Differential privacy (DP) is a property of randomized mechanisms that limit the influence of any individual user’s information while processing and analyzing data. DP offers a robust solution to address growing concerns about data protection, enabling technologies across industries and government applications (e.g., the US census) without compromising individual user identities. As its adoption increases, it’s important to identify the potential risks of developing mechanisms with faulty implementations. Researchers have recently found errors in the mathematical proofs of private mechanisms, and their implementations. For example, researchers compared six sparse vector technique (SVT) variations and found that only two of the six actually met the asserted privacy guarantee. Even when mathematical proofs are correct, the code implementing the mechanism is vulnerable to human error.
However, practical and efficient DP auditing is challenging primarily due to the inherent randomness of the mechanisms and the probabilistic nature of the tested guarantees. In addition, a range of guarantee types exist, (e.g., pure DP, approximate DP, Rényi DP, and concentrated DP), and this diversity contributes to the complexity of formulating the auditing problem. Further, debugging mathematical proofs and code bases is an intractable task given the volume of proposed mechanisms. While ad hoc testing techniques exist under specific assumptions of mechanisms, few efforts have been made to develop an extensible tool for testing DP mechanisms.
To that end, in “DP-Auditorium: A Large Scale Library for Auditing Differential Privacy”, we introduce an open source library for auditing DP guarantees with only black-box access to a mechanism (i.e., without any knowledge of the mechanism’s internal properties). DP-Auditorium is implemented in Python and provides a flexible interface that allows contributions to continuously improve its testing capabilities. We also introduce new testing algorithms that perform divergence optimization over function spaces for Rényi DP, pure DP, and approximate DP. We demonstrate that DP-Auditorium can efficiently identify DP guarantee violations, and suggest which tests are most suitable for detecting particular bugs under various privacy guarantees.
DP guarantees
The output of a DP mechanism is a sample drawn from a probability distribution (M (D)) that satisfies a mathematical property ensuring the privacy of user data. A DP guarantee is thus tightly related to properties between pairs of probability distributions. A mechanism is differentially private if the probability distributions determined by M on dataset D and a neighboring dataset D’, which differ by only one record, are indistinguishable under a given divergence metric.
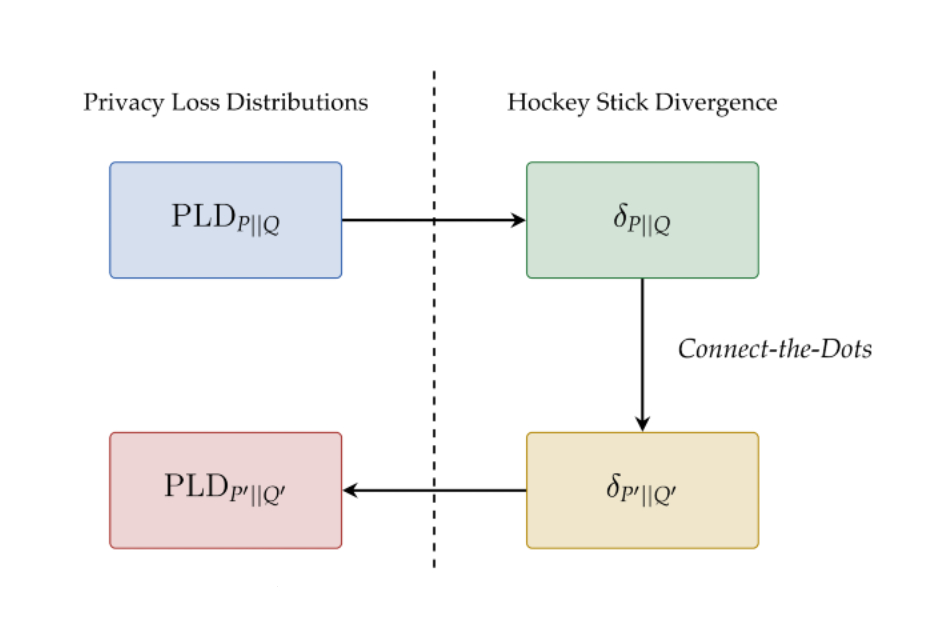
For example, the classical approximate DP definition states that a mechanism is approximately DP with parameters (ε, δ) if the hockey-stick divergence of order eε, between M(D) and M(D’), is at most δ. Pure DP is a special instance of approximate DP where δ = 0. Finally, a mechanism is considered Rényi DP with parameters (𝛼, ε) if the Rényi divergence of order 𝛼, is at most ε (where ε is a small positive value). In these three definitions, ε is not interchangeable but intuitively conveys the same concept; larger values of ε imply larger divergences between the two distributions or less privacy, since the two distributions are easier to distinguish.
DP-Auditorium
DP-Auditorium comprises two main components: property testers and dataset finders. Property testers take samples from a mechanism evaluated on specific datasets as input and aim to identify privacy guarantee violations in the provided datasets. Dataset finders suggest datasets where the privacy guarantee may fail. By combining both components, DP-Auditorium enables (1) automated testing of diverse mechanisms and privacy definitions and, (2) detection of bugs in privacy-preserving mechanisms. We implement various private and non-private mechanisms, including simple mechanisms that compute the mean of records and more complex mechanisms, such as different SVT and gradient descent mechanism variants.
