The emergence of digital technologies has transformed decision making across commercial sectors such as airlines, online retailing, and internet advertising. Today, real-time decisions need to be repeatedly made in highly uncertain and rapidly changing environments. Moreover, organizations usually have limited resources, which need to be efficiently allocated across decisions. Such problems are referred to as online allocation problems with resource constraints, and applications abound. Some examples include:
- Bidding with Budget Constraints: Advertisers increasingly purchase ad slots using auction-based marketplaces such as search engines and ad exchanges. A typical advertiser can participate in a large number of auctions in a given month. Because the supply in these marketplaces is uncertain, advertisers set budgets to control their total spend. Therefore, advertisers need to determine how to optimally place bids while limiting total spend and maximizing conversions.
- Dynamic Ad Allocation: Publishers can monetize their websites by signing deals with advertisers guaranteeing a number of impressions or by auctioning off slots in the open market. To make this choice, publishers need to trade off, in real-time, the short-term revenue from selling slots in the open market and the long-term benefits of delivering good quality spots to reservation ads.
- Airline Revenue Management: Planes have a limited number of seats that need to be filled up as much as possible before a flight’s departure. But demand for flights changes over time and airlines would like to sell airline tickets to the customers who are willing to pay the most. Thus, airlines have increasingly adopted sophisticated automated systems to manage the pricing and availability of airline tickets.
- Personalized Retailing with Limited Inventories: Online retailers can use real-time data to personalize their offerings to customers who visit their store. Because product inventory is limited and cannot be easily replenished, retailers need to dynamically decide which products to offer and at what price to maximize their revenue while satisfying their inventory constraints.
The common feature of these problems is the presence of resource constraints (budgets, contractual obligations, seats, or inventory, respectively in the examples above) and the need to make dynamic decisions in environments with uncertainty. Resource constraints are challenging because they link decisions across time — e.g., in the bidding problem, bidding too high early can leave advertisers with no budget, and thus missed opportunities later. Conversely, bidding too conservatively can result in a low number of conversions or clicks.
 |
| Two central resource allocation problems faced by advertisers and publishers in internet advertising markets. |
In this post, we discuss state-of-the-art algorithms that can help maximize goals in dynamic, resource-constrained environments. In particular, we have recently developed a new class of algorithms for online allocation problems, called dual mirror descent, that are simple, robust, and flexible. Our papers have appeared in Operations Research, ICML’20, and ICML’21, and we have ongoing work to continue progress in this space. Compared to existing approaches, dual mirror descent is faster as it does not require solving auxiliary optimization problems, is more flexible because it can handle many applications across different sectors with minimal modifications, and is more robust as it enjoys remarkable performance under different environments.
Online Allocation Problems
In an online allocation problem, a decision maker has a limited amount of total resources (B) and receives a certain number of requests over time (T). At any point in time (t), the decision maker receives a reward function (ft) and resource consumption function (bt), and takes an action (xt). The reward and resource consumption functions change over time and the objective is to maximize the total reward within the resource constraints. If all the requests were known in advance, then an optimal allocation could be obtained by solving an offline optimization problem for how to maximize the reward function over time within the resource constraints1.
The optimal offline allocation cannot be implemented in practice because it requires knowing future requests. However, this is still useful for framing the goal of online allocation problems: to design an algorithm whose performance is as close to optimal as possible without knowing future requests.
Achieving the Best of Many Worlds with Dual Mirror Descent
A simple, yet powerful idea to handle resource constraints is introducing “prices” for the resources, which enables accounting for the opportunity cost of consuming resources when making decisions. For example, selling a seat on a plane today means it can’t be sold tomorrow. These prices are useful as an internal accounting system of the algorithm. They serve the purpose of coordinating decisions at different moments in time and allow decomposing a complex problem with resource constraints into simpler subproblems: one per time period with no resource constraints. For example, in a bidding problem, the prices capture an advertiser’s opportunity cost of consuming one unit of budget and allow the advertiser to handle each auction as an independent bidding problem.
This reframes the online allocation problem as a problem of pricing resources to enable optimal decision making. The key innovation of our algorithm is using machine learning to predict optimal prices in an online fashion: we choose prices dynamically using mirror descent, a popular optimization algorithm for training machine learning predictive models. Because prices for resources are referred to as "dual variables" in the field of optimization, we call the resulting algorithm dual mirror descent.
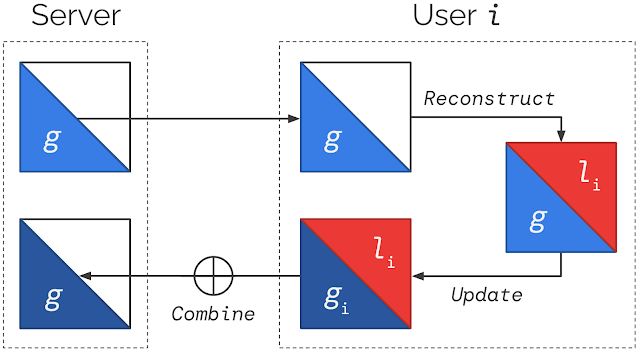
The algorithm works sequentially by assuming uniform resource consumption over time is optimal and updating the dual variables after each action. It starts at a moment in time (t) by taking an action (xt) that maximizes the reward minus the opportunity cost of consuming resources (shown in the top gray box below). The action (e.g., how much to bid or which ad to show) is implemented if there are enough resources available. Then, the algorithm computes the error in the resource consumption (gt), which is the difference between uniform consumption over time and the actual resource consumption (below in the third gray box). A new dual variable for the next time period is computed using mirror descent based on the error, which then informs the next action. Mirror descent seeks to make the error as close as possible to zero, improving the accuracy of its estimate of the dual variable, so that resources are consumed uniformly over time. While the assumption of uniform resource consumption may be surprising, it helps avoid missing good opportunities and often aligns with commercial goals so is effective. Mirror descent also allows a variety of update rules; more details are in the paper.
