It wasn't long ago that Apache Hadoop MapReduce was the obvious engine for all things big data, then Apache Spark came along, and more recently Apache Flink, a streaming-native engine. Unlike upgrading hardware, adopting these more modern engines has generally required rewriting pipelines to adopt engine-specific APIs, often with different implementations for streaming and batch scenarios. This can mean throwing away user code that had just been weathered enough to be considered (mostly) bug-free, and replacing it with immature new code. All of this just because the data pipelines needed to scale better, or have lower latency, or run more cheaply, or complete faster.
Adjusting such aspects should not require throwing away well-tested business logic. You should be able to move your application or data pipeline to the appropriate engine, or to the appropriate environment (e.g., from on-prem to cloud) while keeping the business logic intact. But, to do this, two conditions need to be met. First, you need a portable SDK, which can produce programs that can execute on one of many pluggable execution environments. Second, that SDK has to expose a programming model whose semantics are focused on your workload and not on the capabilities of the underlying engine. For example, MapReduce as a programming model doesn’t meet the bill (even though MapReduce as an execution method might be appropriate in some cases) because it cannot productively express low-latency computations.
Google designed Dataflow specifically to address both of these issues. The Dataflow Java SDK has been architected to support pluggable “runners” to connect to execution engines, of which four currently exist: data Artisans created one for Apache Flink, Cloudera did it for Apache Spark, and Google implemented a single-node local execution runner as well as one for Google’s hosted Cloud Dataflow service.
That portability is possible because the Dataflow programming model is focused on real-life streaming semantics, like real event time (as opposed to the time at which the event arrives), and real sessions (as opposed to whatever arbitrary boundary the batch cycle imposes). This allows Dataflow programs to execute in either batch or stream mode as needed, and to switch from one pluggable execution engine to the other without needing to be rewritten.
