Code-change reviews are a critical part of the software development process at scale, taking a significant amount of the code authors’ and the code reviewers’ time. As part of this process, the reviewer inspects the proposed code and asks the author for code changes through comments written in natural language. At Google, we see millions of reviewer comments per year, and authors require an average of ~60 minutes active shepherding time between sending changes for review and finally submitting the change. In our measurements, the required active work time that the code author must do to address reviewer comments grows almost linearly with the number of comments. However, with machine learning (ML), we have an opportunity to automate and streamline the code review process, e.g., by proposing code changes based on a comment’s text.
Today, we describe applying recent advances of large sequence models in a real-world setting to automatically resolve code review comments in the day-to-day development workflow at Google (publication forthcoming). As of today, code-change authors at Google address a substantial amount of reviewer comments by applying an ML-suggested edit. We expect that to reduce time spent on code reviews by hundreds of thousands of hours annually at Google scale. Unsolicited, very positive feedback highlights that the impact of ML-suggested code edits increases Googlers' productivity and allows them to focus on more creative and complex tasks.
Predicting the code edit
We started by training a model that predicts code edits needed to address reviewer comments. The model is pre-trained on various coding tasks and related developer activities (e.g., renaming a variable, repairing a broken build, editing a file). It’s then fine-tuned for this specific task with reviewed code changes, the reviewer comments, and the edits the author performed to address those comments.
 |
| An example of an ML-suggested edit of refactorings that are spread within the code. |
Google uses a monorepo, a single repository for all of its software artifacts, which allows our training dataset to include all unrestricted code used to build Google's most recent software, as well as previous versions.
To improve the model quality, we iterated on the training dataset. For example, we compared the model performance for datasets with a single reviewer comment per file to datasets with multiple comments per file, and experimented with classifiers to clean up the training data based on a small, curated dataset to choose the model with the best offline precision and recall metrics.
Serving infrastructure and user experience
We designed and implemented the feature on top of the trained model, focusing on the overall user experience and developer efficiency. As part of this, we explored different user experience (UX) alternatives through a series of user studies. We then refined the feature based on insights from an internal beta (i.e., a test of the feature in development) including user feedback (e.g., a “Was this helpful?” button next to the suggested edit).
The final model was calibrated for a target precision of 50%. That is, we tuned the model and the suggestions filtering, so that 50% of suggested edits on our evaluation dataset are correct. In general, increasing the target precision reduces the number of shown suggested edits, and decreasing the target precision leads to more incorrect suggested edits. Incorrect suggested edits take the developers time and reduce the developers’ trust in the feature. We found that a target precision of 50% provides a good balance.
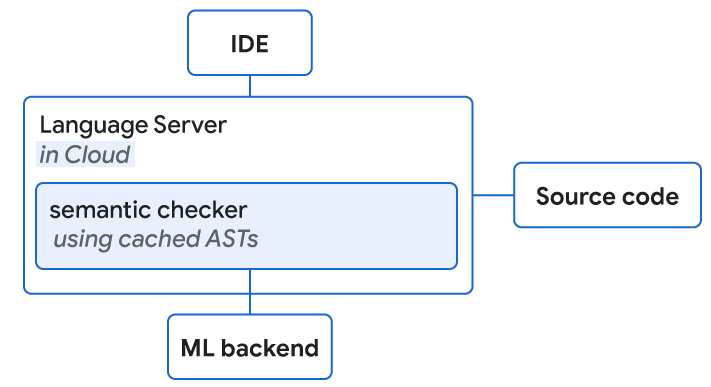
At a high level, for every new reviewer comment, we generate the model input in the same format that is used for training, query the model, and generate the suggested code edit. If the model is confident in the prediction and a few additional heuristics are satisfied, we send the suggested edit to downstream systems. The downstream systems, i.e., the code review frontend and the integrated development environment (IDE), expose the suggested edits to the user and log user interactions, such as preview and apply events. A dedicated pipeline collects these logs and generates aggregate insights, e.g., the overall acceptance rates as reported in this blog post.
 |
| Architecture of the ML-suggested edits infrastructure. We process code and infrastructure from multiple services, get the model predictions and surface the predictions in the code review tool and IDE. |
The developer interacts with the ML-suggested edits in the code review tool and the IDE. Based on insights from the user studies, the integration into the code review tool is most suitable for a streamlined review experience. The IDE integration provides additional functionality and supports 3-way merging of the ML-suggested edits (left in the figure below) in case of conflicting local changes on top of the reviewed code state (right) into the merge result (center).
