Posted by Enrique Alfonseca, Staff Research Scientist, Google Assistant
Voice interactions with technology are becoming a key part of our lives — from asking your phone for traffic conditions to work to using a smart device at home to turn on the lights or play music. The Google Assistant is designed to provide help and information across a variety of platforms, and is built to bring together a number of products — including Google Maps, Search, Google Photos, third party services, and more. For some of these products, we have released specific evaluation guidelines, like Search Quality Rating Guidelines. However, the Google Assistant needs its own guidelines in place, as many of its interactions utilize what is called “eyes-free technology,” when there is no screen as part of the experience.
In the past we have received requests to see our evaluation guidelines from academics who are researching improvements in voice interactions, question answering and voice-guided exploration. To facilitate their evaluations, we are publishing some of the first Google Assistant guidelines. It is our hope that making these guidelines public will help the research community build and evaluate their own systems. Creating the Guidelines For many queries, responses are presented on the display (like a phone) with a graph, a table, or an interactive element, like you’d see for [weather this weekend].
But spoken responses are very different from display results, as what’s on screen needs to be translated into useful speech. Furthermore, the contents of the voice response are sometimes sourced from the web, and in those cases it’s important to provide the user with a link to the original source. While users looking at their mobile device can click through to read the original web page, an eyes free solution presents unique challenges. In order to generate the optimal audio response, we use a combination of explicit linguistic knowledge and deep learning solutions that allow us to keep answers grammatical, fluent and concise.
How do we ensure that we consistently meet user expectations on quality, across all answer types and languages? One of the tools we use to measure that are human evaluations. In these, we ask raters to make sure that answers are satisfactory across several dimensions:
Information Satisfaction: the content of the answer should meet the information needs of the user.
Length: when a displayed answer is too long, users can quickly scan it visually and locate the relevant information. For voice answers, that is not possible. It is much more important to ensure that we provide a helpful amount of information, hopefully not too much or too little. Some of our previous work is currently in use for identifying the most relevant fragments of answers.
Formulation: it is much easier to understand a badly formulated written answer than an ungrammatical spoken answer, so more care has to be placed in ensuring grammatical correctness.
Elocution: spoken answers must have proper pronunciation and prosody. Improvements in text-to-speech generation, such as WaveNet and Tacotron 2, are quickly reducing the gap with human performance.
The current version of the guidelines can be found here. Of course, guidelines are often updated, and these are just a snapshot of something that is a living, changing, always-work-in-progress evaluation!
Posted by Jonathan Shen and Ruoming Pang, Software Engineers, on behalf of the Google Brain and Machine Perception Teams
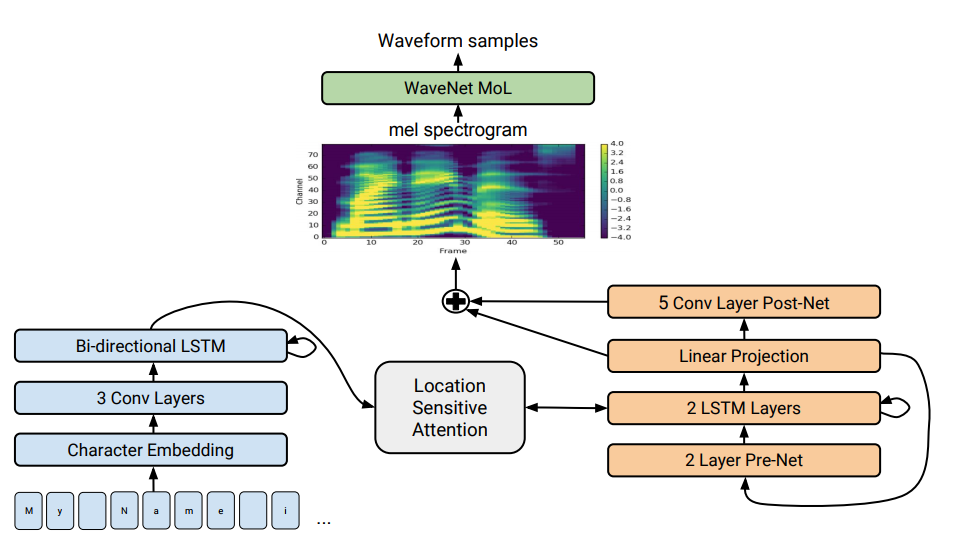
Generating very natural sounding speech from text (text-to-speech, TTS) has been a research goal for decades. There has been great progress in TTS research over the last few years and many individual pieces of a complete TTS system have greatly improved. Incorporating ideas from past work such as Tacotron and WaveNet, we added more improvements to end up with our new system, Tacotron 2. Our approach does not use complex linguistic and acoustic features as input. Instead, we generate human-like speech from text using neural networks trained using only speech examples and corresponding text transcripts.
