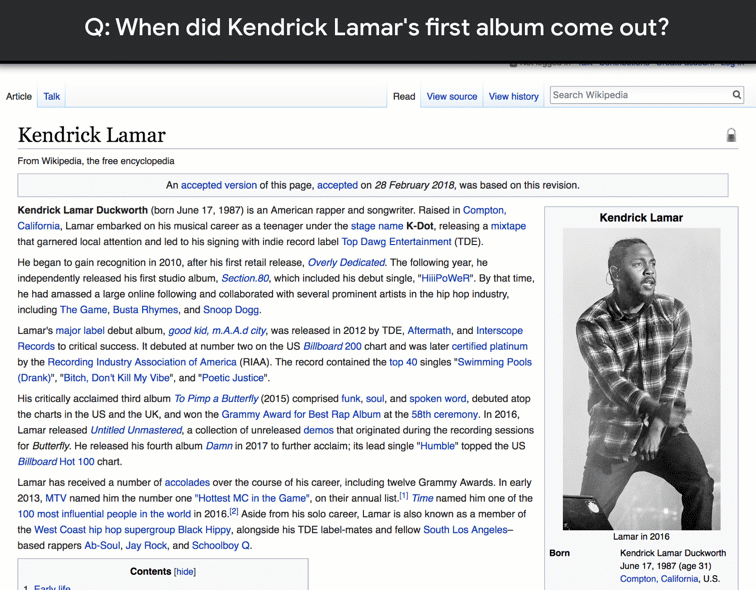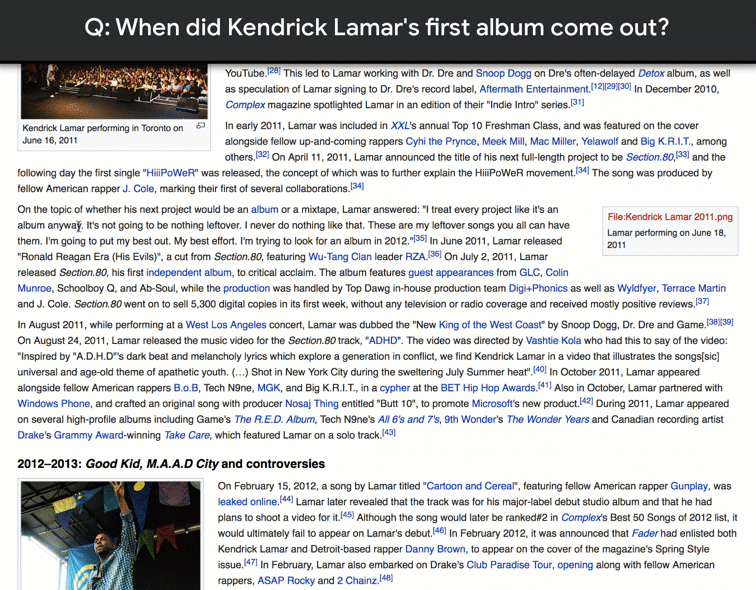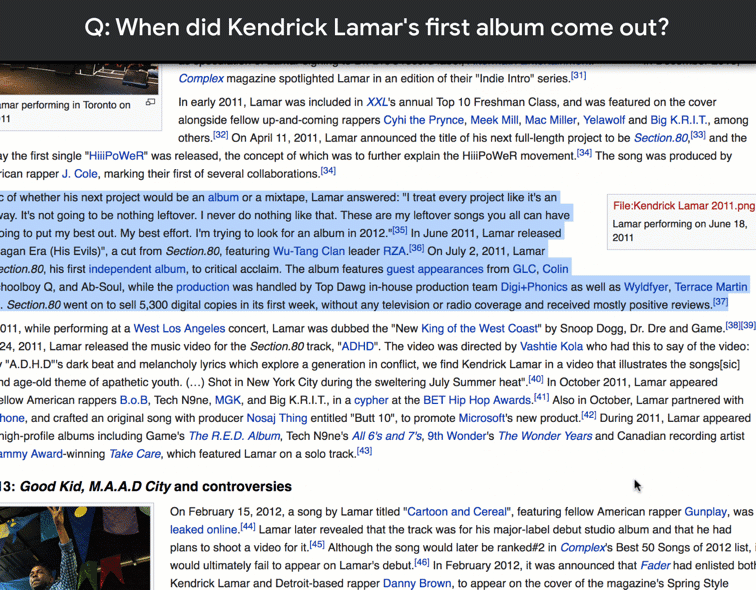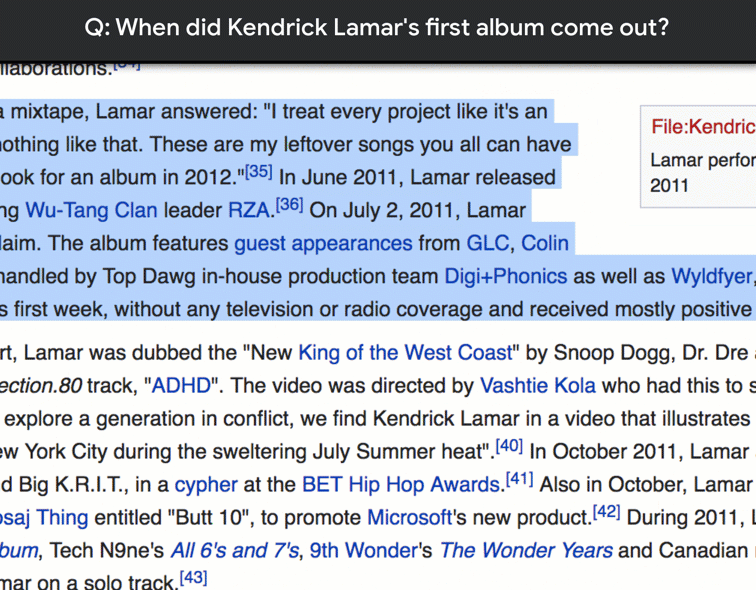
Posted by Tom Kwiatkowski and Michael Collins, Research Scientists, Google AI Language
Open-domain question answering (QA) is a benchmark task in natural language understanding (NLU) that aims to emulate how people look for information, finding answers to questions by reading and understanding entire documents. Given a question expressed in natural language ("Why is the sky blue?"), a QA system should be able to read the web (such as this Wikipedia page) and return the correct answer, even if the answer is somewhat complicated and long. However, there are currently no large, publicly available sources of naturally occurring questions (i.e. questions asked by a person seeking information) and answers that can be used to train and evaluate QA models. This is because assembling a high-quality dataset for question answering requires a large source of real questions and significant human effort in finding correct answers.
To help spur research advances in QA, we are excited to announce Natural Questions (NQ), a new, large-scale corpus for training and evaluating open-domain question answering systems, and the first to replicate the end-to-end process in which people find answers to questions. NQ is large, consisting of 300,000 naturally occurring questions, along with human annotated answers from Wikipedia pages, to be used in training QA systems. We have additionally included 16,000 examples where answers (to the same questions) are provided by 5 different annotators, useful for evaluating the performance of the learned QA systems. Since answering the questions in NQ requires much deeper understanding than is needed to answer trivia questions — which are already quite easy for computers to solve — we are also announcing a challenge based on this data to help advance natural language understanding in computers.
The Data NQ is the first dataset to use naturally occurring queries and focus on finding answers by reading an entire page, rather than extracting answers from a short paragraph. To create NQ, we started with real, anonymized, aggregated queries that users have posed to Google's search engine. We then ask annotators to find answers by reading through an entire Wikipedia page as they would if the question had been theirs. Annotators look for both long answers that cover all of the information required to infer the answer, and short answers that answer the question succinctly with the names of one or more entities. The quality of the annotations in the NQ corpus has been measured at 90% accuracy.
