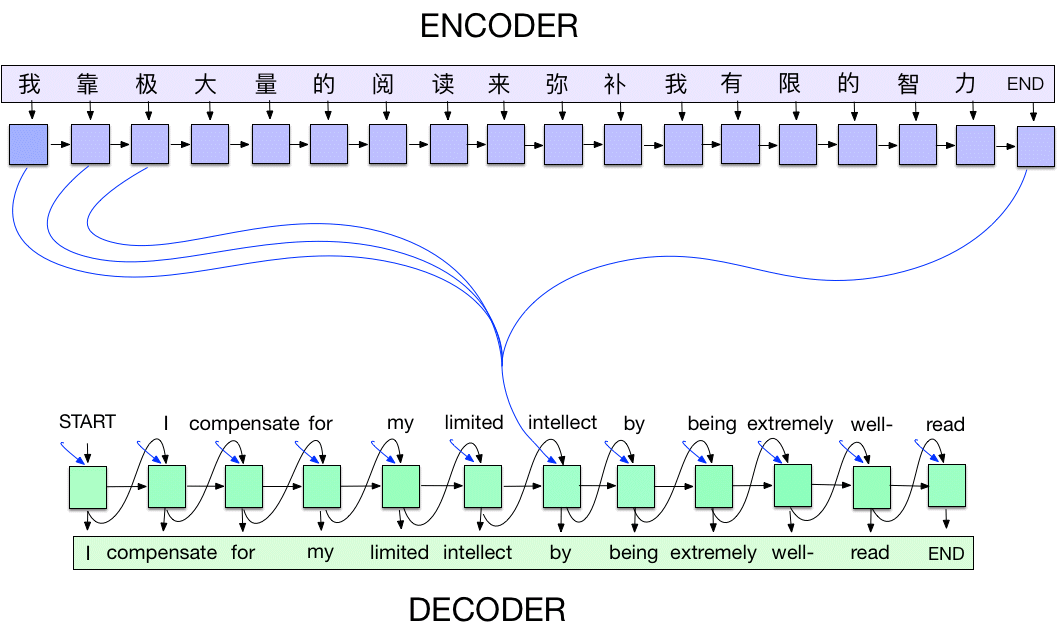
At Google, we develop flexible state-of-the-art machine learning (ML) systems for computer vision that not only can be used to improve our products and services, but also spur progress in the research community. Creating accurate ML models capable of localizing and identifying multiple objects in a single image remains a core challenge in the field, and we invest a significant amount of time training and experimenting with these systems.
 |
| Detected objects in a sample image (from the COCO dataset) made by one of our models. Image credit: Michael Miley, original image |
Today we are happy to make this system available to the broader research community via the TensorFlow Object Detection API. This codebase is an open source framework built on top of TensorFlow that makes it easy to construct, train and deploy object detection models. Our goals in designing this system was to support state-of-the-art models while allowing for rapid exploration and research. Our first release contains the following:
- A selection of trainable detection models, including:
- Single Shot Multibox Detector (SSD) with MobileNets
- SSD with Inception V2
- Region-Based Fully Convolutional Networks (R-FCN) with Resnet 101
- Faster RCNN with Resnet 101
- Faster RCNN with Inception Resnet v2
- Frozen weights (trained on the COCO dataset) for each of the above models to be used for out-of-the-box inference purposes.
- A Jupyter notebook for performing out-of-the-box inference with one of our released models
- Convenient local training scripts as well as distributed training and evaluation pipelines via Google Cloud
Are you ready to get started?
We’ve certainly found this code to be useful for our computer vision needs, and we hope that you will as well. Contributions to the codebase are welcome and please stay tuned for our own further updates to the framework. To get started, download the code here and try detecting objects in some of your own images using the Jupyter notebook, or training your own pet detector on Cloud ML engine!
By Jonathan Huang, Research Scientist and Vivek Rathod, Software Engineer
Acknowledgements
The release of the Tensorflow Object Detection API and the pre-trained model zoo has been the result of widespread collaboration among Google researchers with feedback and testing from product groups. In particular we want to highlight the contributions of the following individuals:
Core Contributors: Derek Chow, Chen Sun, Menglong Zhu, Matthew Tang, Anoop Korattikara, Alireza Fathi, Ian Fischer, Zbigniew Wojna, Yang Song, Sergio Guadarrama, Jasper Uijlings, Viacheslav Kovalevskyi, Kevin Murphy
Also special thanks to: Andrew Howard, Rahul Sukthankar, Vittorio Ferrari, Tom Duerig, Chuck Rosenberg, Hartwig Adam, Jing Jing Long, Victor Gomes, George Papandreou, Tyler Zhu
References
- Speed/accuracy trade-offs for modern convolutional object detectors, Huang et al., CVPR 2017 (paper describing this framework)
- Towards Accurate Multi-person Pose Estimation in the Wild, Papandreou et al., CVPR 2017
- YouTube-BoundingBoxes: A Large High-Precision Human-Annotated Data Set for Object Detection in Video, Real et al., CVPR 2017 (see also our blog post)
- Beyond Skip Connections: Top-Down Modulation for Object Detection, Shrivastava et al., arXiv preprint arXiv:1612.06851, 2016
- Spatially Adaptive Computation Time for Residual Networks, Figurnov et al., CVPR 2017
- AVA: A Video Dataset of Spatio-temporally Localized Atomic Visual Actions, Gu et al., arXiv preprint arXiv:1705.08421, 2017
- MobileNets: Efficient convolutional neural networks for mobile vision applications, Howard et al., arXiv preprint arXiv:1704.04861, 2017