Today we’re taking another step in this collaboration. Along with participants from Cloudera, data Artisans, Talend, Cask and PayPal, we sent a proposal for Dataflow to become an Apache Software Foundation (ASF) Incubator project. In this proposal the Dataflow model, Java SDK, and runners will be bundled into one incubating project with the Python SDK joining the project in the future. We believe this proposal is a step towards the ability to define one data pipeline for multiple processing needs, without tradeoffs, which can be run in a number of runtimes, on-premise, in the cloud, or locally. Google Cloud Dataflow will remain as a “no-ops” managed service to execute Dataflow pipelines quickly and cost-effectively in Google Cloud Platform.
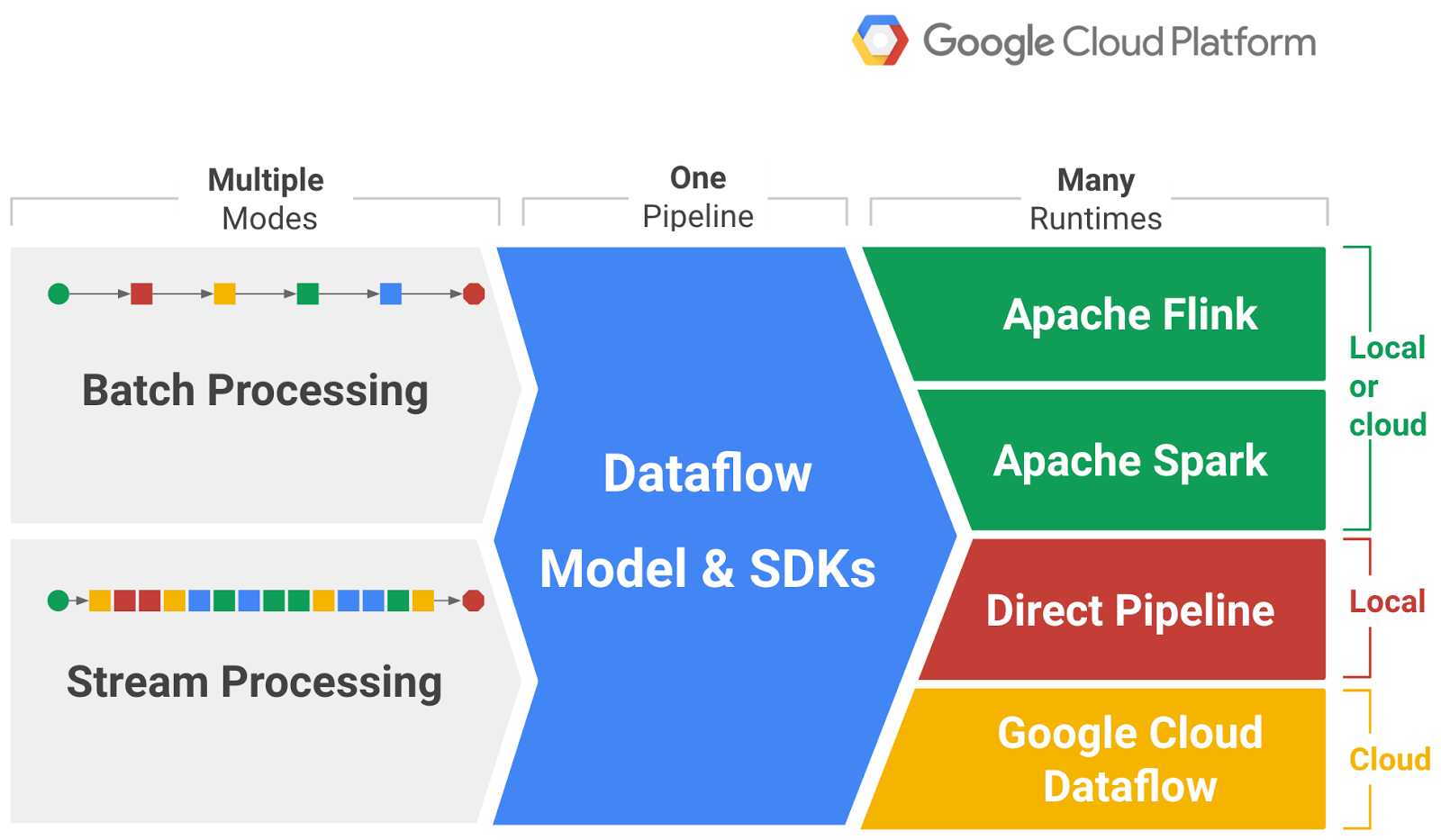
With Dataflow, you can write one portable data pipeline, which can be used for either batch or stream, and executed in a number of runtimes including Flink, Spark, Google Cloud Dataflow or the local direct pipeline.
We're excited to propose Dataflow as an Apache Incubator project because we believe the Dataflow model, SDK and runners offer a number of unique features in the open-source data space.
- Pipeline first, runtime second – With the Dataflow model and SDKs, you focus first on defining your data pipelines, not how they'll run or the characteristics of the particular runner executing them.
- Portability – Data pipelines are portable across a number of runtime engines. You can choose a runtime based on any number of considerations, such as performance, cost or scalability.
- Unified model – Batch and streaming are integrated into a unified model with powerful semantics, such as windowing, ordering and triggering.
- Development tooling – The Dataflow SDK contains the tools you need to create portable data pipelines quickly and easily using open-source languages, libraries and tools.
To understand the power of the Dataflow model, we recommend this article on the O’Reilly Radar: The World Beyond Batch: Streaming 102. For more information about Dataflow, you can also:
- Watch the Dataflow overview presentation from the 2015 @Scale Conference
- Take a look at the Dataflow Java SDK GitHub repository, which would be moved to the Apache Software Foundation as a part of our proposal
- Read the Dataflow model VLDB paper, which provides a detailed overview of the Dataflow model
We're grateful to the Apache Software Foundation and community for their consideration of the Dataflow proposal and look forward to actively participating in open development of Dataflow.
- Posted by Frances Perry (Software Engineer) and James Malone (Product Manager)