The Challenge NQ is aimed at enabling QA systems to read and comprehend an entire Wikipedia article that may or may not contain the answer to the question. Systems will need to first decide whether the question is sufficiently well defined to be answerable — many questions make false assumptions or are just too ambiguous to be answered concisely. Then they will need to decide whether there is any part of the Wikipedia page that contains all of the information needed to infer the answer. We believe that the long answer identification task — finding all of the information required to infer an answer — requires a deeper level of language understanding than finding short answers once the long answers are known.
It is our hope that the release of NQ, and the associated challenge, will help spur the development of more effective and robust QA systems. We encourage the NLU community to participate and to help close the large gap between the performance of current state-of-the-art approaches and a human upper bound. Please visit the challenge website to view the leaderboard and learn more.
Posted by Jacob Devlin and Ming-Wei Chang, Research Scientists, Google AI Language
One of the biggest challenges in natural language processing (NLP) is the shortage of training data. Because NLP is a diversified field with many distinct tasks, most task-specific datasets contain only a few thousand or a few hundred thousand human-labeled training examples. However, modern deep learning-based NLP models see benefits from much larger amounts of data, improving when trained on millions, or billions, of annotated training examples. To help close this gap in data, researchers have developed a variety of techniques for training general purpose language representation models using the enormous amount of unannotated text on the web (known as pre-training). The pre-trained model can then be fine-tuned on small-data NLP tasks like question answering and sentiment analysis, resulting in substantial accuracy improvements compared to training on these datasets from scratch.
