Posted by Adel Ahmadyan and Liangkai Zhang, Software Engineers, Google Research The state of the art in machine learning (ML) has achieved exceptional accuracy on many computer vision tasks solely by training models on photos. Building upon these successes and advancing 3D object understanding has great potential to power a wider range of applications, such as augmented reality, robotics, autonomy, and image retrieval. For example, earlier this year we released MediaPipe Objectron, a set of real-time 3D object detection models designed for mobile devices, which were trained on a fully annotated, real-world 3D dataset, that can predict objects’ 3D bounding boxes.
Yet, understanding objects in 3D remains a challenging task due to the lack of large real-world datasets compared to 2D tasks (e.g., ImageNet, COCO, and Open Images). To empower the research community for continued advancement in 3D object understanding, there is a strong need for the release of object-centric video datasets, which capture more of the 3D structure of an object, while matching the data format used for many vision tasks (i.e., video or camera streams), to aid in the training and benchmarking of machine learning models.
Today, we are excited to release the Objectron dataset, a collection of short, object-centric video clips capturing a larger set of common objects from different angles. Each video clip is accompanied by AR session metadata that includes camera poses and sparse point-clouds. The data also contain manually annotated 3D bounding boxes for each object, which describe the object’s position, orientation, and dimensions. The dataset consists of 15K annotated video clips supplemented with over 4M annotated images collected from a geo-diverse sample (covering 10 countries across five continents).
 |
| Example videos in the Objectron dataset. |
A 3D Object Detection Solution
Along with the dataset, we are also sharing a 3D object detection solution for four categories of objects — shoes, chairs, mugs, and cameras. These models are released in MediaPipe, Google's open source framework for cross-platform customizable ML solutions for live and streaming media, which also powers ML solutions like on-device real-time hand, iris and body pose tracking.
 |
| Sample results of 3D object detection solution running on mobile. |
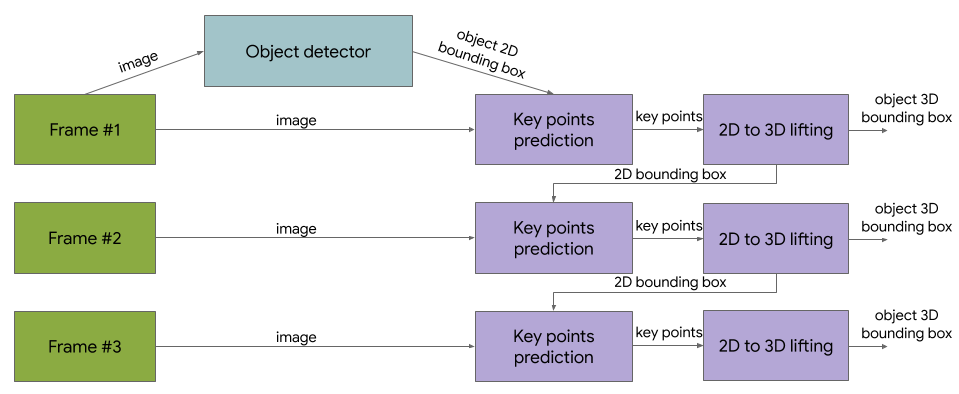
In contrast to the previously released single-stage Objectron model, these newest versions utilize a two-stage architecture. The first stage employs the TensorFlow Object Detection model to find the 2D crop of the object. The second stage then uses the image crop to estimate the 3D bounding box while simultaneously computing the 2D crop of the object for the next frame, so that the object detector does not need to run every frame. The second stage 3D bounding box predictor runs at 83 FPS on Adreno 650 mobile GPU.
 |
| Diagram of a reference 3D object detection solution. |
Evaluation Metric for 3D Object Detection
With ground truth annotations, we evaluate the performance of 3D object detection models using 3D intersection over union (IoU) similarity statistics, a commonly used metric for computer vision tasks, which measures how close the bounding boxes are to the ground truth.
We propose an algorithm for computing accurate 3D IoU values for general 3D-oriented boxes. First, we compute the intersection points between faces of the two boxes using Sutherland-Hodgman Polygon clipping algorithm. This is similar to frustum culling, a technique used in computer graphics. The volume of the intersection is computed by the convex hull of all the clipped polygons. Finally, the IoU is computed from the volume of the intersection and volume of the union of two boxes. We are releasing the evaluation metrics source code along with the dataset.
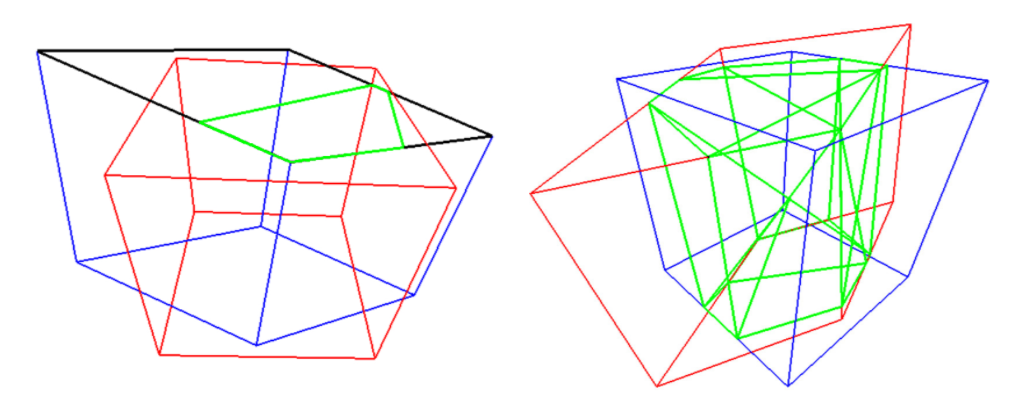 |
| Compute the 3D intersection over union using the polygon clipping algorithm, Left: Compute the intersection points of each face by clipping the polygon against the box. Right: Compute the volume of intersection by computing the convex hull of all intersection points (green). |
Dataset Format
The technical details of the Objectron dataset, including usage and tutorials, are available on the dataset website. The dataset includes bikes, books, bottles, cameras, cereal boxes, chairs, cups, laptops, and shoes, and is stored in the objectron bucket on Google Cloud storage with the following assets:
- The video sequences
- The annotation labels (3D bounding boxes for objects)
- AR metadata (such as camera poses, point clouds, and planar surfaces)
- Processed dataset: shuffled version of the annotated frames, in tf.example format for images and SequenceExample format for videos.
- Supporting scripts to run evaluation based on the metric described above
- Supporting scripts to load the data into Tensorflow, PyTorch, and Jax and to visualize the dataset, including “Hello World” examples
With the dataset, we are also open-sourcing a data-pipeline to parse the dataset in popular Tensorflow, PyTorch and Jax frameworks. Example colab notebooks are also provided.
By releasing this Objectron dataset, we hope to enable the research community to push the limits of 3D object geometry understanding. We also hope to foster new research and applications, such as view synthesis, improved 3D representation, and unsupervised learning. Stay tuned for future activities and developments by joining our mailing list and visiting our github page.
Acknowledgements
The research described in this post was done by Adel Ahmadyan, Liangkai Zhang, Jianing Wei, Artsiom Ablavatski, Mogan Shieh, Ryan Hickman, Buck Bourdon, Alexander Kanaukou, Chuo-Ling Chang, Matthias Grundmann, and Tom Funkhouser. We thank Aliaksandr Shyrokau, Sviatlana Mialik, Anna Eliseeva, and the annotation team for their high quality annotations. We also would like to thank Jonathan Huang and Vivek Rathod for their guidance on TensorFlow Object Detection API.