A full description of our new system can be found in our paper “Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions.” In a nutshell it works like this: We use a sequence-to-sequence model optimized for TTS to map a sequence of letters to a sequence of features that encode the audio. These features, an 80-dimensional audio spectrogram with frames computed every 12.5 milliseconds, capture not only pronunciation of words, but also various subtleties of human speech, including volume, speed and intonation. Finally these features are converted to a 24 kHz waveform using a WaveNet-like architecture.
A detailed look at Tacotron 2's model architecture. The lower half of the image describes the sequence-to-sequence model that maps a sequence of letters to a spectrogram. For technical details, please refer to the paper.
You can listen to some of the Tacotron 2 audio samples that demonstrate the results of our state-of-the-art TTS system. In an evaluation where we asked human listeners to rate the naturalness of the generated speech, we obtained a score that was comparable to that of professional recordings.
While our samples sound great, there are still some difficult problems to be tackled. For example, our system has difficulties pronouncing complex words (such as “decorum” and “merlot”), and in extreme cases it can even randomly generate strange noises. Also, our system cannot yet generate audio in realtime. Furthermore, we cannot yet control the generated speech, such as directing it to sound happy or sad. Each of these is an interesting research problem on its own.
Acknowledgements Jonathan Shen, Ruoming Pang, Ron J. Weiss, Mike Schuster, Navdeep Jaitly, Zongheng Yang, Zhifeng Chen, Yu Zhang, Yuxuan Wang, RJ Skerry-Ryan, Rif A. Saurous, Yannis Agiomyrgiannakis, Yonghui Wu, Sound Understanding team, TTS Research team, and TensorFlow team.
Posted by Martin Jansche, Software Engineer, Google Research for Low Resource Languages
This is the third episode in the series of posts reporting on the work we are doing to build text-to-speech (TTS) systems for low resource languages. In the first episode, we described the crowdsourced acoustic data collection effort for Project Unison. In the second episode, we described how we built parametric voices based on that data. In this episode, we look at how we are compiling a pronunciation lexicon for a TTS system.
In Project Unison we are developing ways to bring Google's spoken language technology to the world’s major languages. As part of this broader goal, we are piloting a process for building a text-to-speech (TTS) system that can speak Bengali (Bangla). While our exploration of new methods have allowed us to gather sufficient data to train a statistical parametric voice capable of speaking Bengali, we had to address the next challenge: How do we make the voice sound like it is fluent in that language?
When people learn foreign languages, they are usually expected to pick up the full details from repeated exposure once they've mastered the basics and reached sufficient fluency. Often second-language learners struggle with issues that may seem so natural to fluent speakers that they are taken for granted. For instance, in order to read text out loud, one must know how to read different kinds of numerical expressions (e.g. dates, times, phone numbers, Roman numerals), and how to pronounce a wide variety of words, ranging from native words to newly coined brand names to loanwords, which themselves can arrive from different source languages. As TTS systems heavily rely on machine learning, they tend to face similar challenges as human learners: the way words are pronounced is often complex, sometimes surprising, and rarely fully documented.
Take the Bengali word meaning "microscope", which is অণুবীক্ষণ. Its pronunciation can be transcribed in the International Phonetic Alphabet as /o.nu.bik.kʰɔn/. When our system encounters this word, it analyzes the spelling in Bengali script into abstract written units called graphemes and then predicts the spoken sounds, or phonemes, of Bengali phonology from these graphemes.
The correspondence between graphemes and phonemes varies along several dimensions. One dimension is horizontal complexity: in many cases a single grapheme corresponds to a single phoneme, but the Bengali ligature ক্ষ is special, as several graphemes correspond to several phonemes in a somewhat surprising way. Another dimension is vertical predictability: a grapheme may correspond to different phonemes in different contexts and the correct phoneme may be difficult to predict. The Bengali grapheme “a” / “-a” is both very frequent and its pronunciation very unpredictable. It either corresponds to the phoneme /o/ or to the phoneme /ɔ/ or it is not pronounced. In the table above, we see all three possibilities within one word. As is standard in speech processing, our approach relies on human experts who transcribe words into phoneme sequences and machine learning models that capture the complex aspect of the grapheme-phoneme correspondence.