This week, we open sourced a new technique for NLP pre-training called Bidirectional Encoder Representations from Transformers, or BERT. With this release, anyone in the world can train their own state-of-the-art question answering system (or a variety of other models) in about 30 minutes on a single Cloud TPU, or in a few hours using a single GPU. The release includes source code built on top of TensorFlow and a number of pre-trained language representation models. In our associated paper, we demonstrate state-of-the-art results on 11 NLP tasks, including the very competitive Stanford Question Answering Dataset (SQuAD v1.1).
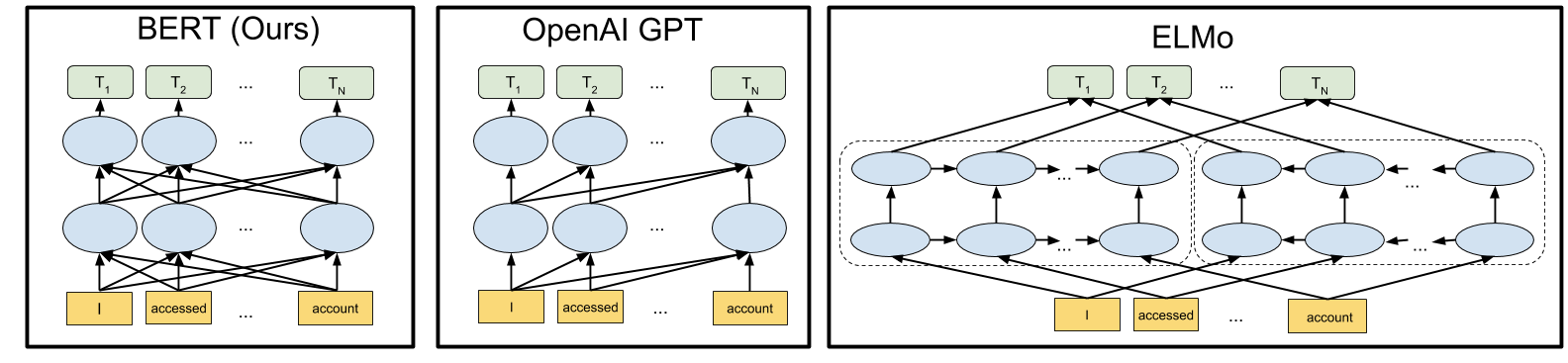
What Makes BERT Different? BERT builds upon recent work in pre-training contextual representations — including Semi-supervised Sequence Learning, Generative Pre-Training, ELMo, and ULMFit. However, unlike these previous models, BERT is the first deeply bidirectional, unsupervised language representation, pre-trained using only a plain text corpus (in this case, Wikipedia).
Why does this matter? Pre-trained representations can either be context-free or contextual, and contextual representations can further be unidirectional or bidirectional. Context-free models such as word2vec or GloVe generate a single word embedding representation for each word in the vocabulary. For example, the word “bank” would have the same context-free representation in “bank account” and “bank of the river.” Contextual models instead generate a representation of each word that is based on the other words in the sentence. For example, in the sentence “I accessed the bank account,” a unidirectional contextual model would represent “bank” based on “I accessed the” but not “account.” However, BERT represents “bank” using both its previous and next context — “I accessed the ... account” — starting from the very bottom of a deep neural network, making it deeply bidirectional.
A visualization of BERT’s neural network architecture compared to previous state-of-the-art contextual pre-training methods is shown below. The arrows indicate the information flow from one layer to the next. The green boxes at the top indicate the final contextualized representation of each input word:
BERT is deeply bidirectional, OpenAI GPT is unidirectional, and ELMo is shallowly bidirectional.
The Strength of Bidirectionality If bidirectionality is so powerful, why hasn’t it been done before? To understand why, consider that unidirectional models are efficiently trained by predicting each word conditioned on the previous words in the sentence. However, it is not possible to train bidirectional models by simply conditioning each word on its previous and next words, since this would allow the word that’s being predicted to indirectly “see itself” in a multi-layer model.
To solve this problem, we use the straightforward technique of masking out some of the words in the input and then condition each word bidirectionally to predict the masked words. For example:
While this idea has been around for a very long time, BERT is the first time it was successfully used to pre-train a deep neural network.
