Do you ever wonder how Google understands what you’re looking for? There’s a lot that goes into delivering helpful search results, and understanding language is one of the most important skills. Thanks to advancements in AI and machine learning, our Search systems are understanding human language better than ever before. And we want to share a behind-the-scenes look at how this translates into relevant results for you.
But first, let's walk down memory lane: In the early days of Search, before we had advanced AI, our systems simply looked for matching words. For example, if you searched for “pziza” — unless there was a page with that particular misspelling, you’d likely have to redo the search with the correct spelling to find a slice near you. And eventually, we learned how to code algorithms to find classes of patterns, like popular misspellings or potential typos from neighboring keys. Now, with advanced machine learning, our systems can more intuitively recognize if a word doesn’t look right and suggest a possible correction.
These kinds of AI improvements to our Search systems mean that they’re constantly getting better at understanding what you’re looking for. And since the world and people’s curiosities are always evolving, it’s really important that Search does, too. In fact, 15% of searches we see every day are entirely new. AI plays a major role in showing you helpful results, even at the outermost edges of your imagination.
How our systems play together
We’ve developed hundreds of algorithms over the years, like our early spelling system, to help deliver relevant search results. When we develop new AI systems, our legacy algorithms and systems don’t just get shelved away. In fact, Search runs on hundreds of algorithms and machine learning models, and we’re able to improve it when our systems — new and old — can play well together. Each algorithm and model has a specialized role, and they trigger at different times and in distinct combinations to help deliver the most helpful results. And some of our more advanced systems play a more prominent role than others. Let’s take a closer look at the major AI systems running in Search today, and what they do.
RankBrain — a smarter ranking system
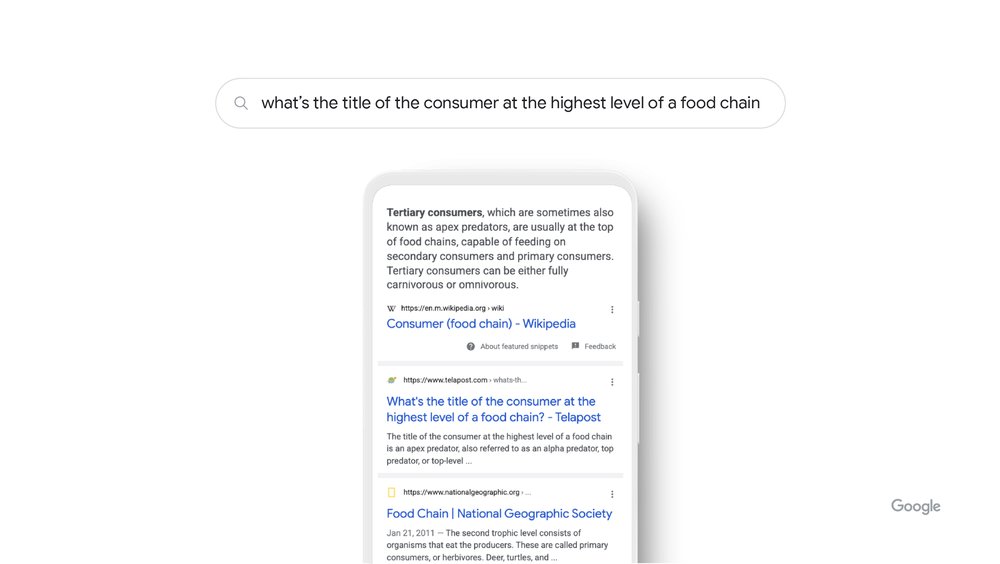
When we launched RankBrain in 2015, it was the first deep learning system deployed in Search. At the time, it was groundbreaking — not only because it was our first AI system, but because it helped us understand how words relate to concepts. Humans understand this instinctively, but it’s a complex challenge for a computer. RankBrain helps us find information we weren’t able to before by more broadly understanding how words in a search relate to real-world concepts. For example, if you search for “what’s the title of the consumer at the highest level of a food chain,” our systems learn from seeing those words on various pages that the concept of a food chain may have to do with animals, and not human consumers. By understanding and matching these words to their related concepts, RankBrain understands that you’re looking for what’s commonly referred to as an “apex predator.”
Thanks to this type of understanding, RankBrain (as its name suggests) is used to help rank — or decide the best order for — top search results. Although it was our very first deep learning model, RankBrain continues to be one of the major AI systems powering Search today.
Neural matching — a sophisticated retrieval engine
Neural networks underpin many modern AI systems today. But it wasn’t until 2018, when we introduced neural matching to Search, that we could use them to better understand how queries relate to pages. Neural matching helps us understand fuzzier representations of concepts in queries and pages, and match them to one another. It looks at an entire query or page rather than just keywords, developing a better understanding of the underlying concepts represented in them. Take the search “insights how to manage a green,” for example. If a friend asked you this, you’d probably be stumped. But with neural matching, we’re able to make sense of it. By looking at the broader representations of concepts in the query — management, leadership, personality and more — neural matching can decipher that this searcher is looking for management tips based on a popular, color-based personality guide.
