
Teaching mobile robots to navigate in complex outdoor environments is critical to real-world applications, such as delivery or search and rescue. However, this is also a challenging problem as the robot needs to perceive its surroundings, and then explore to identify feasible paths towards the goal. Another common challenge is that the robot needs to overcome uneven terrains, such as stairs, curbs, or rockbed on a trail, while avoiding obstacles and pedestrians. In our prior work, we investigated the second challenge by teaching a quadruped robot to tackle challenging uneven obstacles and various outdoor terrains.
In “IndoorSim-to-OutdoorReal: Learning to Navigate Outdoors without any Outdoor Experience”, we present our recent work to tackle the robotic challenge of reasoning about the perceived surroundings to identify a viable navigation path in outdoor environments. We introduce a learning-based indoor-to-outdoor transfer algorithm that uses deep reinforcement learning to train a navigation policy in simulated indoor environments, and successfully transfers that same policy to real outdoor environments. We also introduce Context-Maps (maps with environment observations created by a user), which are applied to our algorithm to enable efficient long-range navigation. We demonstrate that with this policy, robots can successfully navigate hundreds of meters in novel outdoor environments, around previously unseen outdoor obstacles (trees, bushes, buildings, pedestrians, etc.), and in different weather conditions (sunny, overcast, sunset).
PointGoal navigation
User inputs can tell a robot where to go with commands like “go to the Android statue”, pictures showing a target location, or by simply picking a point on a map. In this work, we specify the navigation goal (a selected point on a map) as a relative coordinate to the robot’s current position (i.e., “go to ∆x, ∆y”), this is also known as the PointGoal Visual Navigation (PointNav) task. PointNav is a general formulation for navigation tasks and is one of the standard choices for indoor navigation tasks. However, due to the diverse visuals, uneven terrains and long distance goals in outdoor environments, training PointNav policies for outdoor environments is a challenging task.
Indoor-to-outdoor transfer
Recent successes in training wheeled and legged robotic agents to navigate in indoor environments were enabled by the development of fast, scalable simulators and the availability of large-scale datasets of photorealistic 3D scans of indoor environments. To leverage these successes, we develop an indoor-to-outdoor transfer technique that enables our robots to learn from simulated indoor environments and to be deployed in real outdoor environments.
To overcome the differences between simulated indoor environments and real outdoor environments, we apply kinematic control and image augmentation techniques in our learning system. When using kinematic control, we assume the existence of a reliable low-level locomotion controller that can control the robot to precisely reach a new location. This assumption allows us to directly move the robot to the target location during simulation training through a forward Euler integration and relieves us from having to explicitly model the underlying robot dynamics in simulation, which drastically improves the throughput of simulation data generation. Prior work has shown that kinematic control can lead to better sim-to-real transfer compared to a dynamic control approach, where full robot dynamics are modeled and a low-level locomotion controller is required for moving the robot.
| Left Kinematic control; Right: Dynamic control |
We created an outdoor maze-like environment using objects found indoors for initial experiments, where we used Boston Dynamics' Spot robot for test navigation. We found that the robot could navigate around novel obstacles in the new outdoor environment.
| The Spot robot successfully navigates around obstacles found in indoor environments, with a policy trained entirely in simulation. |
However, when faced with unfamiliar outdoor obstacles not seen during training, such as a large slope, the robot was unable to navigate the slope.
| The robot is unable to navigate up slopes, as slopes are rare in indoor environments and the robot was not trained to tackle it. |
To enable the robot to walk up and down slopes, we apply an image augmentation technique during the simulation training. Specifically, we randomly tilt the simulated camera on the robot during training. It can be pointed up or down within 30 degrees. This augmentation effectively makes the robot perceive slopes even though the floor is level. Training on these perceived slopes enables the robot to navigate slopes in the real-world.
| By randomly tilting the camera angle during training in simulation, the robot is now able to walk up and down slopes. |
Since the robots were only trained in simulated indoor environments, in which they typically need to walk to a goal just a few meters away, we find that the learned network failed to process longer-range inputs — e.g., the policy failed to walk forward for 100 meters in an empty space. To enable the policy network to handle long-range inputs that are common for outdoor navigation, we normalize the goal vector by using the log of the goal distance.
Context-Maps for complex long-range navigation
Putting everything together, the robot can navigate outdoors towards the goal, while walking on uneven terrain, and avoiding trees, pedestrians and other outdoor obstacles. However, there is still one key component missing: the robot’s ability to plan an efficient long-range path. At this scale of navigation, taking a wrong turn and backtracking can be costly. For example, we find that the local exploration strategy learned by standard PointNav policies are insufficient in finding a long-range goal and usually leads to a dead end (shown below). This is because the robot is navigating without context of its environment, and the optimal path may not be visible to the robot from the start.