BERT also learns to model relationships between sentences by pre-training on a very simple task that can be generated from any text corpus: Given two sentences A and B, is B the actual next sentence that comes after A in the corpus, or just a random sentence? For example:
Training with Cloud TPUs Everything that we’ve described so far might seem fairly straightforward, so what’s the missing piece that made it work so well? Cloud TPUs. Cloud TPUs gave us the freedom to quickly experiment, debug, and tweak our models, which was critical in allowing us to move beyond existing pre-training techniques. The Transformer model architecture, developed by researchers at Google in 2017, also gave us the foundation we needed to make BERT successful. The Transformer is implemented in our open source release, as well as the tensor2tensor library.
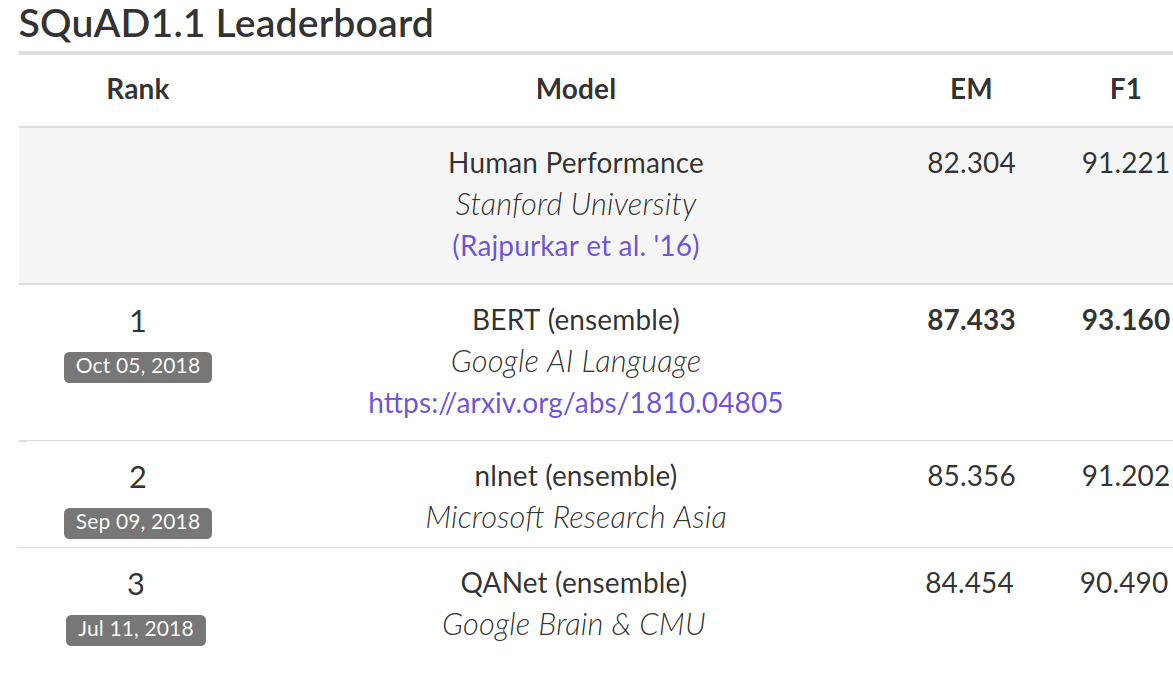
Results with BERT To evaluate performance, we compared BERT to other state-of-the-art NLP systems. Importantly, BERT achieved all of its results with almost no task-specific changes to the neural network architecture. On SQuAD v1.1, BERT achieves 93.2% F1 score (a measure of accuracy), surpassing the previous state-of-the-art score of 91.6% and human-level score of 91.2%:
BERT also improves the state-of-the-art by 7.6% absolute on the very challenging GLUE benchmark, a set of 9 diverse Natural Language Understanding (NLU) tasks. The amount of human-labeled training data in these tasks ranges from 2,500 examples to 400,000 examples, and BERT substantially improves upon the state-of-the-art accuracy on all of them:
Making BERT Work for You The models that we are releasing can be fine-tuned on a wide variety of NLP tasks in a few hours or less. The open source release also includes code to run pre-training, although we believe the majority of NLP researchers who use BERT will never need to pre-train their own models from scratch. The BERT models that we are releasing today are English-only, but we hope to release models which have been pre-trained on a variety of languages in the near future.