.gif) |
| 3-way-merge UX in IDE. |
Results
Offline evaluations indicate that the model addresses 52% of comments with a target precision of 50%. The online metrics of the beta and the full internal launch confirm these offline metrics, i.e., we see model suggestions above our target model confidence for around 50% of all relevant reviewer comments. 40% to 50% of all previewed suggested edits are applied by code authors.
We used the “not helpful” feedback during the beta to identify recurring failure patterns of the model. We implemented serving-time heuristics to filter these and, thus, reduce the number of shown incorrect predictions. With these changes, we traded quantity for quality and observed an increased real-world acceptance rate.
.gif) |
| Code review tool UX. The suggestion is shown as part of the comment and can be previewed, applied and rated as helpful or not helpful. |
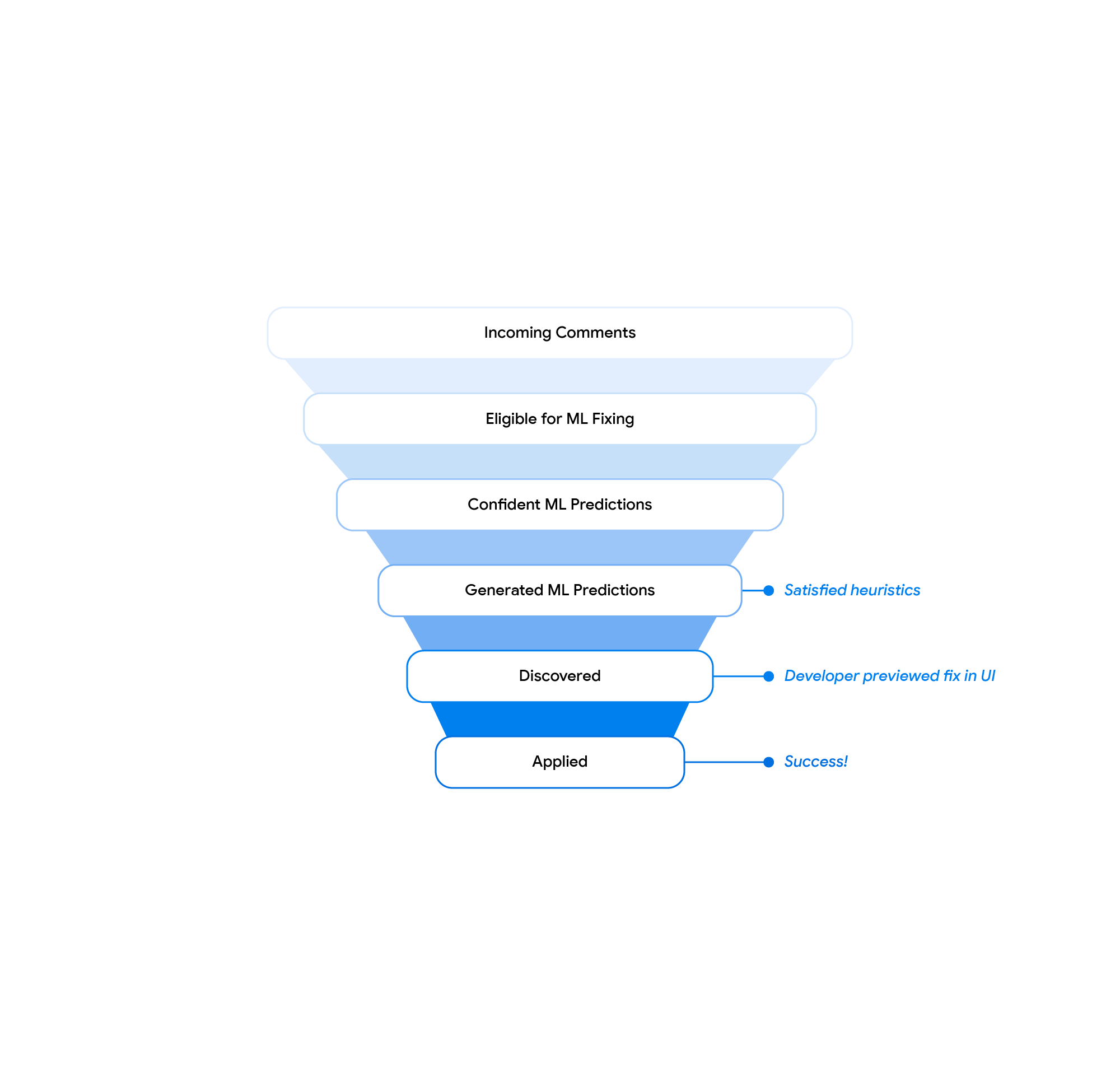
Our beta launch showed a discoverability challenge: code authors only previewed ~20% of all generated suggested edits. We modified the UX and introduced a prominent “Show ML-edit” button (see the figure above) next to the reviewer comment, leading to an overall preview rate of ~40% at launch. We additionally found that suggested edits in the code review tool are often not applicable due to conflicting changes that the author did during the review process. We addressed this with a button in the code review tool that opens the IDE in a merge view for the suggested edit. We now observe that more than 70% of these are applied in the code review tool and fewer than 30% are applied in the IDE. All these changes allowed us to increase the overall fraction of reviewer comments that are addressed with an ML-suggested edit by a factor of 2 from beta to the full internal launch. At Google scale, these results help automate the resolution of hundreds of thousands of comments each year.
 |
| Suggestions filtering funnel. |
We see ML-suggested edits addressing a wide range of reviewer comments in production. This includes simple localized refactorings and refactorings that are spread within the code, as shown in the examples throughout the blog post above. The feature addresses longer and less formally-worded comments that require code generation, refactorings and imports.
 |
| Example of a suggestion for a longer and less formally worded comment that requires code generation, refactorings and imports. |