In order for our Bengali TTS system to pronounce the words in a sentence, it relies on a pronunciation dictionary, or lexicon, that provides pronunciations of a number of common words. When a word is not in the lexicon, it falls back on a machine learning model that was trained on thousands of pronunciations, which can then provide a pretty good guess at how a previously unseen word is pronounced. With a sufficiently large pronunciation dictionary, the system can be expected to reach a high level of fluency.
We first started compiling a Bengali pronunciation lexicon, with our Bangladeshi linguists transcribing a few thousand words into phonemes. This work was done in a web application that had been custom built for this purpose. Just like an earlier version, this transcription tool supports the work of linguists by providing a virtual keyboard for entering phonemes.
Once a few thousand words had been transcribed, we trained a machine learning system that could predict phonemic transcriptions for previously unseen words, so that the linguists only had to correct the output of that system. After the TTS voice had been built, it also became possible to listen to the voice reading out the entered transcriptions.
Even before the first machine learning model had been trained for Bengali, we configured the transcription tool to provide some constraints on how words could be transcribed. Bengali, like most writing systems, has certain aspects that make it complex, while in other ways it is quite regular. As discussed above, the grapheme “a” (অ) can have different pronunciations depending on context, but its pronunciation does not vary wildly: it is either silent or pronounced as a vowel, never as a consonant. By incorporating constraints on which graphemes can correspond to which phonemes, we can easily identify unlikely or erroneous transcriptions. This methodology has been in use at Google for several years.
The grapheme-phoneme correspondence varies along several dimensions, including regular words vs. abbreviations, and native words vs. loanwords. For example the word meaning "doctor" and pronounced /ɖɔk.ʈor/ can be written in several ways in Bengali: in Bengali script as ডক্টর or as the abbreviation ডঃ; and in Latin script as the English loanword doctor or as the abbreviation Dr. A TTS system should accept all ways of writing this word, hence all written variations are in our pronunciation lexicon.
A Bengali TTS voice should further be able to pronounce a variety of common brand names written in Latin script. The linguists from Project Unison therefore transcribed a few thousand such words phonemically into Bengali. For example, "WhatsApp" was transcribed /ho.aʈs.æp/, and "Google" was straightforwardly transcribed as /gu.gol/ just as if it had been spelled গুগল.
Overall our linguists transcribed more than 65,000 Bengali words into phonemic notation. In an effort to contribute to the community working on speech synthesis, speech recognition, and related natural language efforts, we are releasing our Bengali pronunciation dictionary under a Creative Commons License (CC BY 4.0). It is our hope that this will be a valuable resource for researchers and developers who are improving the state of spoken language systems.
Despite our efforts, this Bengali dictionary is incomplete and contains residual errors. As a work-in-progress it will continue to improve over time. We are hoping that other natural language and speech researchers will join us in making available more datasets under open licenses. As we refine our development process and extend it to more languages, we are planning on releasing additional datasets for other languages in the future.
This is the second episode in the series of posts reporting on the work we are doing to build text-to-speech (TTS) systems for low resource languages. In the previous episode, we described the crowdsourced data collection effort for Project Unison. In this episode, we describe our work to construct a parametric voice based on that data.
In our previous episode, we described building TTS systems for low resource languages, and how one of the objectives of data collection for such systems was to quickly build a database representing multiple speakers. There are two main justifications for this approach. First, professional voice talents are often not available for under-resourced languages, so we need to record ordinary people who get tired reading tedious text rather quickly. Hence, the amount of text a person can record is rather limited and we need multiple speakers for a reasonably sized database that can be used by others as well. Second, we wanted to be able to create a voice that sounds human but is not identifiable as a real person. Various concatenative approaches to speech synthesis, such as unit selection, are not very suitable for this problem. This is because the selection algorithm may join acoustic units from different speakers generating a very unnatural sounding result.
Adopting parametric speech synthesis techniques is an attractive approach to building multi-speaker corpora described above. This is because in parametric synthesis the training stage of the statistical component will take care of multiple-speakers by estimating an averaged out representation of various acoustic parameters representing each individual speaker. Depending on number of speakers in the corpus, their acoustic similarity and ratio of speaker genders, the resulting acoustic model can represent an average voice that is indistinguishable from human and yet cannot be traced back to any actual speakers recorded during the data collection.