Posted by Manaal Faruqui, Senior Research Scientist and Emily Pitler, Staff Research Scientist, Google AI Language
This week, the annual conference on Empirical Methods in Natural Language Processing (EMNLP 2018) will be held in Brussels, Belgium. Google will have a strong presence at EMNLP with several of our researchers presenting their research on a diverse set of topics, including language identification, segmentation, semantic parsing and question answering, additionally serving in various levels of organization in the conference. Googlers will also be presenting their papers and participating in the co-located Conference on Computational Natural Language Learning (CoNLL 2018) shared task on multilingual parsing.
In addition to this involvement, we are sharing several new datasets with the academic community that are released with papers published at EMNLP, with the goal of accelerating progress in empirical natural language processing (NLP). These releases are designed to help account for mismatches between the datasets a machine learning model is trained and tested on, and the inputs an NLP system would be asked to handle “in the wild”. All of the datasets we are releasing include realistic, naturally occurring text, and fall into two main categories: 1) challenge sets for well-studied core NLP tasks (part-of-speech tagging, coreference) and 2) datasets to encourage new directions of research on meaning preservation under rephrasings/edits (query well-formedness, split-and-rephrase, atomic edits):
Noun-Verb Ambiguity in POS Tagging Dataset: English part-of-speech taggers regularly make egregious errors related to noun-verb ambiguity, despite high accuracies on standard datasets. For example: in “Mark which area you want to distress” several state-of-the-art taggers annotate “Mark” as a noun instead of a verb. We release a new dataset of over 30,000 naturally occurring non-trivial annotated examples of noun-verb ambiguity. Taggers previously indistinguishable from each other have accuracies ranging from 57% to 75% accuracy on this challenge set.
Query Wellformedness Dataset: Web search queries are usually “word-salad” style queries with little resemblance to natural language questions (“barack obama height” as opposed to “What is the height of Barack Obama?”). Differentiating a natural language question from a query is of importance to several applications include dialogue. We annotate and release 25,100 queries from the open-source Paralex corpus with ratings on how close they are to well-formed natural language questions.
WikiSplit: Split and Rephrase Dataset Extracted from Wikipedia Edits: We extract examples of sentence splits from Wikipedia edits where one sentence gets split into two sentences that together preserve the original meaning of the sentence (E.g. “Street Rod is the first in a series of two games released for the PC and Commodore 64 in 1989.” is split into “Street Rod is the first in a series of two games.” and “It was released for the PC and Commodore 64 in 1989.”) The released corpus contains one million sentence splits with a vocabulary of more than 600,000 words.
WikiAtomicEdits: A Multilingual Corpus of Atomic Wikipedia Edits: Information about how people edit language in Wikipedia can be used to understand the structure of language itself. We pay particular attention to two atomic edits: insertions and deletions that consist of a single contiguous span of text. We extract around 43 million such edits in 8 languages and show that they provide valuable information about entailment and discourse. For example, insertion of “in 1949” adds a prepositional phrase to the sentence “She died there after a long illness” resulting in “She died there in 1949 after a long illness”.
Below is a full list of Google’s involvement and publications being presented at EMNLP and CoNLL (Googlers highlighted in blue). We are particularly happy to announce that the paper “Linguistically-Informed Self-Attention for Semantic Role Labeling” was awarded one of the two Best Long Paper awards. This work was done by our 2017 intern Emma Strubell, Googlers Daniel Andor, David Weiss and Google Faculty Advisor Andrew McCallum. We congratulate these authors, and all other researchers who are presenting their work at the conference.
Area Chairs Include: Ming-Wei Chang, Marius Pasca, Slav Petrov, Emily Pitler, Meg Mitchell, Taro Watanabe
Universal Sentence Encoder for English Daniel Cer, Yinfei Yang, Sheng-yi Kong, Nan Hua, Nicole Limtiaco, Rhomni St. John, Noah Constant, Mario Guajardo-Cespedes, Steve Yuan, Chris Tar, Brian Strope, Ray Kurzweil
Posted by Michelle Chen Huebscher, Software Engineer and Rodrigo Nogueira, New York University PhD Student and Software Engineering Intern, Google AI Language
Natural language understanding is a significant ongoing focus of Google’s AI research, with application to machine translation, syntactic and semantic parsing, and much more. Importantly, as conversational technology increasingly requires the ability to directly answer users’ questions, one of the most active areas of research we pursue is question answering (QA), a fundamental building block of human dialogue.
