When patients get admitted to a hospital, they have many questions about what will happen next. When will I be able to go home? Will I get better? Will I have to come back to the hospital? Having precise answers to those questions helps doctors and nurses make care better, safer, and faster — if a patient’s health is deteriorating, doctors could be sent proactively to act before things get worse.
Predicting what will happen next is a natural application of machine learning. We wondered if the same types of machine learning that predict traffic during your commute or the next word in a translation from English to Spanish could be used for clinical predictions. For predictions to be useful in practice they should be, at least:
- Scalable: Predictions should be straightforward to create for any important outcome and for different hospital systems. Since healthcare data is very complicated and requires much data wrangling, this requirement is not straightforward to satisfy.
- Accurate: Predictions should alert clinicians to problems but not distract them with false alarms. With the widespread adoption of electronic health records, we set out to use that data to create more accurate prediction models.
Scalability
Electronic health records (EHRs) are tremendously complicated. Even a temperature measurement has a different meaning depending on if it’s taken under the tongue, through your eardrum, or on your forehead. And that's just a simple vital sign. Moreover, each health system customizes their EHR system, making the data collected at one hospital look different than data on a similar patient receiving similar care at another hospital. Before we could even apply machine learning, we needed a consistent way to represent patient records, which we built on top of the open Fast Healthcare Interoperability Resources (FHIR) standard as described in an earlier blog post.
Once in a consistent format, we did not have to manually select or harmonize the variables to use. Instead, for each prediction, a deep learning model reads all the data-points from earliest to most recent and then learns which data helps predict the outcome. Since there are thousands of data points involved, we had to develop some new types of deep learning modeling approaches based on recurrent neural networks (RNNs) and feedforward networks.