The model can also respond to complex comments and produce extensive code edits (shown below). The generated test case follows the existing unit test pattern, while changing the details as described in the comment. Additionally, the edit suggests a comprehensive name for the test reflecting the test semantics.
 |
| Example of the model's ability to respond to complex comments and produce extensive code edits. |
Conclusion and future work
In this post, we introduced an ML-assistance feature to reduce the time spent on code review related changes. At the moment, a substantial amount of all actionable code review comments on supported languages are addressed with applied ML-suggested edits at Google. A 12-week A/B experiment across all Google developers will further measure the impact of the feature on the overall developer productivity.
We are working on improvements throughout the whole stack. This includes increasing the quality and recall of the model and building a more streamlined experience for the developer with improved discoverability throughout the review process. As part of this, we are investigating the option of showing suggested edits to the reviewer while they draft comments and expanding the feature into the IDE to enable code-change authors to get suggested code edits for natural-language commands.
Acknowledgements
This is the work of many people in Google Core Systems & Experiences team, Google Research, and DeepMind. We'd like to specifically thank Peter Choy for bringing the collaboration together, and all of our team members for their key contributions and useful advice, including Marcus Revaj, Gabriela Surita, Maxim Tabachnyk, Jacob Austin, Nimesh Ghelani, Dan Zheng, Peter Josling, Mariana Stariolo, Chris Gorgolewski, Sascha Varkevisser, Katja Grünwedel, Alberto Elizondo, Tobias Welp, Paige Bailey, Pierre-Antoine Manzagol, Pascal Lamblin, Chenjie Gu, Petros Maniatis, Henryk Michalewski, Sara Wiltberger, Ambar Murillo, Satish Chandra, Madhura Dudhgaonkar, Niranjan Tulpule, Zoubin Ghahramani, Juanjo Carin, Danny Tarlow, Kevin Villela, Stoyan Nikolov, David Tattersall, Boris Bokowski, Kathy Nix, Mehdi Ghissassi, Luis C. Cobo, Yujia Li, David Choi, Kristóf Molnár, Vahid Meimand, Amit Patel, Brett Wiltshire, Laurent Le Brun, Mingpan Guo, Hermann Loose, Jonas Mattes, Savinee Dancs.