Active Question Answering In traditional QA, supervised learning techniques are used in combination with labeled data to train a system that answers arbitrary input questions. While this is effective, it suffers from a lack of ability to deal with uncertainty like humans would, by reformulating questions, issuing multiple searches, evaluating and aggregating responses. Inspired by humans’ ability to "ask the right questions", ActiveQA introduces an agent that repeatedly consults the QA system. In doing so, the agent may reformulate the original question multiple times in order to find the best possible answer. We call this approach active because the agent engages in a dynamic interaction with the QA system, with the goal of improving the quality of the answers returned.
For example, consider the question “When was Tesla born?”. The agent reformulates the question in two different ways: “When is Tesla’s birthday” and “Which year was Tesla born”, retrieving answers to both questions from the QA system. Using all this information it decides to return “July 10 1856”.
What characterizes an ActiveQA system is that it learns to ask questions that lead to good answers. However, because training data in the form of question pairs, with an original question and a more successful variant, is not readily available, ActiveQA uses reinforcement learning, an approach to machine learning concerned with training agents so that they take actions that maximize a reward, while interacting with an environment.
The learning takes place as the ActiveQA agent interacts with the QA system; each question reformulation is evaluated in terms of how good the corresponding answer is, which constitutes the reward. If the answer is good, then the learning algorithm will adjust the model’s parameters so that the question reformulation that lead to the answer is more likely to be generated again, or otherwise less likely, if the answer was bad.
In our paper, we show that it is possible to train such agents to outperform the underlying QA system, the one used to provide answers to reformulations, by asking better questions. This is an important result, as the QA system is already trained with supervised learning to solve the same task. Another compelling finding of our research is that the ActiveQA agent can learn a fairly sophisticated, and still somewhat interpretable, reformulation strategy (the policy in reinforcement learning). The learned policy uses well-known information retrieval techniques such as tf-idf query term re-weighting, the process by which more informative terms are weighted more than generic ones, and word stemming.
Build Your Own ActiveQA System The TensorFlow ActiveQA package we are releasing consists of three main components, and contains all the code necessary to train and run the ActiveQA agent.
A pretrained sequence to sequence model that takes as input a question and returns its reformulations. This task is similar to machine translation, translating from English to English, and indeed the initial model can be used for general paraphrasing. For its implementation we use and customize the TensorFlow Neural Machine Translation Tutorial code. We adapted the code to support training with reinforcement learning, using policy gradient methods.*
An answer selection model. The answer selector uses a convolutional neural network and assigns a score to each triplet of original question, reformulation and answer. The selector uses pre-trained, publicly available word embeddings (GloVe).
A question answering system (the environment). For this purpose we use BiDAF, a popular question answering system, described in Seo et al. (2017).
We also provide pointers to checkpoints for all the trained models.
Google’s mission is to organize the world's information and make it universally accessible and useful, and we believe that ActiveQA is an important step in realizing that mission. We envision that this research will help us design systems that provide better and more interpretable answers, and hope it will help others develop systems that can interact with the world using natural language.
Acknowledgments Contributors to this research and release include Alham Fikri Aji, Christian Buck, Jannis Bulian, Massimiliano Ciaramita, Wojciech Gajewski, Andrea Gesmundo, Alexey Gronskiy, Neil Houlsby, Yannic Kilcher, and Wei Wang.
* The system we reported on in our paper used the TensorFlow sequence-to-sequence code used in Britz et al. (2017). Later, an open source version of the Google Translation model (GNMT) was published as a tutorial. The ActiveQA version released today is based on this more recent, and actively developed implementation. For this reason the released system varies slightly from the paper’s. Nevertheless, the performance and behavior are qualitatively and quantitatively comparable.↩
Posted by Johan Schalkwyk, VP and Ignacio Lopez Moreno, Engineer, Google Speech
Multilingual households are becoming increasingly common, with several sources [1][2][3] indicating that multilingual speakers already outnumber monolingual counterparts, and that this number will continue to grow. With this large and increasing population of multilingual users, it is more important than ever that Google develop products that can support multiple languages simultaneously to better serve our users.
Today, we’re launching multilingual support for the Google Assistant, which enables users to jump between two different languages across queries, without having to go back to their language settings. Once users select two of the supported languages, English, Spanish, French, German, Italian and Japanese, from there on out they can speak to the Assistant in either language and the Assistant will respond in kind. Previously, users had to choose a single language setting for the Assistant, changing their settings each time they wanted to use another language, but now, it’s a simple, hands-free experience for multilingual households.
The Google Assistant is now able to identify the language, interpret the query and provide a response using the right language without the user having to touch the Assistant settings.
