Graphs are useful theoretical representations of the connections between groups of entities, and have been used for a variety of purposes in data science, from ranking web pages by popularity and mapping out social networks, to assisting with navigation. In many cases, such applications require the processing of graphs containing hundreds of billions of edges, which is far too large to be processed on a single consumer-grade machine. A typical approach to scaling graph algorithms is to run in a distributed setting, i.e., to partition the data (and the algorithm) among multiple computers to perform the computation in parallel. While this approach allows one to process graphs with trillions of edges, it also introduces new challenges. Namely, because each computer only sees a small piece of the input graph at a time, one needs to handle inter-machine communication and design algorithms that can be split across multiple computers.
A framework for implementing distributed algorithms, MapReduce, was introduced in 2008. It transparently handled communication between machines while offering good fault-tolerance capabilities and inspired the development of a number of distributed computation frameworks, including Pregel, Apache Hadoop, and many others. Still, the challenge of developing algorithms for distributed computation on very large graphs remained, and designing efficient algorithms in this context even for basic problems, such as connected components, maximum matching or shortest paths, has been an active area of research. While recent work has demonstrated new algorithms for many problems, including our algorithms for connected components (both in theory and practice) and hierarchical clustering, there was still a need for methods that could solve a range of problems more quickly.
Today we present a pair of recent papers that address this problem by first constructing a theoretical model for distributed graph algorithms and then demonstrating how the model can be applied. The proposed model, Adaptive Massively Parallel Computation (AMPC), augments the theoretical capabilities of MapReduce, providing a pathway to solve many graph problems in fewer computation rounds. We also show how the AMPC model can be effectively implemented in practice. The suite of algorithms we describe, which includes algorithms for maximal independent set, maximum matching, connected components and minimum spanning tree, work up to 7x faster than current state-of-the-art approaches.
Limitations of MapReduce
In order to understand the limitations of MapReduce for developing graph algorithms, consider a simplified variant of the connected components problem. The input is a collection of rooted trees, and the goal is to compute, for each node, the root of its tree. Even this seemingly simple problem is not easy to solve in MapReduce. In fact, in the Massively Parallel Computation (MPC) model — the theoretical model behind MapReduce, Pregel, Apache Giraph and many other distributed computation frameworks — this problem is widely believed to require at least a number of rounds of computation proportional to log n, where n is the total number of nodes in the graph. While log n may not seem to be a large number, algorithms processing trillion-edge graphs often write hundreds of terabytes of data to disk in each round, and thus even a small reduction in the number of rounds may bring significant resource savings.
 |
| The problem of finding root nodes. Nodes are represented by blue circles. Gray arrows point from each node to its parent. The root nodes are the nodes with no parents. The orange arrows illustrate the path an algorithm would follow from a node to the root of the tree to which it belongs. |
A similar subproblem showed up in our algorithms for finding connected components and computing a hierarchical clustering. We observed that one can bypass the limitations of MapReduce by implementing these algorithms through the use of a distributed hash table (DHT), a service that is initialized with a collection of key-value pairs and then returns a value associated with a provided key in real-time. In our implementation, for each node, the DHT stores its parent node. Then, a machine that processes a graph node can use the DHT and “walk up” the tree until it reaches the root. While the use of a DHT worked well for this particular problem (although it relied on the input trees being not too deep), it was unclear if the idea could be applied more broadly.
The Adaptive Massively Parallel Computation Model
To extend this approach to other problems, we started by developing a model to theoretically analyze algorithms that utilize a DHT. The resulting AMPC model builds upon the well-established MPC model and formally describes the capabilities brought by the use of a distributed hash table.
In the MPC model there is a collection of machines, which communicate via message passing in synchronous rounds. Messages sent in one round are delivered in the beginning of the following round and constitute that round’s entire input (i.e., the machines do not retain information from one round to the next). In the first round, one can assume that the input is randomly distributed across the machines. The goal is to minimize the number of computation rounds, while assuring load-balancing between machines in each round.
 |
| Computation in the MPC model. Each column represents one machine in subsequent computation rounds. Once all machines have completed a round of computation, all messages sent in that round are delivered, and the following round begins. |
We then formalized the AMPC model by introducing a new approach, in which machines write to a write-only distributed hash table each round, instead of communicating via messages. Once a new round starts, the hash table from the previous round becomes read-only and a new write-only output hash table becomes available. What is important is that only the method of communication changes — the amount of communication and available space per machine is constrained exactly in the same way as in the MPC model. Hence, at a high level the added capability of the AMPC model is that each machine can choose what data to read, instead of being provided a piece of data.
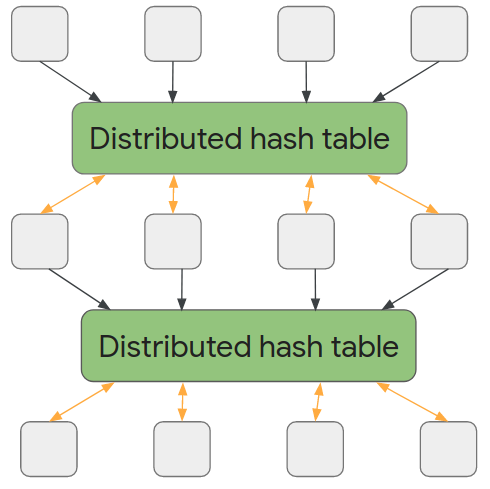 |
| Computation in the AMPC model. Once all machines have completed a round of computation, the data they produced is saved to a distributed hash table. In the following round, each machine can read arbitrary values from this distributed hash table and write to a new distributed hash table. |
Algorithms and Empirical Evaluation
This seemingly small difference in the way machines communicate allowed us to design much faster algorithms to a number of basic graph problems. In particular, we show that it is possible to find connected components, minimum spanning tree, maximal matching and maximal independent set in a constant number of rounds, regardless of the size of the graph.
To investigate the practical applicability of the AMPC algorithms, we have instantiated the model by combining Flume C++ (a C++ counterpart of FlumeJava) with a DHT communication layer. We have evaluated our AMPC algorithms for minimum spanning tree, maximal independent set and maximum matching and observed that we can achieve up to 7x speedups over implementations that did not use a DHT. At the same time, the AMPC implementations used 10x fewer rounds on average to complete, and also wrote less data to disk.
Our implementation of the AMPC model took advantage of hardware-accelerated remote direct memory access (RDMA), a technology that allows reading from the memory of a remote machine with a latency of a few microseconds, which is just an order of magnitude slower than reading from local memory. While some of the AMPC algorithms communicated more data than their MPC counterparts, they were overall faster, as they performed mostly fast reads using RDMA, instead of costly writes to disk.
Conclusion
With the AMPC model, we built a theoretical framework inspired by practically efficient implementations, and then developed new theoretical algorithms that delivered good empirical performance and maintained good fault-tolerance properties. We've been happy to see that the AMPC model has already been the subject of further study and are excited to learn what other problems can be solved more efficiently using the AMPC model or its practical implementations.
Acknowledgements
Co-authors on the two papers covered in this blog post include Soheil Behnezhad, Laxman Dhulipala, Hossein Esfandiari, and Warren Schudy. We also thank members of the Graph Mining team for their collaborations, and especially Mohammad Hossein Bateni for his input on this post. To learn more about our recent work on scalable graph algorithms, see videos from our recent Graph Mining and Learning workshop.