We decided to use two different approaches to acoustic modeling in our experiments. The first approach uses Hidden Markov Models (HMMs). This well-established technique was pioneered by Prof. Keiichi Tokuda at Nagoya Institute of Technology, Japan and has been widely adopted in academia and industry. It is also supported by a dedicated open-source HMM synthesis toolkit. The resulting models are small enough to fit on mobile devices.
The second approach relies on Recurrent Neural Networks (RNNs). RNNs have feedback loops in their topology, allowing them to model temporal dependencies between various phonemes in human speech. In 2013, Heiga Zen, Andrew Senior and Mike Schuster proposed a neural network-based model that mimics deep structure of human speech production for speech synthesis. The model has further been extended into a Long Short-Term Memory (LSTM) RNN. This allows long term memorization, which is good for speech applications. Earlier this year, Heiga Zen and Hasim Sak described the LSTM RNN architecture that has been specifically designed for fast speech synthesis. The LSTM RNNs are also used in our Automatic Speech Recognition (ASR) systems recently mentioned in our blog.
Using the Hidden Markov Model (HMM) and LSTM RNN synthesizers described above, we experimented with a multi-speaker Bangla corpus totaling 1526 utterances (waveforms and corresponding transcriptions) from five different speakers. We also built a third system that utilizes LSTM RNN acoustic model, but this time we made it small and fast enough to run on a mobile phone.
We synthesized the following Bangla sentence "এটি একটি বাংলা বাক্যের উদাহরণ" translated from “This is an example sentence in Bangla”. Though HMM synthesizer output can sound intelligible, it does exhibit some classic downsides with a voice that sounds buzzy and muffled. With the LSTM RNN configuration for mobile devices, the resulting audio sounds clearer and has improved intonation over the HMM version. We also tried a LSTM RNN configuration with more network nodes (and thus not suitable for low-end mobile devices) to generate this waveform - the quality is slightly better but is not a huge improvement over the more lightweight LSTM RNN version. We hypothesize that this is due to the fact that a neural network with many nodes has more parameters and thus requires more data to train.
These early results are encouraging for several reasons. First, they confirm that natural-sounding speech synthesis based on multiple speakers is practically possible. It is also significant that the total number of recordings used was relatively small, yet were able to build intelligible parametric speech synthesis. This means that it is possible to collect training data for such a speech synthesizer by engaging the help of volunteers who are not professional voice artists, for a short period of time per person. Using multiple volunteers is an advantage: it results in more diverse data, and the resulting synthetic voice does not represent any specific individual. This approach may well be the foundation for bringing speech technology to many more traditionally under-served languages.
Posted by Linne Ha, Senior Program Manager, Google Research for Low Resource Languages
Building a decent text-to-speech (TTS) voice for any language can be challenging, but creating one – a good, intelligible one – for a low resource language can be downright impossible. By definition, working with low resource languages can feel like a losing proposition – from the get go, there is not enough audio data, and the data that exists may be questionable in quality. High quality audio data, and lots of it, is key to developing a high quality machine learning model. To make matters worse, most of the world’s oldest, richest spoken languages fall into this category. There are currently over 300 languages, each spoken by at least one million people, and most will be overlooked by technologists for various reasons. One important reason is that there is not enough data to conduct meaningful research and development.
Project Unison is an on-going Google research effort, in collaboration with the Speech team, to explore innovative approaches to building a TTS voice for low resource languages – quickly, inexpensively and efficiently. This blog post will be one of several to track progress of this experiment and to share our experience with the research community at large – our successes and failures in a trial and error, iterative approach – as our adventure plays out.
One of the most critical aspects of building a TTS system is acquiring audio data. The traditional way to do this is in a professional recording studio with a voice talent, sound engineer and a voice director. The process can take considerable time and can be quite expensive. People often mistake voice talent work to be similar to a news reader, but it is highly specialized and the work can be very difficult.
Such investments in time and money may yield great audio, but the catch is that even if you’ve created the best TTS voice from these recordings, at best it will still sound exactly like the voice talent - the person who provided the raw audio data. (We’ve read the articles about people who have fallen for their GPS voice to find that they are real people with real names.) So the interesting problem here from a research perspective is how to create a voice that sounds human but is not identifiable as a singular person.
Crowd-sourcing projects for automatic speech recognition (ASR) for Google Voice Search had been successful in the past, with public volunteers eager to participate by providing voice samples. For ASR, the objective is to collect from a diversity of speakers and environments, capturing varying regional accents. The polar opposite is true of TTS, where one unique speaker, with the standard accent and in a soundproof studio is the basic criteria.