 |
| An overview of the dual mirror descent algorithm. |
By design, dual mirror descent has a self-correcting feature that prevents depleting resources too early or waiting too long to consume resources and missing good opportunities. When a request consumes more or less resources than the target, the corresponding dual variable is increased or decreased. When resources are then priced higher or lower, future actions are chosen to consume resources more conservatively or aggressively.
This algorithm is easy to implement, fast, and enjoys remarkable performance under different environments. These are some salient features of our algorithm:
- Existing methods require periodically solving large auxiliary optimization problems using past data. In contrast, this algorithm does not need to solve any auxiliary optimization problem and has a very simple rule to update the dual variables, which, in many cases, can be run in linear time complexity. Thus, it is appealing for many real-time applications that require fast decisions.
- There are minimal requirements on the structure of the problem. Such flexibility allows dual mirror descent to handle many applications across different sectors with minimal modifications. Moreover, our algorithms are flexible since they accommodate different objectives, constraints, or regularizers. By incorporating regularizers, decision makers can include important objectives beyond economic efficiency, such as fairness.
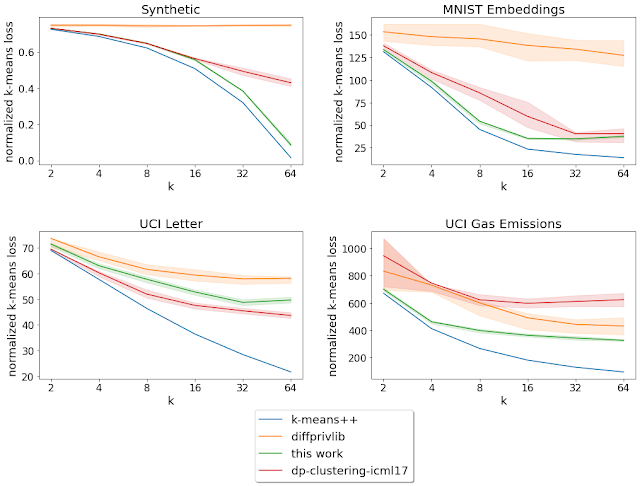
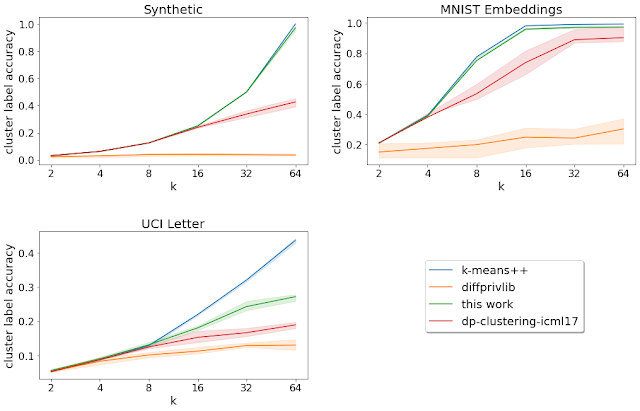
- Existing algorithms for online allocation problems are tailored for either adversarial or stochastic input data. Algorithms for adversarial inputs are robust as they make almost no assumptions on the structure of the data but, in turn, obtain performance guarantees that are too pessimistic in practice. On the other hand, algorithms for stochastic inputs enjoy better performance guarantees by exploiting statistical patterns in the data but can perform poorly when the model is misspecified. Dual mirror descent, however, attains performance close to optimal in both stochastic and adversarial input models while being oblivious to the structure of the input model. Compared to existing work on simultaneous approximation algorithms, our method is more general, applies to a wide range of problems, and requires no forecasts. Below is a comparison of our algorithm to other state-of-the-art methods. Results are based on synthetic data for an ad allocation problem.
 |
| Performance of dual mirror descent, a training based method, and an adversarial method relative to the optimal offline solution. Lower values indicate performance closer to the optimal offline allocation. Results are generated using synthetic experiments based on public data for an ad allocation problem. |
Conclusion
In this post we introduced dual mirror descent, an algorithm for online allocation problems that is simple, robust, and flexible. It is particularly notable that after a long line of work in online allocation algorithms, dual mirror descent provides a way to analyze a wider range of algorithms with superior robustness priorities compared to previous techniques. Dual mirror descent has a wide range of applications across several commercial sectors and has been used over time at Google to help advertisers capture more value through better algorithmic decision making. We are also exploring further work related to mirror descent and its connections to PI controllers.
Acknowledgements
We would like to thank our co-authors Haihao Lu and Balu Sivan, and Kshipra Bhawalkar for their exceptional support and contributions. We would also like to thank our collaborators in the ad quality team and market algorithm research.
1Formalized in the equation below: ↩
 |