Property testers determine if evidence exists to reject the hypothesis that a given divergence between two probability distributions, P and Q, is bounded by a prespecified budget determined by the DP guarantee being tested. They compute a lower bound from samples from P and Q, rejecting the property if the lower bound value exceeds the expected divergence. No guarantees are provided if the result is indeed bounded. To test for a range of privacy guarantees, DP-Auditorium introduces three novel testers: (1) HockeyStickPropertyTester, (2) RényiPropertyTester, and (3) MMDPropertyTester. Unlike other approaches, these testers don’t depend on explicit histogram approximations of the tested distributions. They rely on variational representations of the hockey-stick divergence, Rényi divergence, and maximum mean discrepancy (MMD) that enable the estimation of divergences through optimization over function spaces. As a baseline, we implement HistogramPropertyTester, a commonly used approximate DP tester. While our three testers follow a similar approach, for brevity, we focus on the HockeyStickPropertyTester in this post.
Given two neighboring datasets, D and D’, the HockeyStickPropertyTester finds a lower bound,^δ for the hockey-stick divergence between M(D) and M(D’) that holds with high probability. Hockey-stick divergence enforces that the two distributions M(D) and M(D’) are close under an approximate DP guarantee. Therefore, if a privacy guarantee claims that the hockey-stick divergence is at most δ, and^δ > δ, then with high probability the divergence is higher than what was promised on D and D’ and the mechanism cannot satisfy the given approximate DP guarantee. The lower bound^δ is computed as an empirical and tractable counterpart of a variational formulation of the hockey-stick divergence (see the paper for more details). The accuracy of^δ increases with the number of samples drawn from the mechanism, but decreases as the variational formulation is simplified. We balance these factors in order to ensure that^δ is both accurate and easy to compute.
Dataset finders use black-box optimization to find datasets D and D’ that maximize^δ, a lower bound on the divergence value δ. Note that black-box optimization techniques are specifically designed for settings where deriving gradients for an objective function may be impractical or even impossible. These optimization techniques oscillate between exploration and exploitation phases to estimate the shape of the objective function and predict areas where the objective can have optimal values. In contrast, a full exploration algorithm, such as the grid search method, searches over the full space of neighboring datasets D and D’. DP-Auditorium implements different dataset finders through the open sourced black-box optimization library Vizier.
Running existing components on a new mechanism only requires defining the mechanism as a Python function that takes an array of data D and a desired number of samples n to be output by the mechanism computed on D. In addition, we provide flexible wrappers for testers and dataset finders that allow practitioners to implement their own testing and dataset search algorithms.
Key results
We assess the effectiveness of DP-Auditorium on five private and nine non-private mechanisms with diverse output spaces. For each property tester, we repeat the test ten times on fixed datasets using different values of ε, and report the number of times each tester identifies privacy bugs. While no tester consistently outperforms the others, we identify bugs that would be missed by previous techniques (HistogramPropertyTester). Note that the HistogramPropertyTester is not applicable to SVT mechanisms.
 |
| Number of times each property tester finds the privacy violation for the tested non-private mechanisms. NonDPLaplaceMean and NonDPGaussianMean mechanisms are faulty implementations of the Laplace and Gaussian mechanisms for computing the mean. |
We also analyze the implementation of a DP gradient descent algorithm (DP-GD) in TensorFlow that computes gradients of the loss function on private data. To preserve privacy, DP-GD employs a clipping mechanism to bound the l2-norm of the gradients by a value G, followed by the addition of Gaussian noise. This implementation incorrectly assumes that the noise added has a scale of G, while in reality, the scale is sG, where s is a positive scalar. This discrepancy leads to an approximate DP guarantee that holds only for values of s greater than or equal to 1.
We evaluate the effectiveness of property testers in detecting this bug and show that HockeyStickPropertyTester and RényiPropertyTester exhibit superior performance in identifying privacy violations, outperforming MMDPropertyTester and HistogramPropertyTester. Notably, these testers detect the bug even for values of s as high as 0.6. It is worth highlighting that s = 0.5 corresponds to a common error in literature that involves missing a factor of two when accounting for the privacy budget ε. DP-Auditorium successfully captures this bug as shown below. For more details see section 5.6 here.
 |
| Estimated divergences and test thresholds for different values of s when testing DP-GD with the HistogramPropertyTester (left) and the HockeyStickPropertyTester (right). |
 |
| Estimated divergences and test thresholds for different values of s when testing DP-GD with the RényiPropertyTester (left) and the MMDPropertyTester (right) |
To test dataset finders, we compute the number of datasets explored before finding a privacy violation. On average, the majority of bugs are discovered in less than 10 calls to dataset finders. Randomized and exploration/exploitation methods are more efficient at finding datasets than grid search. For more details, see the paper.
Conclusion
DP is one of the most powerful frameworks for data protection. However, proper implementation of DP mechanisms can be challenging and prone to errors that cannot be easily detected using traditional unit testing methods. A unified testing framework can help auditors, regulators, and academics ensure that private mechanisms are indeed private.
DP-Auditorium is a new approach to testing DP via divergence optimization over function spaces. Our results show that this type of function-based estimation consistently outperforms previous black-box access testers. Finally, we demonstrate that these function-based estimators allow for a better discovery rate of privacy bugs compared to histogram estimation. By open sourcing DP-Auditorium, we aim to establish a standard for end-to-end testing of new differentially private algorithms.
Acknowledgements
The work described here was done jointly with Andrés Muñoz Medina, William Kong and Umar Syed. We thank Chris Dibak and Vadym Doroshenko for helpful engineering support and interface suggestions for our library.