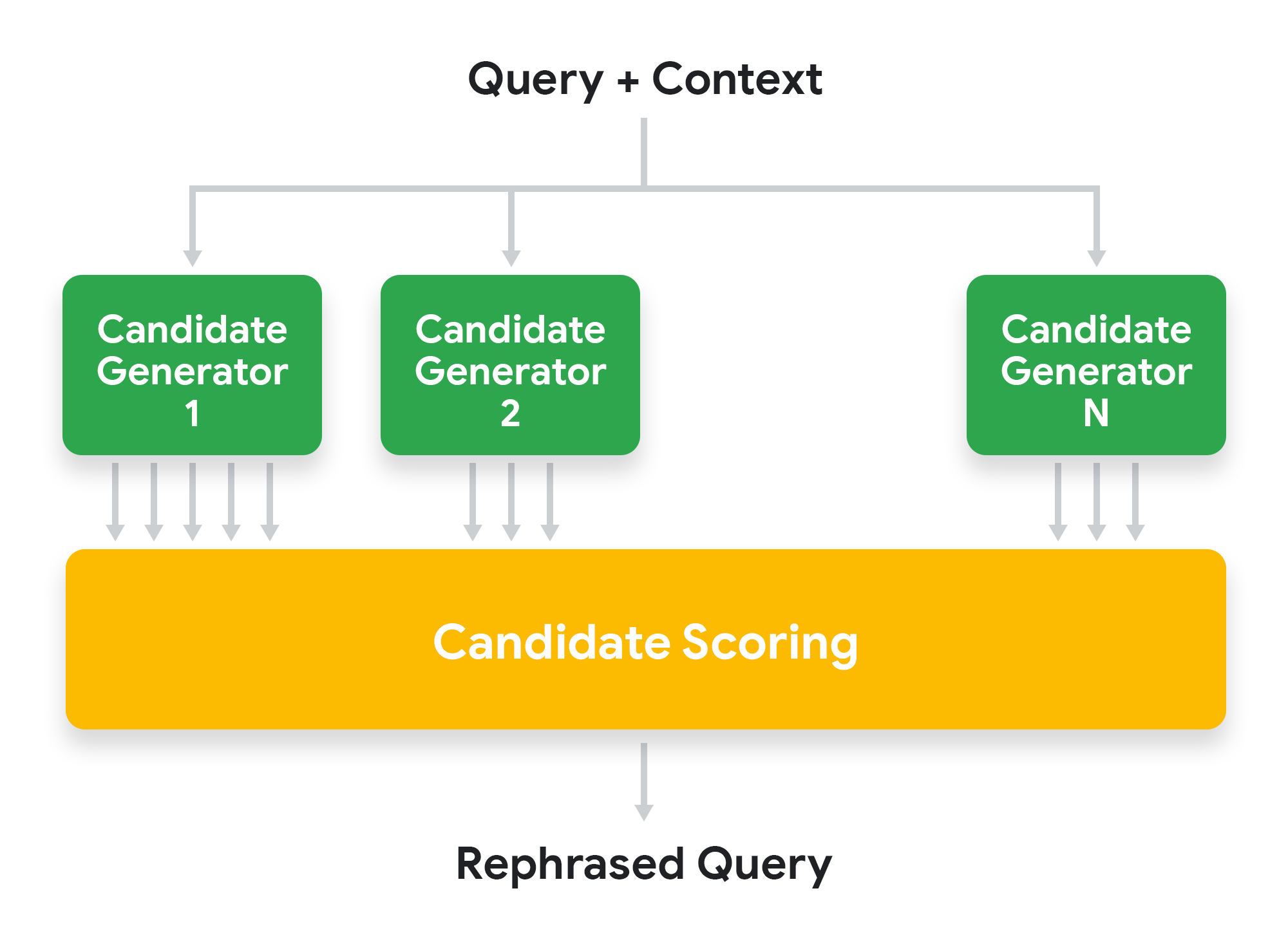 |
| High level architecture of Google Assistant contextual rephraser. |
Candidate Generation
To generate rephrasing candidates we use a hybrid approach that applies different techniques, which we classify into three categories:
- Generators based on the analysis of the linguistic structure of the queries use grammatical and morphological rules to perform specific operations — for instance, the replacement of pronouns or other types of referential phrases with antecedents from the context.
- Generators based on query statistics combine key terms from the current query and its context to create candidates that match popular queries from historical data or common query patterns.
- Generators based on Transformer technologies, such as MUM, learn to generate sequences of words according to a number of training samples. LaserTagger and FELIX are technologies suitable for tasks with high overlap between the input and output texts, are very fast at inference time, and are not vulnerable to hallucination (i.e., generating text that is not related to the input texts). Once presented with a query and its context, they can generate a sequence of text edits to transform the input queries into a rephrasing candidate by indicating which portions of the context should be preserved and which words should be modified.
Candidate Scoring
We extract a number of signals for each rephrasing candidate and use an ML model to select the most promising candidate. Some of the signals depend only on the current query and its context. For example, is the topic of the current query similar to the topic of the previous query? Or, is the current query a good stand-alone query or does it look incomplete? Other signals depend on the candidate itself: How much of the information of the context does the candidate preserve? Is the candidate well-formed from a linguistic point of view? Etc.
Recently, new signals generated by BERT and MUM models have significantly improved the performance of the ranker, fixing about one-third of the recall headroom while minimizing false positives on query sequences that are not contextual (and therefore do not require a rephrasing).
 |
| Example conversation on a phone where Assistant understands a sequence of contextual queries. |
Conclusion
The solution described here attempts to resolve contextual queries by rephrasing them in order to make them fully answerable in a stand-alone manner, i.e., without having to relate to other information during the fulfillment phase. The benefit of this approach is that it is agnostic to the mechanisms that would fulfill the query, thus making it usable as a horizontal layer to be deployed before any further processing.
Given the variety of contexts naturally used in human languages, we adopted a hybrid approach that combines linguistic rules, large amounts of historic data through logs, and ML models based on state-of-the-art Transformer approaches. By generating a number of rephrasing candidates for each query and its context, and then scoring and ranking them using a variety of signals, Assistant can rephrase and thus correctly interpret most contextual queries. As Assistant can handle most types of linguistic references, we are empowering users to have more natural conversations. To make such multi-turn conversations even less cumbersome, Assistant users can turn on Continued Conversation mode to enable asking follow-up queries without the need to repeat "Hey Google" between each query. We are also using this technology in other virtual assistant settings, for instance, interpreting context from something shown on a screen or playing on a speaker.
Acknowledgements
This post reflects the combined work of Aliaksei Severyn, André Farias, Cheng-Chun Lee, Florian Thöle, Gabriel Carvajal, Gyorgy Gyepesi, Julien Cretin, Liana Marinescu, Martin Bölle, Patrick Siegler, Sebastian Krause, Victor Ähdel, Victoria Fossum, Vincent Zhao. We also thank Amar Subramanya, Dave Orr, Yury Pinsky for helpful discussions and support.





.gif)