| Navigation policies without context of the environment do not handle complex long-range navigation goals. |
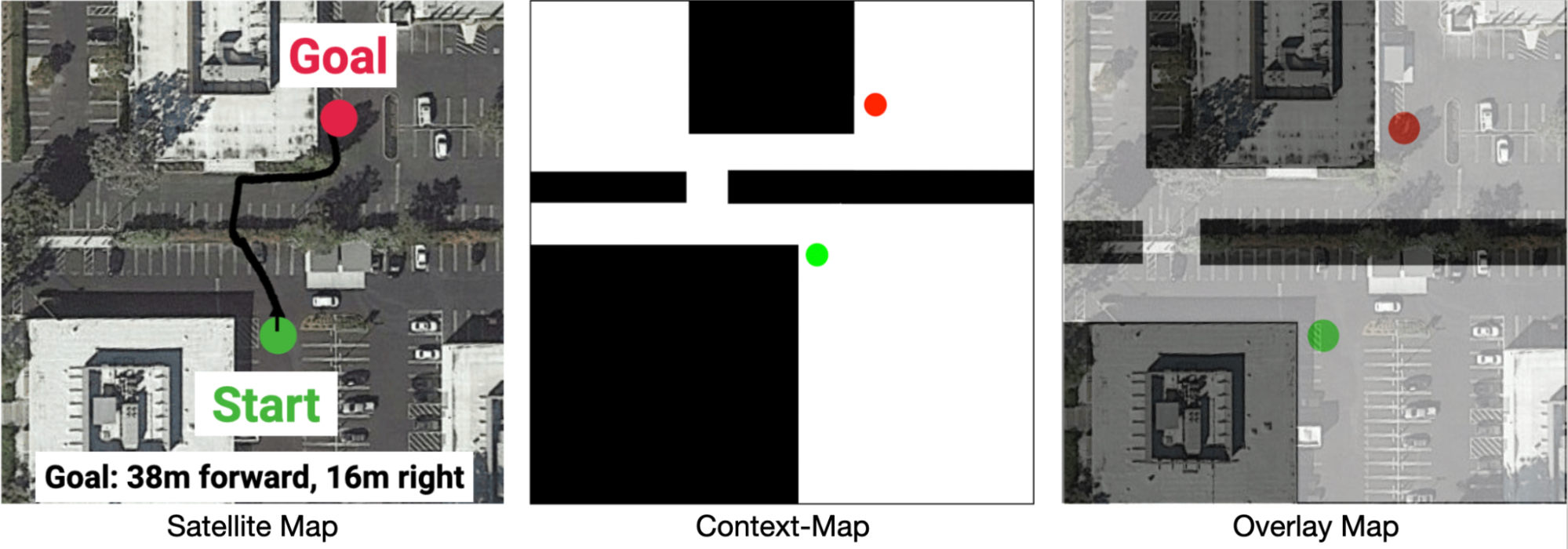
To enable the robot to take the context into consideration and purposefully plan an efficient path, we provide a Context-Map (a binary image that represents a top-down occupancy map of the region that the robot is within) as additional observations for the robot. An example Context-Map is given below, where the black region denotes areas occupied by obstacles and white region is walkable by the robot. The green and red circle denotes the start and goal location of the navigation task. Through the Context-Map, we can provide hints to the robot (e.g., the narrow opening in the route below) to help it plan an efficient navigation route. In our experiments, we create the Context-Map for each route guided by Google Maps satellite images. We denote this variant of PointNav with environmental context, as Context-Guided PointNav.
 |
| Example of the Context-Map (right) for a navigation task (left). |
It is important to note that the Context-Map does not need to be accurate because it only serves as a rough outline for planning. During navigation, the robot still needs to rely on its onboard cameras to identify and adapt its path to pedestrians, which are absent on the map. In our experiments, a human operator quickly sketches the Context-Map from the satellite image, masking out the regions to be avoided. This Context-Map, together with other onboard sensory inputs, including depth images and relative position to the goal, are fed into a neural network with attention models (i.e., transformers), which are trained using DD-PPO, a distributed implementation of proximal policy optimization, in large-scale simulations.
 |
| The Context-Guided PointNav architecture consists of a 3-layer convolutional neural network (CNN) to process depth images from the robot's camera, and a multilayer perceptron (MLP) to process the goal vector. The features are passed into a gated recurrent unit (GRU). We use an additional CNN encoder to process the context-map (top-down map). We compute the scaled dot product attention between the map and the depth image, and use a second GRU to process the attended features (Context Attn., Depth Attn.). The output of the policy are linear and angular velocities for the Spot robot to follow. |
Results
We evaluate our system across three long-range outdoor navigation tasks. The provided Context-Maps are rough, incomplete environment outlines that omit obstacles, such as cars, trees, or chairs.
With the proposed algorithm, our robot can successfully reach the distant goal location 100% of the time, without a single collision or human intervention. The robot was able to navigate around pedestrians and real-world clutter that are not present on the context-map, and navigate on various terrain including dirt slopes and grass.
Route 1
 |
Route 2
 |
Route 3
 |
Conclusion
This work opens up robotic navigation research to the less explored domain of diverse outdoor environments. Our indoor-to-outdoor transfer algorithm uses zero real-world experience and does not require the simulator to model predominantly-outdoor phenomena (terrain, ditches, sidewalks, cars, etc). The success in the approach comes from a combination of a robust locomotion control, low sim-to-real gap in depth and map sensors, and large-scale training in simulation. We demonstrate that providing robots with approximate, high-level maps can enable long-range navigation in novel outdoor environments. Our results provide compelling evidence for challenging the (admittedly reasonable) hypothesis that a new simulator must be designed for every new scenario we wish to study. For more information, please see our project page.
Acknowledgements
We would like to thank Sonia Chernova, Tingnan Zhang, April Zitkovich, Dhruv Batra, and Jie Tan for advising and contributing to the project. We would also like to thank Naoki Yokoyama, Nubby Lee, Diego Reyes, Ben Jyenis, and Gus Kouretas for help with the robot experiment setup.