There are casual ramen fans and then there are ramen lovers. There are people who are all tonkatsu all the time, and others who swear by tsukemen. And then there’s machine learning, which—based on a recent case study out of Japan—might be the biggest ramen aficionado of them all.
Recently, data scientist Kenji Doi used machine learning models and AutoML Vision to classify bowls of ramen and identify the exact shop each bowl is made at, out of 41 ramen shops, with 95 percent accuracy. Sounds crazy (also delicious), especially when you see what these bowls look like:

With 41 locations around Tokyo, Ramen Jiro is one of the most popular restaurant franchises in Japan, because of its generous portions of toppings, noodles and soup served at low prices. They serve the same basic menu at each shop, and as you can see above, it's almost impossible for a human (especially if you're new to Ramen Jiro) to tell what shop each bowl is made at.
But Kenji thought deep learning could discern the minute details that make one shop’s bowl of ramen different from the next. He had already built a machine learning model to classify ramen, but wanted to see if AutoML Vision could do it more efficiently.
AutoML Vision creates customized ML models automatically—to identify animals in the wild, or recognize types of products to improve an online store, or in this case classify ramen. You don’t have to be a data scientist to know how to use it—all you need to do is upload well-labeled images and then click a button. In Kenji’s case, he compiled a set of 48,000 photos of bowls of soup from Ramen Jiro locations, along with labels for each shop, and uploaded them to AutoML Vision. The model took about 24 hours to train, all automatically (although a less accurate, “basic” mode had a model ready in just 18 minutes). The results were impressive: Kenji’s model got 94.5 percentaccuracy on predicting the shop just from the photos.
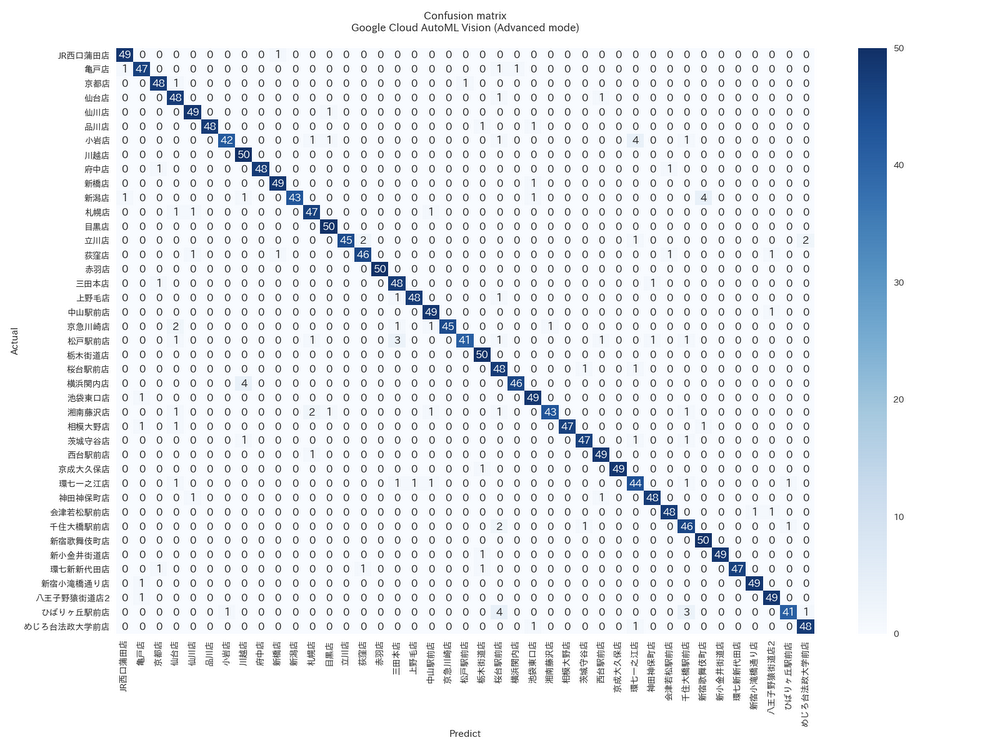
Confusion matrix of Ramen Jiro shop classifier by AutoML Vision (Advanced mode). Row = actual shop, column = predicted shop. You can see AutoML Vision incorrectly identified the restaurant location in only a couple of instances for each test case.
AutoML Vision is designed for people without ML expertise, but it also speeds things up dramatically for experts. Building a model for ramen classification from scratch would be a time-consuming process requiring multiple steps—labeling, hyperparameter tuning, multiple attempts with different neural net architectures, and even failed training runs—and experience as a data scientist. As Kenji puts it, “With AutoML Vision, a data scientist wouldn’t need to spend a long time training and tuning a model to achieve the best results. This means businesses could scale their AI work even with a limited number of data scientists." We wrote about another recent example of AutoML Vision at work in this Big Data blog post, which also has more technical details on Kenji’s model.
As for how AutoML detects the differences in ramen, it’s certainly not from the taste. Kenji’s first hypothesis was that the model was looking at the color or shape of the bowl or table—but that seems unlikely, since the model was highly accurate even when each shop used the same bowl and table design. Kenji’s new theory is that the model is accurate enough to distinguish very subtle differences between cuts of the meat, or the way toppings are served. He plans on continuing to experiment with AutoML to see if his theories are true. Sounds like a project that might involve more than a few bowls of ramen. Slurp on.