Getting this to work, however, was not a simple feat. In fact, this was a multi-year effort that involved solving a lot of challenging problems. In the end, we broke the problem down into three discrete parts: Identifying Multiple Languages, Understanding Multiple Languages and Optimizing Multilingual Recognition for Google Assistant users.
Identifying Multiple Languages People have the ability to recognize when someone is speaking another language, even if they do not speak the language themselves, just by paying attention to the acoustics of the speech (intonation, phonetic registry, etc). However, defining a computational framework for automatic spoken language recognition is challenging, even with the help of full automatic speech recognition systems1. In 2013, Google started working on spoken language identification (LangID) technology using deep neural networks [4][5]. Today, our state-of-the-art LangID models can distinguish between pairs of languages in over 2000 alternative language pairs using recurrent neural networks, a family of neural networks which are particularly successful for sequence modeling problems, such as those in speech recognition, voice detection, speaker recognition and others. One of the challenges we ran into was working with larger sets of audio — getting models that can automatically understanding multiple languages at scale, and hitting a quality standard that allowed those models to work properly.
Understanding Multiple Languages To understand more than one language at once, multiple processes need to be run in parallel, each producing incremental results, allowing the Assistant not only to identify the language in which the query is spoken but also to parse the query to create an actionable command. For example, even for a monolingual environment, if a user asks to “set an alarm for 6pm”, the Google Assistant must understand that "set an alarm" implies opening the clock app, fulfilling the explicit parameter of “6pm” and additionally make the inference that the alarm should be set for today. To make this work for any given pair of supported languages is a challenge, as the Assistant executes the same work it does for the monolingual case, but now must additionally enable LangID, and not just one but two monolingual speech recognition systems simultaneously (we’ll explain more about the current two language limitation later in this post).
Importantly, the Google Assistant and other services that are referenced in the user’s query asynchronously generate real-time incremental results that need to be evaluated in a matter of milliseconds. This is accomplished with the help of an additional algorithm that ranks the transcription hypotheses provided by each of the two speech recognition systems using the probabilities of the candidate languages produced by LangID, our confidence on the transcription and the user’s preferences (such as favorite artists, for example).
Schematic of our multilingual speech recognition system used by the Google Assistant versus the standard monolingual speech recognition system. A ranking algorithm is used to select the best recognition hypotheses from two monolingual speech recognizer using relevant information about the user and the incremental langID results.
When the user stops speaking, the model has not only determined what language was being spoken, but also what was said. Of course, this process requires a sophisticated architecture that comes with an increased processing cost and the possibility of introducing unnecessary latency.
Optimizing Multilingual Recognition To minimize these undesirable effects, the faster the system can make a decision about which language is being spoken, the better. If the system becomes certain of the language being spoken before the user finishes a query, then it will stop running the user’s speech through the losing recognizer and discard the losing hypothesis, thus lowering the processing cost and reducing any potential latency. With this in mind, we saw several ways of optimizing the system.
One use case we considered was that people normally use the same language throughout their query (which is also the language users generally want to hear back from the Assistant), with the exception of asking about entities with names in different languages. This means that, in most cases, focusing on the first part of the query allows the Assistant to make a preliminary guess of the language being spoken, even in sentences containing entities in a different language. With this early identification, the task is simplified by switching to a single monolingual speech recognizer, as we do for monolingual queries. Making a quick decision about how and when to commit to a single language, however, requires a final technological twist: specifically, we use a random forest technique that combines multiple contextual signals, such as the type of device being used, the number of speech hypotheses found, how often we receive similar hypotheses, the uncertainty of the individual speech recognizers, and how frequently each language is used.
An additional way we simplified and improved the quality of the system was to limit the list of candidate languages users can select. Users can choose two languages out of the six that our Home devices currently support, which will allow us to support the majority of our multilingual speakers. As we continue to improve our technology, however, we hope to tackle trilingual support next, knowing that this will further enhance the experience of our growing user base.
Bilingual to Trilingual From the beginning, our goal has been to make the Assistant naturally conversational for all users. Multilingual support has been a highly-requested feature, and it’s something our team set its sights on years ago. But there aren’t just a lot of bilingual speakers around the globe today, we also want to make life a little easier for trilingual users, or families that live in homes where more than two languages are spoken.
With today’s update, we’re on the right track, and it was made possible by our advanced machine learning, our speech and language recognition technologies, and our team’s commitment to refine our LangID model. We’re now working to teach the Google Assistant how to process more than two languages simultaneously, and are working to add more supported languages in the future — stay tuned!
