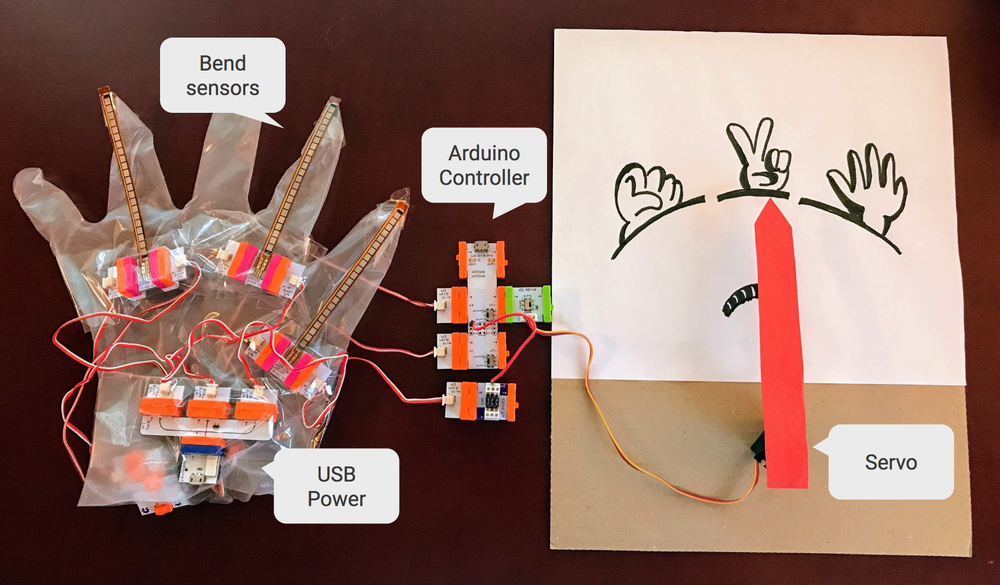
Google is an artificial intelligence-first company. Machine Learning (ML) and Cloud are deeply embedded in our product strategies and have been crucial thus far in our efforts to tackle some of humanity's greatest challenges - like bringing high-quality, affordable, and specialized healthcare to people globally.
In that spirit, we're excited to announce the first four startups to join Launchpad Studio, our 6-month mentorship program tailored to help applied-ML startups build great products using the most advanced tools and technologies available. Working side-by-side with experts from across Google product and research teams - including Google Cloud, Verily, X, Brain, ML Research -, we intend to support these startups on their journey to build successful applications, and explore leveraging Google Cloud Platform, TensorFlow, Android, and other Google platforms. Launchpad Studio has also enlisted the expertise of a number of top industry practitioners and thought leaders to ensure Studio startups are successful in practice and long-term.
These four startups were selected based on the novel ways they've found to apply ML to important challenges in the Healthcare industry. Namely:
- Reducing doctor burnout and increasing doctor productivity (Augmedix)
- Regaining movement in paralyzed limbs (BrainQ)
- Accelerating clinical trials and enabling value-based healthcare (Byteflies)
- Detecting sepsis (CytoVale)
Let's take a closer look:
Reducing Doctor Burnout and Increasing Doctor Productivity
Numerous studies have shown that primary care physicians currently spend about half of their workday on the computer, documenting in the electronic health records (EHR).
Augmedix is on a mission to reclaim this time and repurpose it for what matters most: patient care. When doctors use the service by wearing Alphabet's Glass hardware, their documentation and administrative load is almost entirely alleviated. This saves doctors 2-3 hours per day and dramatically improves the doctor-patient experience.
Augmedix has started leveraging advances in deep learning and natural language understanding to accelerate these efficiencies and offer additional value that further improves patient care.
Regaining Movement in Paralyzed Limbs
Motor disability following neuro-disorders such as stroke, spinal cord injury, and traumatic brain injury affects tens of millions of people each year worldwide.
BrainQ's mission is to help these patients back on their feet, restoring their ability to perform activities of daily living. BrainQ is currently conducting clinical trials in leading hospitals in Israel.
The company is developing a medical device that utilizes artificial intelligence tools to identify high resolution spectral patterns in patient's brain waves, observed in electroencephalogram (EEG) sensors. These patterns are then translated into a personalized electromagnetic treatment protocol aimed at facilitating targeted neuroplasticity and enhancing patient's recovery.
Accelerating Clinical Trials and Enabling Value-Based Healthcare
Today, sensors are making it easier to collect data about health and diseases. However building a new wearable health application that is clinically validated and end-user friendly is still a daunting task. Byteflies' modular platform makes this whole process much easier and cost-effective. Through their medical and signal processing expertise, Byteflies has made advances in the interpretation of multiple synchronized vital signs. This multimodal high-resolution vital sign data is very useful for healthcare and clinical trial applications. With that level of data ingestion comes a great need for automated data processing. Byteflies plans to use ML to transform these data streams into actionable, personalized, and medically-relevant data.
Early Sepsis Detection
Research suggests that sepsis kills more Americans than breast cancer, prostate cancer, and AIDS combined. Fortunately, sepsis can often be quickly mitigated if caught early on in patient care.
CytoVale is developing a medical diagnostics platform based on cell mechanics, initially for use in early detection of sepsis in the emergency room setting. It analyzes thousands of cells' mechanical properties using ultra high speed video to diagnose disease in a few minutes. Their technology also has applications in immune activation, cancer detection, research tools, and biodefense.
CytoVale is leveraging recent advances in ML and computer vision in conjunction with their unique measurement approach to facilitate this early detection of sepsis.
More about the Program
Each startup will get tailored, equity-free support, with the goal of successfully completing a ML-focused project during the term of the program. To support this process, we provide resources, including deep engagement with engineers in Google Cloud, Google X, and other product teams, as well as Google Cloud credits. We also include both Google Cloud Platform and GSuite training in our engagement with all Studio startups.
Join Us
Based in San Francisco, Launchpad Studio is a fully tailored product development acceleration program that matches top ML startups and experts from Silicon Valley with the best of Google - its people, network, and advanced technologies - to help accelerate applied ML and AI innovation. The program's mandate is to support the growth of the ML ecosystem, and to develop product methodologies for ML.
Launchpad Studio is looking to work with the best and most game-changing ML startups from around the world. While we're currently focused on working with startups in the Healthcare and Biotech space, we'll soon be announcing other industry verticals, and any startup applying AI / ML technology to a specific industry vertical can apply on a rolling-basis.