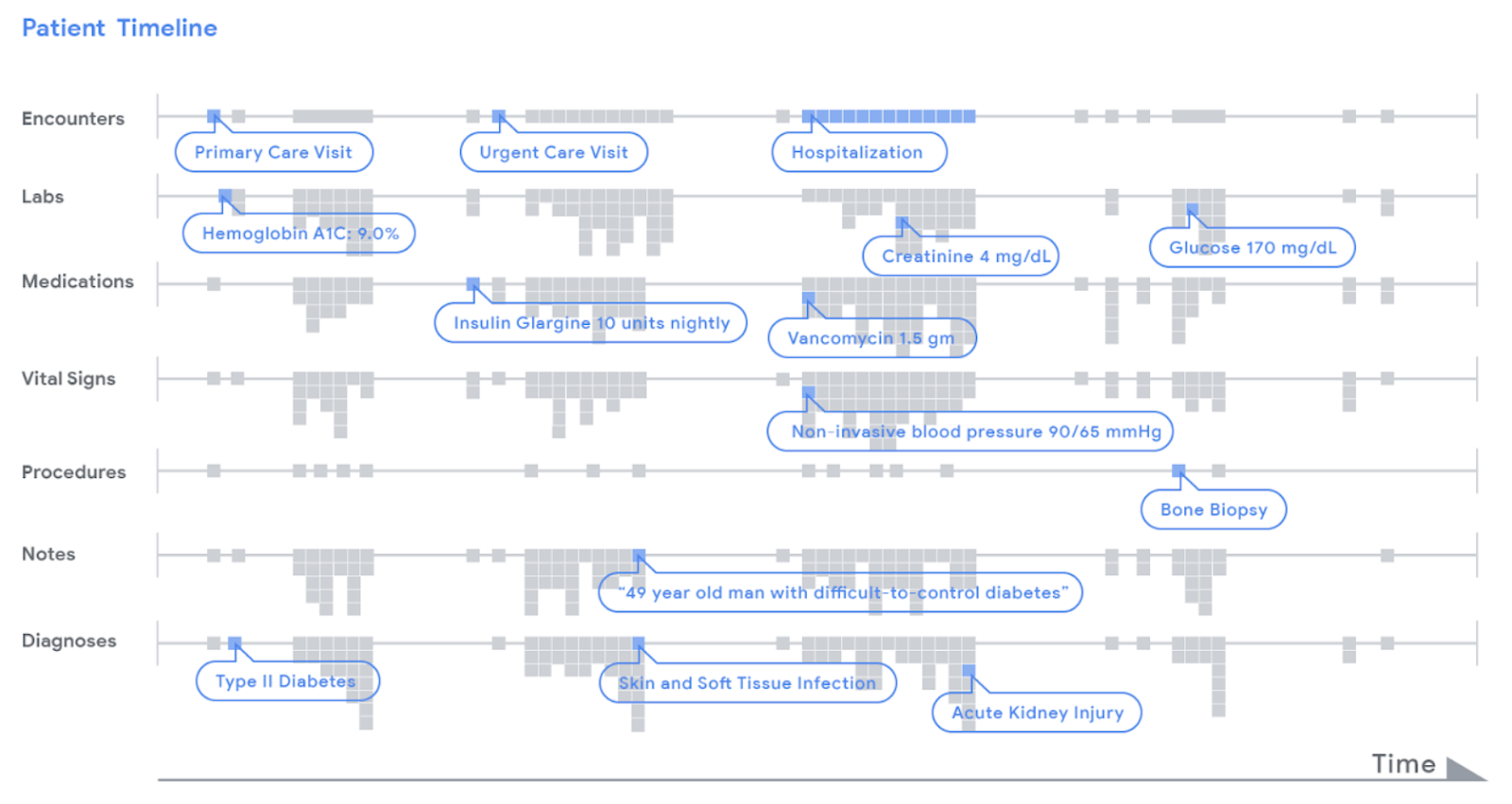 |
| Data in a patient's record is represented as a timeline. For illustrative purposes, we display various types of clinical data (e.g. encounters, lab tests) by row. Each piece of data, indicated as a little grey dot, is stored in FHIR, an open data standard that can be used by any healthcare institution. A deep learning model analyzed a patient's chart by reading the timeline from left to right, from the beginning of a chart to the current hospitalization, and used this data to make different types of predictions. |
Prediction Accuracy
The most common way to assess accuracy is by a measure called the area-under-the-receiver-operator curve, which measures how well a model distinguishes between a patient who will have a particular future outcome compared to one who will not. In this metric, 1.00 is perfect, and 0.50 is no better than random chance, so higher numbers mean the model is more accurate. By this measure, the models we reported in the paper scored 0.86 in predicting if patients will stay long in the hospital (traditional logistic regression scored 0.76); they scored 0.95 in predicting inpatient mortality (traditional methods were 0.86), and they scored 0.77 in predicting unexpected readmissions after patients are discharged (traditional methods were 0.70). These gains were statistically significant.
We also used these models to identify the conditions for which the patients were being treated. For example, if a doctor prescribed ceftriaxone and doxycycline for a patient with an elevated temperature, fever and cough, the model could identify these as signals that the patient was being treated for pneumonia. We emphasize that the model is not diagnosing patients — it picks up signals about the patient, their treatments and notes written by their clinicians, so the model is more like a good listener than a master diagnostician.
An important focus of our work includes the interpretability of the deep learning models used. An “attention map” of each prediction shows the important data points considered by the models as they make that prediction. We show an example as a proof-of-concept and see this as an important part of what makes predictions useful for clinicians.
