Posted by Chen-Yu Lee and Chun-Liang Li, Research Scientists, Google Research, Cloud AI Team Form-based document understanding is a growing research topic because of its practical potential for automatically converting unstructured text data into structured information to gain insight about a document’s contents. Recent sequence modeling, which is a self-attention mechanism that directly models relationships between all words in a selection of text, has demonstrated state-of-the-art performance on natural language tasks. A natural approach to handle form document understanding tasks is to first serialize the form documents (usually in a left-to-right, top-to-bottom fashion) and then apply state-of-the-art sequence models to them.
However, form documents often have more complex layouts that contain structured objects, such as tables, columns, and text blocks. Their variety of layout patterns makes serialization difficult, substantially limiting the performance of strict serialization approaches. These unique challenges in form document structural modeling have been largely underexplored in literature.
 |
| An illustration of the form document information extraction task using an example from the FUNSD dataset. |
In “FormNet: Structural Encoding Beyond Sequential Modeling in Form Document Information Extraction”, presented at ACL 2022, we propose a structure-aware sequence model, called FormNet, to mitigate the sub-optimal serialization of forms for document information extraction. First, we design a Rich Attention (RichAtt) mechanism that leverages the 2D spatial relationship between word tokens for more accurate attention weight calculation. Then, we construct Super-Tokens (tokens that aggregate semantically meaningful information from neighboring tokens) for each word by embedding representations from their neighboring tokens through a graph convolutional network (GCN). Finally, we demonstrate that FormNet outperforms existing methods, while using less pre-training data, and achieves state-of-the-art performance on the CORD, FUNSD, and Payment benchmarks.
FormNet for Information ExtractionGiven a form document, we first use the
BERT-multilingual vocabulary and
optical character recognition (OCR) engine to identify and tokenize words. We then feed the tokens and their corresponding 2D coordinates into a GCN for graph construction and
message passing. Next, we use
Extended Transformer Construction (ETC) layers with the proposed RichAtt mechanism to continue to process the GCN-encoded structure-aware tokens for
schema learning (i.e., semantic entity extraction). Finally, we use the
Viterbi algorithm, which finds a sequence that maximizes the
posterior probability, to decode and obtain the final entities for output.
Extended Transformer Construction (ETC)
We adopt ETC as the FormNet model backbone. ETC scales to relatively long inputs by replacing standard attention, which has quadratic complexity, with a sparse global-local attention mechanism that distinguishes between global and long input tokens. The global tokens attend to and are attended by all tokens, but the long tokens attend only locally to other long tokens within a specified local radius, reducing the complexity so that it is more manageable for long sequences.
Rich Attention
Our novel architecture, RichAtt, avoids the deficiencies of absolute and relative embeddings by avoiding embeddings entirely. Instead, it computes the order of and log distance between pairs of tokens with respect to the x and y axes on the layout grid, and adjusts the pre-softmax attention scores of each pair as a direct function of these values.
In a traditional attention layer, each token representation is linearly transformed into a Query vector, a Key vector, and a Value vector. A token “looks” for other tokens from which it might want to absorb information (i.e., attend to) by finding the ones with Key vectors that create relatively high scores when matrix-multiplied (called Matmul) by its Query vector and then softmax-normalized. The token then sums together the Value vectors of all other tokens in the sentence, weighted by their score, and passes this up the network, where it will normally be added to the token’s original input vector.
However, other features beyond the Query and Key vectors are often relevant to the decision of how strongly a token should attend to another given token, such as the order they’re in, how many other tokens separate them, or how many pixels apart they are. In order to incorporate these features into the system, we use a trainable parametric function paired with an error network, which takes the observed feature and the output of the parametric function and returns a penalty that reduces the dot product attention score.
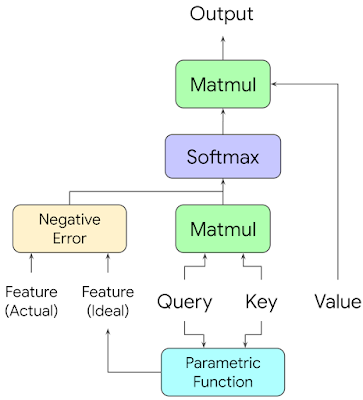 |
| The network uses the Query and Key vectors to consider what value some low-level feature (e.g., distance) should take if the tokens are related, and penalizes the attention score based on the error. |
At a high level, for each attention head at each layer, FormNet examines each pair of token representations, determines the ideal features the tokens should have if there is a meaningful relationship between them, and penalizes the attention score according to how different the actual features are from the ideal ones. This allows the model to learn constraints on attention using logical implication.
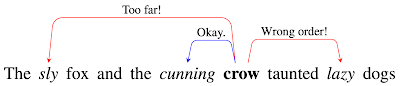 |
| A visualization of how RichAtt might act on a sentence. There are three adjectives that the word “crow” might attend to. “Lazy” is to the right, so it probably does not modify “crow” and its attention edge is penalized. “Sly” is many tokens away, so its attention edge is also penalized. “Cunning” receives no significant penalties, so by process of elimination, it is the best candidate for attention. |
Furthermore, if one assumes that the softmax-normalized attention scores represent a probability distribution, and the distributions for the observed features are known, then this algorithm — including the exact choice of parametric functions and error functions — falls out algebraically, meaning FormNet has a mathematical correctness to it that is lacking from many alternatives (including relative embeddings).