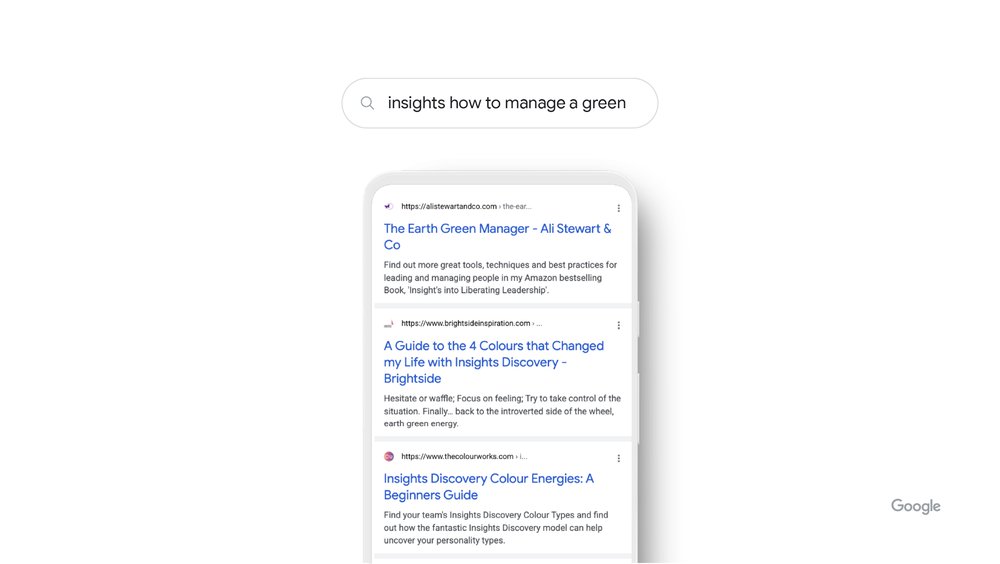
When our systems understand the broader concepts represented in a query or page, they can more easily match them with one another. This level of understanding helps us cast a wide net when we scan our index for content that may be relevant to your query. This is what makes neural matching such a critical part of how we retrieve relevant documents from a massive and constantly changing information stream.
BERT — a model for understanding meaning and context
Launched in 2019, BERT was a huge step change in natural language understanding, helping us understand how combinations of words express different meanings and intents. Rather than simply searching for content that matches individual words, BERT comprehends how a combination of words expresses a complex idea. BERT understands words in a sequence and how they relate to each other, so it ensures we don’t drop important words from your query — no matter how small they are. For example, if you search for “can you get medicine for someone pharmacy,” BERT understands that you’re trying to figure out if you can pick up medicine for someone else. Before BERT, we took that short preposition for granted, mostly sharing results about how to fill a prescription. Thanks to BERT, we understand that even small words can have big meanings.
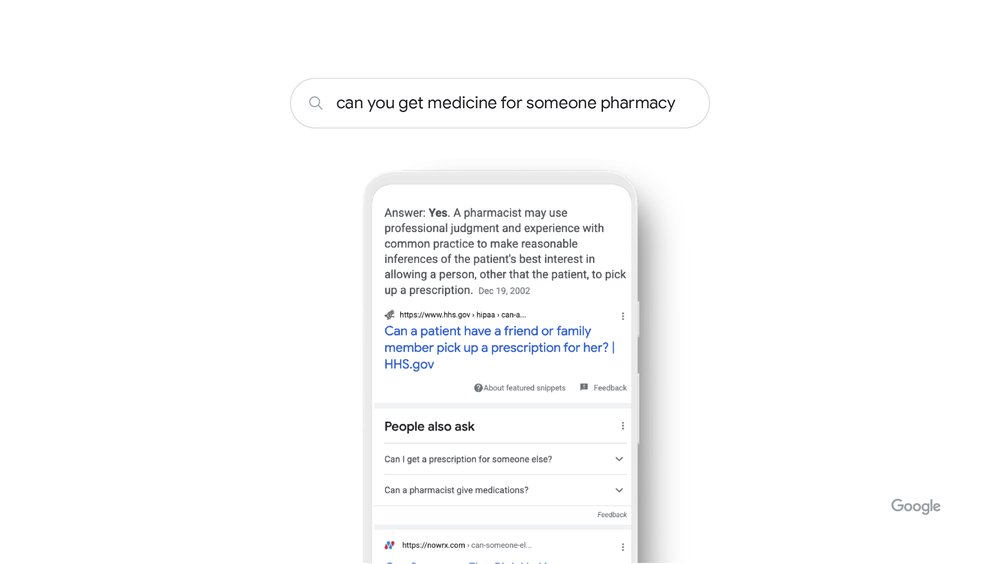
Today, BERT plays a critical role in almost every English query. This is because our BERT systems excel at two of the most important tasks in delivering relevant results — ranking and retrieving. Based on its complex language understanding, BERT can very quickly rank documents for relevance. We’ve also improved legacy systems with BERT training, making them more helpful in retrieving relevant documents for ranking. And while BERT plays a major role in Search, it’s never working alone — like all of our systems, BERT is part of an ensemble of systems that work together to share high-quality results.
MUM — moving from language to information understanding
In May, we introduced our latest AI milestone in Search — Multitask Unified Model, or MUM. A thousand times more powerful than BERT, MUM is capable of both understanding and generating language. It’s trained across 75 languages and many different tasks at once, allowing it to develop a more comprehensive understanding of information and world knowledge. MUM is also multimodal, meaning it can understand information across multiple modalities such as text, images and more in the future.
While we’re still in the early days of tapping into MUM’s potential, we’ve already used it to improve searches for COVID-19 vaccine information, and we’ll offer more intuitive ways to search using a combination of both text and images in Google Lens in the coming months. These are very specialized applications — so MUM is not currently used to help rank and improve the quality of search results like RankBrain, neural matching and BERT systems do.
As we introduce more MUM-powered experiences to Search, we’ll begin to shift from advanced language understanding to a more nuanced understanding of information about the world. And as with all improvements to Search, any MUM application will go through a rigorous evaluation process, with special attention to the responsible application of AI. And when they’re deployed, they’ll join the chorus of systems that run together to make Search helpful.

 A look at the Merchant Center Status Dashboard
A look at the Merchant Center Status Dashboard