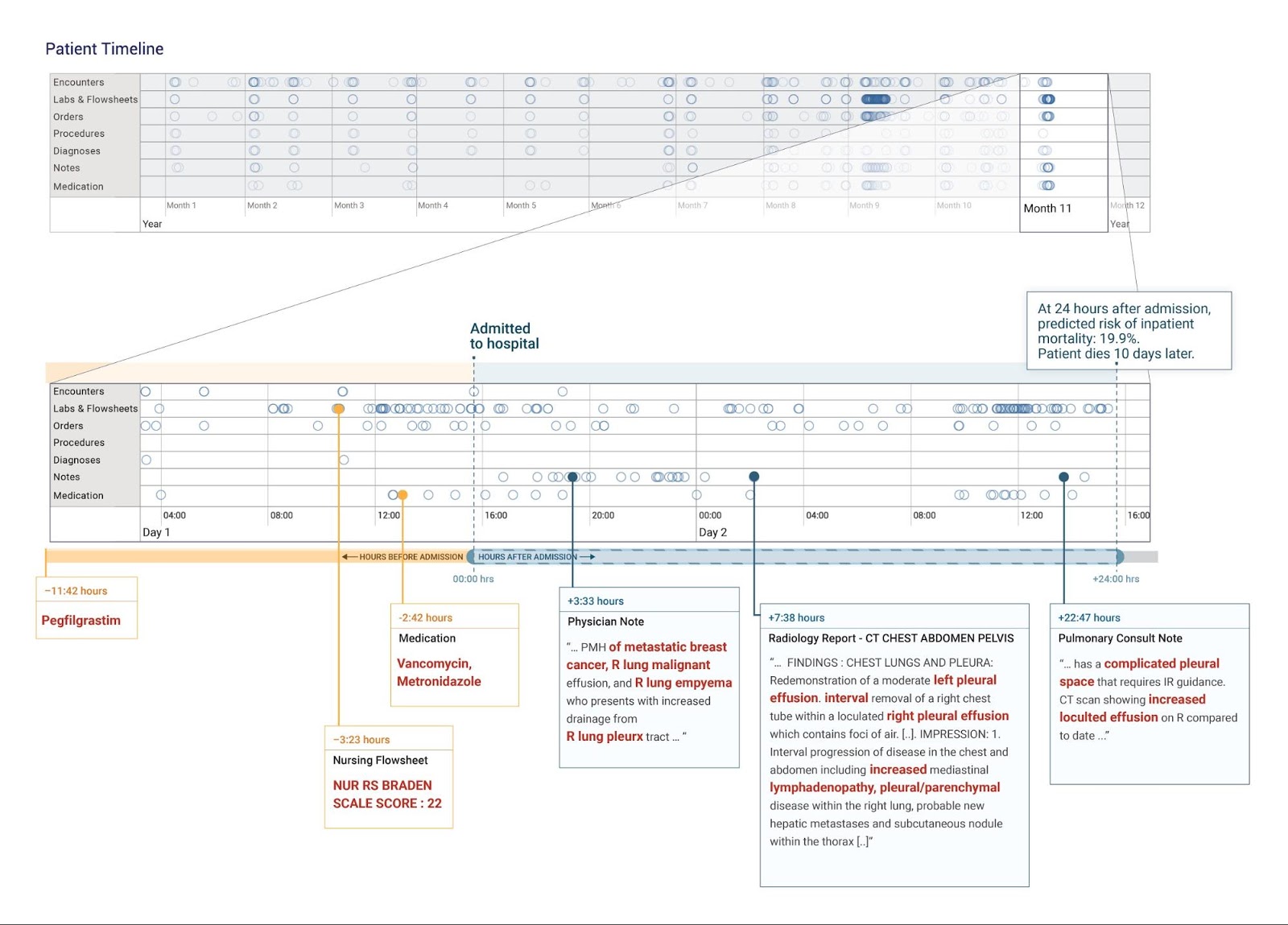 |
| A deep learning model was used to render a prediction 24 hours after a patient was admitted to the hospital. The timeline (top of figure) contains months of historical data and the most recent data is shown enlarged in the middle. The model "attended" to information highlighted in red that was in the patient's chart to "explain" its prediction. In this case-study, the model highlighted pieces of information that make sense clinically. Figure from our paper. |
The results of this work are early and on retrospective data only. Indeed, this paper represents just the beginning of the work that is needed to test the hypothesis that machine learning can be used to make healthcare better. Doctors are already inundated with alerts and demands on their attention — could models help physicians with tedious, administrative tasks so they can better focus on the patient in front of them or ones that need extra attention? Can we help patients get high-quality care no matter where they seek it? We look forward to collaborating with doctors and patients to figure out the answers to these questions and more.