Super-Tokens by Graph Learning
The key to sparsifying attention mechanisms in ETC for long sequence modeling is to have every token only attend to tokens that are nearby in the serialized sequence. Although the RichAtt mechanism empowers the transformers by taking the spatial layout structures into account, poor serialization can still block significant attention weight calculation between related word tokens.
To further mitigate the issue, we construct a graph to connect nearby tokens in a form document. We design the edges of the graph based on strong inductive biases so that they have higher probabilities of belonging to the same entity type. For each token, we obtain its Super-Token embedding by applying graph convolutions along these edges to aggregate semantically relevant information from neighboring tokens. We then use these Super-Tokens as an input to the RichAtt ETC architecture. This means that even though an entity may get broken up into multiple segments due to poor serialization, the Super-Tokens learned by the GCN will have retained much of the context of the entity phrase.
 |
| An illustration of the word-level graph, with blue edges between tokens, of a FUNSD document. |
Key Results
The Figure below shows model size vs. F1 score (the harmonic mean of the precision and recall) for recent approaches on the CORD benchmark. FormNet-A2 outperforms the most recent DocFormer while using a model that is 2.5x smaller. FormNet-A3 achieves state-of-the-art performance with a 97.28% F1 score. For more experimental results, please refer to the paper.
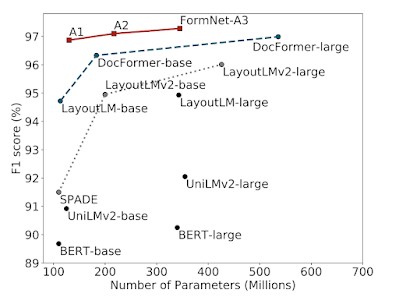 |
| Model Size vs. Entity Extraction F1 Score on CORD benchmark. FormNet significantly outperforms other recent approaches in absolute F1 performance and parameter efficiency. |
We study the importance of RichAtt and Super-Token by GCN on the large-scale masked language modeling (MLM) pre-training task across three FormNets. Both RichAtt and GCN components improve upon the ETC baseline on reconstructing the masked tokens by a large margin, showing the effectiveness of their structural encoding capability on form documents. The best performance is obtained when incorporating both RichAtt and GCN.
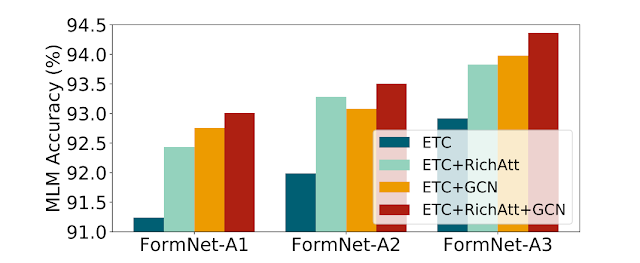 |
| Performance of the Masked-Language Modeling (MLM) pre-training. Both the proposed RichAtt and Super-Token by GCN components improve upon ETC baseline by a large margin, showing the effectiveness of their structural encoding capability on large-scale form documents. |
Using BertViz, we visualize the local-to-local attention scores for specific examples from the CORD dataset for the standard ETC and FormNet models. Qualitatively, we confirm that the tokens attend primarily to other tokens within the same visual block for FormNet. Moreover for that model, specific attention heads are attending to tokens aligned horizontally, which is a strong signal of meaning for form documents. No clear attention pattern emerges for the ETC model, suggesting the RichAtt and Super-Token by GCN enable the model to learn the structural cues and leverage layout information effectively.
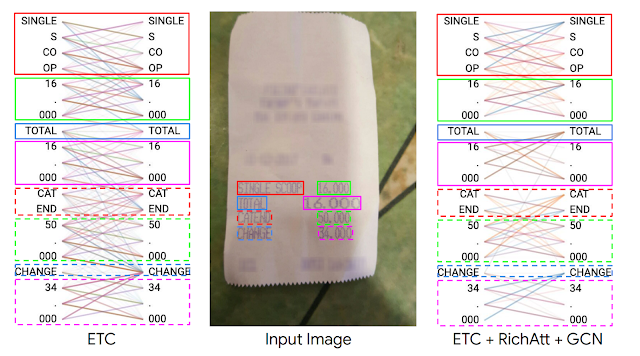 |
| The attention scores for ETC and FormNet (ETC+RichAtt+GCN) models. Unlike the ETC model, the FormNet model makes tokens attend to other tokens within the same visual blocks, along with tokens aligned horizontally, thus strongly leveraging structural cues. |
Conclusion
We present FormNet, a novel model architecture for form-based document understanding. We determine that the novel RichAtt mechanism and Super-Token components help the ETC transformer excel at form understanding in spite of sub-optimal, noisy serialization. We demonstrate that FormNet recovers local syntactic information that may have been lost during text serialization and achieves state-of-the-art performance on three benchmarks.
Acknowledgements
This research was conducted by Chen-Yu Lee, Chun-Liang Li, Timothy Dozat, Vincent Perot, Guolong Su, Nan Hua, Joshua Ainslie, Renshen Wang, Yasuhisa Fujii, and Tomas Pfister. Thanks to Evan Huang, Shengyang Dai, and Salem Elie Haykal for their valuable feedback, and Tom Small for creating the animation in this post.