Many years ago, Yannis Agiomyrgiannakis, Digital Signal Processing researcher on the TTS team in Google London, wrote a “manifesto” for acoustic data collection for 2000 languages. In his document, he gave technical specifications on how to convert an average room into a recording studio. Knot Pipatsrisawat, software engineer in Google Research for Low Resource Languages, built a tool that we call “ChitChat”, a portable recording studio, using Yannis’ specifications. This web app allows users to read the prompt, playback the recording and even assess the noise level of the room.
From other past research in ASR, we knew that the right tool could solve the crowd sourcing problem. ChitChat allowed us to experiment in different environments to get an idea of what kind of office space would work and what kind of problems we might encounter. After experimenting with several different laptops and tablets, we were able to find a computer that recognized the necessary peripherals (the microphone, USB converter, and preamp) for under $2,000 – much cheaper than a recording studio!
Now we needed multiple speakers of a single language. For us, it was a no-brainer to pilot Project Unison with Bangladeshi Googlers, all of whom are passionate about getting Google products to their home country (the success of Android products in Bangladesh is an example of this). Googlers by and large are passionate about their work and many offer their 20% time as a way to help, to improve or to experiment on something that may or may not work because they care. The Bangladeshi Googlers are no exception. They embodied our objectives for a crowdsourcing innovation: out of many, we could achieve (literally) one voice.
With multiple speakers, we would target speakers of similar vocal profiles and adapt them to create a blended voice. Statistical parametric synthesis is not new, but the advances in recent technology have improved quality and proved to be a lightweight solution for a project like ours.
In May of this year, we auditioned 15 Bangaldeshi Googlers in Mountain View. From these recordings, the broader Bangladeshi Google community voted blindly for their preferred voice. Zakaria Haque, software engineer in Machine Intelligence, was chosen as our reference for the Bangla voice. We then narrowed down the group to five speakers based on these criteria: Dhaka accent, male (to match Zakaria’s), similarity in pitch and tone, and availability for recordings. The original plan of a spectral analysis using PRAAT proved to be unnecessary with our limited pool of candidates.
All 5 software engineers – Ahmed Chowdury, Mohammad Hossain, Syeed Faiz, Md. Arifuzzaman Arif, Sabbir Yousuf Sanny – plus Zakaria Haque recorded over 3 days in the anechoic chamber, a makeshift sound-proofed room at the Mountain View campus just before Ramadan. HyunJeong Choe, who had helped with the Korean TTS recordings, directed our volunteers.
Left: TPM Mohammad Khan measures the distance from the speaker to the mic to keep the sound quality consistent across all speakers. Right: Analytical Linguist HyunJeong Choe coaches SWE Ahmed Chowdury on how to speak in a friendly, knowledgeable, "Googly" voice
ChitChat allowed us to troubleshoot on the fly as recordings could be monitored from another room using the admin panel. In total, we recorded 2000 Bangla and English phrases mined from Wikipedia. In 30-60 minute intervals, the participants recorded over 250 sentences each.
In this session, we discovered an issue: a sudden drop in amplitude at high frequencies in a few recordings. We were worried that all the recordings might have to be scrapped.
As illustrated in the third image, speaker3 has a drop in energy above 13kHz which is visible in the graph and may be present at speech, distorting the speaker’s voice to sound as if he were speaking through a tube.
Another challenge was that we didn’t have a pronunciation lexicon for Bangla as spoken in Bangladesh. We worked initially with the publicly available TTS data from the Indian Institute of Information Technology, but this represented the variant of Bangla spoken in West Bengal (India), which differs from the speech we recorded. Our internally designed pronunciation rules for Bengali were also aimed at West Bengal and would need to be revised later.
Deciding to proceed anyway, Alexander Gutkin, Speech software engineer and lead for TTS for Low Resource Languages in Google London, built an initial prototype voice. Using the preliminary text normalization rules created by Richard Sproat, Speech and Language Processing researcher, the first voice we attempted proved to be surprisingly good. The problem in the high frequencies we had seen in the recordings is undetectable in the parametric voice. When we return to the sound studio to record an additional 200 longer sentences, we plan to try an upgrade of the USB converter. Meanwhile, Martin Jansche, Natural Language Understanding software engineer, has worked with a team of native speakers on a pronunciation and lexicon and model that better matches the phonology of colloquial Bangladeshi Bangla. Alexander will use the additional recordings and the new pronunciation dictionary to build the second version.
NEXT UP: Building a parametric voice with multiple speaker data (Ep.2)