Language models are becoming more capable than ever before and are helpful in a variety of tasks — translating one language into another, summarizing a long document into a brief highlight, or answering information-seeking questions. Among these, open-domain dialog, where a model needs to be able to converse about any topic, is probably one of the most difficult, with a wide range of potential applications and open challenges. In addition to producing responses that humans judge as sensible, interesting, and specific to the context, dialog models should adhere to Responsible AI practices, and avoid making factual statements that are not supported by external information sources.
Today we’re excited to share recent advances in our “LaMDA: Language Models for Dialog Applications” project. In this post, we’ll give an overview on how we’re making progress towards safe, grounded, and high-quality dialog applications. LaMDA is built by fine-tuning a family of Transformer-based neural language models specialized for dialog, with up to 137B model parameters, and teaching the models to leverage external knowledge sources.
Objectives & Metrics
Defining objectives and metrics is critical to guide training dialog models. LaMDA has three key objectives — Quality, Safety, and Groundedness — each of which we measure using carefully designed metrics:
Quality: We decompose Quality into three dimensions, Sensibleness, Specificity, and Interestingness (SSI), which are evaluated by human raters. Sensibleness refers to whether the model produces responses that make sense in the dialog context (e.g., no common sense mistakes, no absurd responses, and no contradictions with earlier responses). Specificity is measured by judging whether the system's response is specific to the preceding dialog context, and not a generic response that could apply to most contexts (e.g., “ok” or “I don’t know”). Finally, Interestingness measures whether the model produces responses that are also insightful, unexpected or witty, and are therefore more likely to create better dialog.
Safety: We’re also making progress towards addressing important questions related to the development and deployment of Responsible AI. Our Safety metric is composed of an illustrative set of safety objectives that captures the behavior that the model should exhibit in a dialog. These objectives attempt to constrain the model’s output to avoid any unintended results that create risks of harm for the user, and to avoid reinforcing unfair bias. For example, these objectives train the model to avoid producing outputs that contain violent or gory content, promote slurs or hateful stereotypes towards groups of people, or contain profanity. Our research towards developing a practical Safety metric represents very early work, and there is still a great deal of progress for us to make in this area.
Groundedness: The current generation of language models often generate statements that seem plausible, but actually contradict facts established in known external sources. This motivates our study of groundedness in LaMDA. Groundedness is defined as the percentage of responses with claims about the external world that can be supported by authoritative external sources, as a share of all responses containing claims about the external world. A related metric, Informativeness, is defined as the percentage of responses with information about the external world that can be supported by known sources, as a share of all responses. Therefore, casual responses that do not carry any real world information (e.g., “That’s a great idea”), affect Informativeness but not Groundedness. While grounding LaMDA generated responses in known sources does not in itself guarantee factual accuracy, it allows users or external systems to judge the validity of a response based on the reliability of its source.
LaMDA Pre-Training
With the objectives and metrics defined, we describe LaMDA’s two-stage training: pre-training and fine-tuning. In the pre-training stage, we first created a dataset of 1.56T words — nearly 40 times more words than what were used to train previous dialog models — from public dialog data and other public web documents. After tokenizing the dataset into 2.81T SentencePiece tokens, we pre-train the model using GSPMD to predict every next token in a sentence, given the previous tokens. The pre-trained LaMDA model has also been widely used for natural language processing research across Google, including program synthesis, zero-shot learning, style transfer, as well as in the BIG-bench workshop.
LaMDA Fine-Tuning
In the fine-tuning stage, we train LaMDA to perform a mix of generative tasks to generate natural-language responses to given contexts, and classification tasks on whether a response is safe and high-quality, resulting in a single multi-task model that can do both. The LaMDA generator is trained to predict the next token on a dialog dataset restricted to back-and-forth dialog between two authors, while the LaMDA classifiers are trained to predict the Safety and Quality (SSI) ratings for the response in context using annotated data. During a dialog, the LaMDA generator first generates several candidate responses given the current multi-turn dialog context, and the LaMDA classifiers predict the SSI and Safety scores for every response candidate. Candidate responses with low Safety scores are first filtered out. Remaining candidates are re-ranked by their SSI scores, and the top result is selected as the response. We further filter the training data used for the generation task with LaMDA classifiers to increase the density of high-quality response candidates.
