It’s winter, it’s the holidays and it’s quarantine-times: It’s the perfect recipe for doing a ton of baking. In fact, U.S. search interest in "baking" spiked in both November and December 2020.
But being in the AI field, we decided to dive a little deeper into the trend and
try to understand the science behind what makes cookies crunchy, cake spongy and bread fluffy — and we decided to do it with the help of machine learning. Plus, we used our ML model to come up with two completely new baking recipes: a cakie (cake-cookie hybrid) and a breakie (bread-cookie hybrid). (Don’t worry, recipes included below.)
We started off by collecting hundreds of cookie, cake and bread recipes. Then we converted all of their ingredients to ounces and whittled them down to a few essential ingredients (yeast, flour, sugar, eggs, butter and a few other things). Next we did a bit of reorganizing, since according to Paul Hollywood, treats like banana, zucchini and pumpkin bread are really more cake than they are bread.
Then we used a Google Cloud tool called AutoML Tables to build a machine learning model that analyzed a recipe’s ingredient amounts and predicted whether it was a recipe for cookies, cake or bread. If you’ve never tried AutoML Tables, it’s a code-free way to build models from the type of data you’d find in a spreadsheet like numbers and categories – no data science background required.
Our model was able to accurately tag breads, cookies and cakes, but could also identify recipes it deemed “hybrids” — something that’s, say, 50% cake and 50% bread, or something that’s 50% cake and 50% cookie. We named two such combinations the “breakie” (a bread-cookie — "brookie” was already taken) and the “cakie” (a cake-cookie) respectively.
Being science-minded bakers, we had to experimentally verify if these hybrid treats could really be made. You know, for science.
Behold the cakie: It has the crispiness of a cookie and the, well, “cakiness” of a cake.

We also made breakies, which were more like fluffy cookies, almost the consistency of a muffin.

Sara's first batch of breakies.
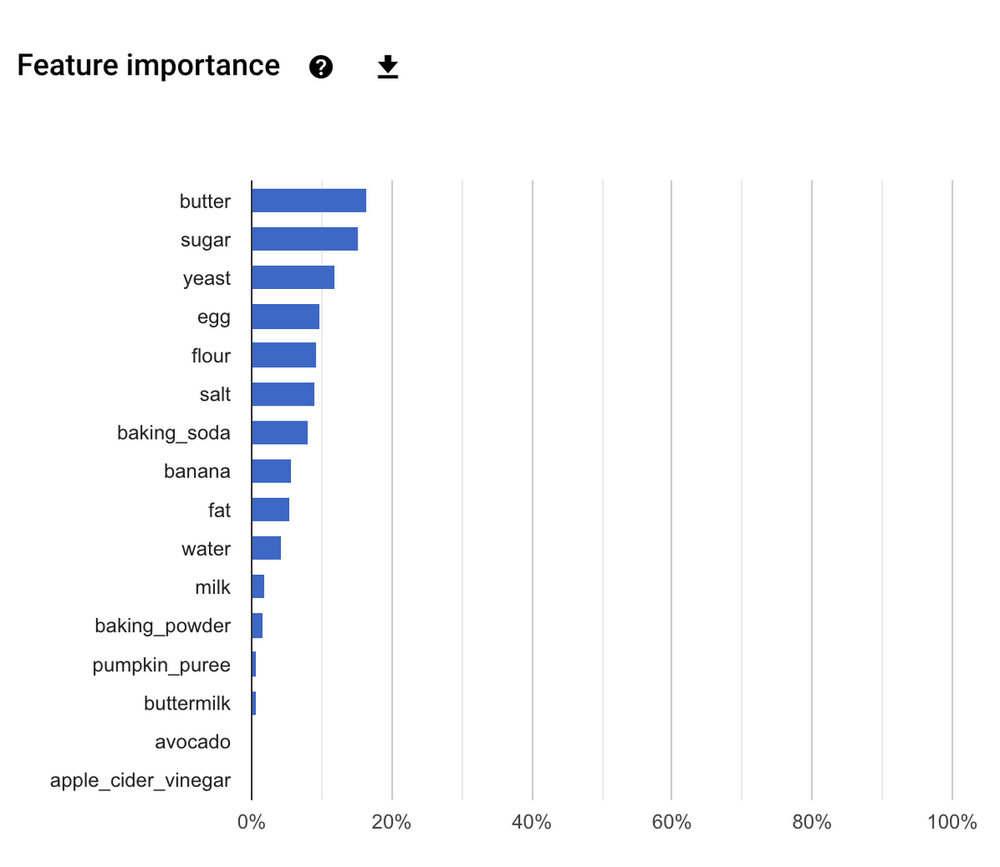
Beyond just generating recipes, we also used our model to understand what made the consistency of cookies, cakes and breads so different. For that, we used a metric called “feature importance,” which is automatically calculated by AutoML Tables.
In our case, the amount of butter, sugar, yeast and egg in a recipe all seemed to be important indicators of “cookieness” (or cakiness or breadiness). AutoML Tables lets you look at feature importance both for your model as a whole and for individual predictions. Below are the most important features for our model as a whole, meaning these ingredients were the biggest signals for our model across many different cake, cookie and bread recipes:
If you find yourself with extra time and an experimental spirit, try out our recipes and let us know what you think. And you can find all the details of what we learned from our ML model in the technical blog post.


Most importantly, if you come up with an even better cakie or breakie recipe, please let us know.