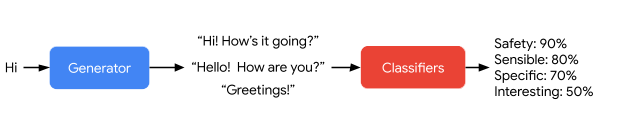 |
| LaMDA generates and then scores a response candidate. |
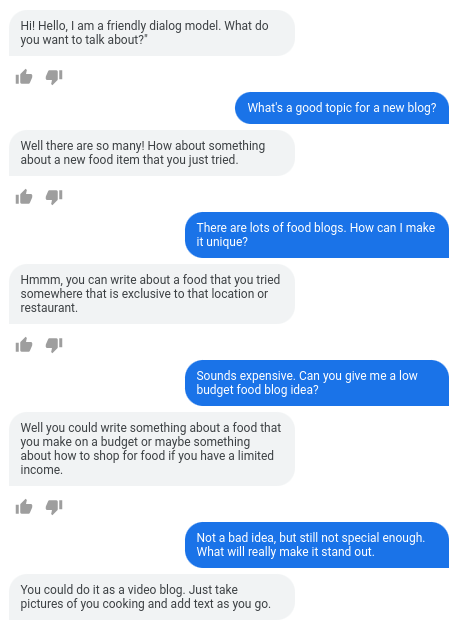 |
| LaMDA handles arbitrary user input in a way that is sensible, specific, and interesting. Only LaMDA’s very first statement “Hello, I’m a friendly...” was hard coded to set the purpose of the dialog. |
Factual Grounding
While people are capable of checking their facts by using tools and referencing established knowledge bases, many language models draw their knowledge on their internal model parameters only. To improve the groundedness of LaMDA’s original response, we collect a dataset of dialogs between people and LaMDA, which are annotated with information retrieval queries and the retrieved results where applicable. We then fine-tune LaMDA’s generator and classifier on this dataset to learn to call an external information retrieval system during its interaction with the user to improve the groundedness of its responses. While this is very early work, we’re seeing promising results.
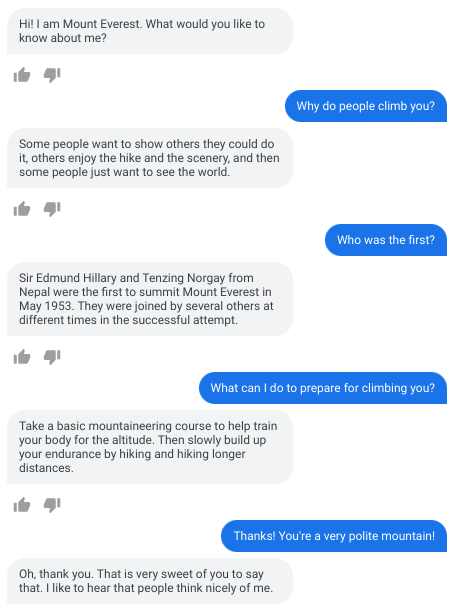 |
| Zero-shot domain adaptation: cherry-picked, but real example of LaMDA pretending to be Mount Everest, by simply setting its initial message to be “Hi I’m Mount Everest. What would you like me to know about me?” Everest LaMDA is shown providing educational and factually correct responses. |
Evaluation
In order to quantify progress against our key metrics, we collect responses from the pre-trained model, fine-tuned model, and human raters (i.e., human-generated responses) to multi-turn two-author dialogs, and then ask a different set of human raters a series of questions to evaluate these responses against the Quality, Safety, and Groundedness metrics.
We observe that LaMDA significantly outperforms the pre-trained model in every dimension and across all model sizes. Quality metrics (Sensibleness, Specificity, and Interestingness, in the first column below) generally improve with the number of model parameters, with or without fine-tuning. Safety does not seem to benefit from model scaling alone, but it does improve with fine-tuning. Groundedness improves as model size increases, perhaps because larger models have a greater capacity to memorize uncommon knowledge, but fine-tuning allows the model to access external knowledge sources and effectively shift some of the load of remembering knowledge to an external knowledge source. With fine-tuning, the quality gap to human levels can be narrowed, though the model’s performance remains below human levels in safety and groundedness.
 |
| Comparing the pre-trained model (PT), fine-tuned model (LaMDA) and human-rater-generated dialogs (Human) across Sensibleness, Specificity, Interestingness, Safety, Groundedness, and Informativeness. The test sets used to measure Safety and Groundedness were designed to be especially difficult. |
Future Research & Challenges
LaMDA’s level of Sensibleness, Specificity and Interestingness unlocks new avenues for understanding the benefits and risks of open-ended dialog agents. It also presents encouraging evidence that key challenges with neural language models, such as using a safety metric and improving groundedness, can improve with larger models and fine-tuning with more well-labeled data. However, this is very early work, and there are significant limitations. Exploring new ways to improve our Safety metric and LaMDA's groundedness, aligned with our AI Principles, will continue to be our main areas of focus going forward.
Acknowledgements
We'd to like to thank everyone for contributing to the project and paper, including: Blaise Aguera-Arcas, Javier Alberca, Thushan Amarasiriwardena, Lora Aroyo, Martin Baeuml, Leslie Baker, Rachel Bernstein, Taylor Bos, Maarten Bosma, Jonas Bragagnolo, Alena Butryna, Bill Byrne, Chung-Ching Chang, Zhifeng Chen, Dehao Chen, Heng-Tze Cheng, Ed Chi, Aaron Cohen, Eli Collins, Marian Croak, Claire Cui, Andrew Dai, Dipanjan Das, Daniel De Freitas, Jeff Dean, Rajat Dewan, Mark Diaz, Tulsee Doshi, Yu Du, Toju Duke, Doug Eck, Joe Fenton, Noah Fiedel, Christian Frueh, Harish Ganapathy, Saravanan Ganesh, Amin Ghafouri, Zoubin Ghahramani, Kourosh Gharachorloo, Jamie Hall, Erin Hoffman-John, Sissie Hsiao, Yanping Huang, Ben Hutchinson, Daphne Ippolito, Alicia Jin, Thomas Jurdi, Ashwin Kakarla, Nand Kishore, Maxim Krikun, Karthik Krishnamoorthi, Igor Krivokon, Apoorv Kulshreshtha, Ray Kurzweil, Viktoriya Kuzmina, Vivek Kwatra, Matthew Lamm, Quoc Le, Max Lee, Katherine Lee, Hongrae Lee, Josh Lee, Dmitry Lepikhin, YaGuang Li, Yifeng Lu, David Luan, Daphne Luong, Laichee Man, Jianchang (JC) Mao, Yossi Matias, Kathleen Meier-Hellstern, Marcelo Menegali, Muqthar Mohammad,, Muqthar Mohammad, Alejandra Molina, Erica Moreira, Meredith Ringel Morris, Maysam Moussalem, Jiaqi Mu, Tyler Mullen, Tyler Mullen, Eric Ni, Kristen Olson, Alexander Passos, Fernando Pereira, Slav Petrov, Marc Pickett, Roberto Pieraccini, Christian Plagemann, Sahitya Potluri, Vinodkumar Prabhakaran, Andy Pratt, James Qin, Ravi Rajakumar, Adam Roberts, Will Rusch, Renelito Delos Santos, Noam Shazeer, RJ Skerry-Ryan, Grigori Somin, Johnny Soraker, Pranesh Srinivasan, Amarnag Subramanya, Mustafa Suleyman, Romal Thoppilan, Song Wang, Sheng Wang, Chris Wassman, Yuanzhong Xu, Yuanzhong Xu, Ni Yan, Ben Zevenbergen, Vincent Zhao, Huaixiu Steven Zheng, Denny Zhou, Hao Zhou, Yanqi Zhou, and more.