1 It is typically acknowledged that spoken language recognition is remarkably more challenging than text-based language identification where, relatively simple techniques based on dictionaries can do a good job. The time/frequency patterns of spoken words are difficult to compare, spoken words can be more difficult to delimit as they can be spoken without pause and at different paces and microphones may record background noise in addition to speech.↩
Posted by Stephan Gouws, Research Scientist, Google Brain Team and Mostafa Dehghani, University of Amsterdam PhD student and Google Research Intern
Last year we released the Transformer, a new machine learning model that showed remarkable success over existing algorithms for machine translation and other language understanding tasks. Before the Transformer, most neural network based approaches to machine translation relied on recurrent neural networks (RNNs) which operate sequentially (e.g. translating words in a sentence one-after-the-other) using recurrence (i.e. the output of each step feeds into the next). While RNNs are very powerful at modeling sequences, their sequential nature means that they are quite slow to train, as longer sentences need more processing steps, and their recurrent structure also makes them notoriously difficult to train properly.
In contrast to RNN-based approaches, the Transformer used no recurrence, instead processing all words or symbols in the sequence in parallel while making use of a self-attention mechanism to incorporate context from words farther away. By processing all words in parallel and letting each word attend to other words in the sentence over multiple processing steps, the Transformer was much faster to train than recurrent models. Remarkably, it also yielded much better translation results than RNNs. However, on smaller and more structured language understanding tasks, or even simple algorithmic tasks such as copying a string (e.g. to transform an input of “abc” to “abcabc”), the Transformer does not perform very well. In contrast, models that perform well on these tasks, like the Neural GPU and Neural Turing Machine, fail on large-scale language understanding tasks like translation.
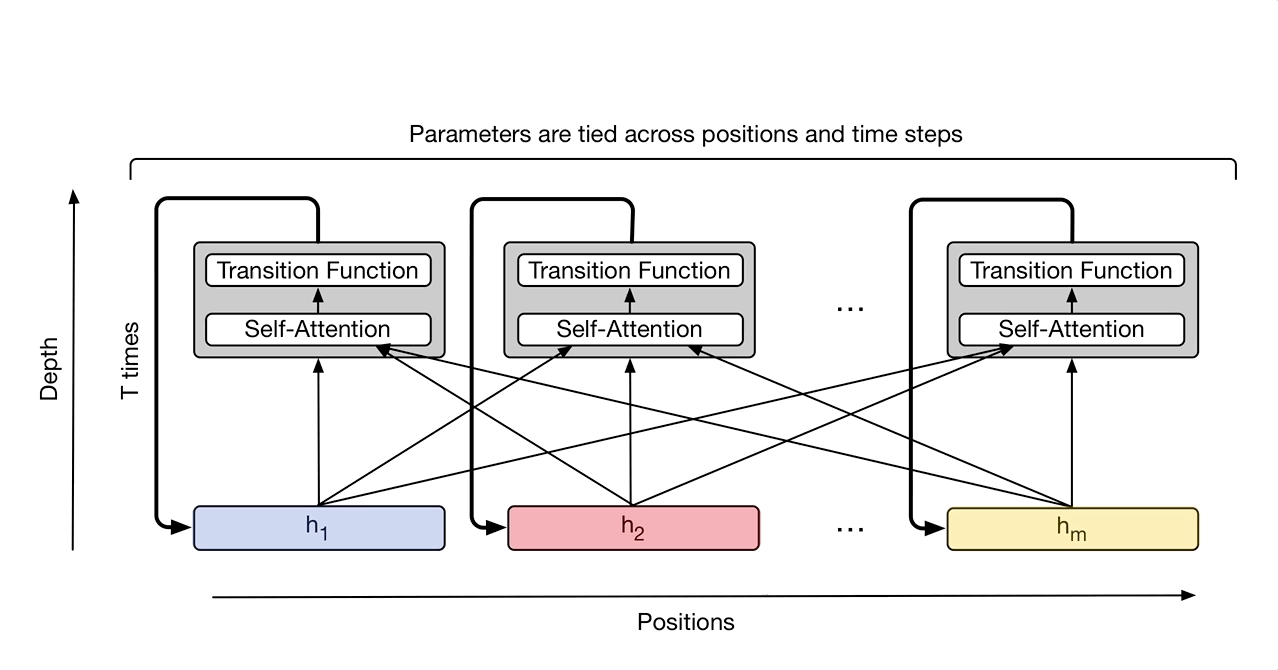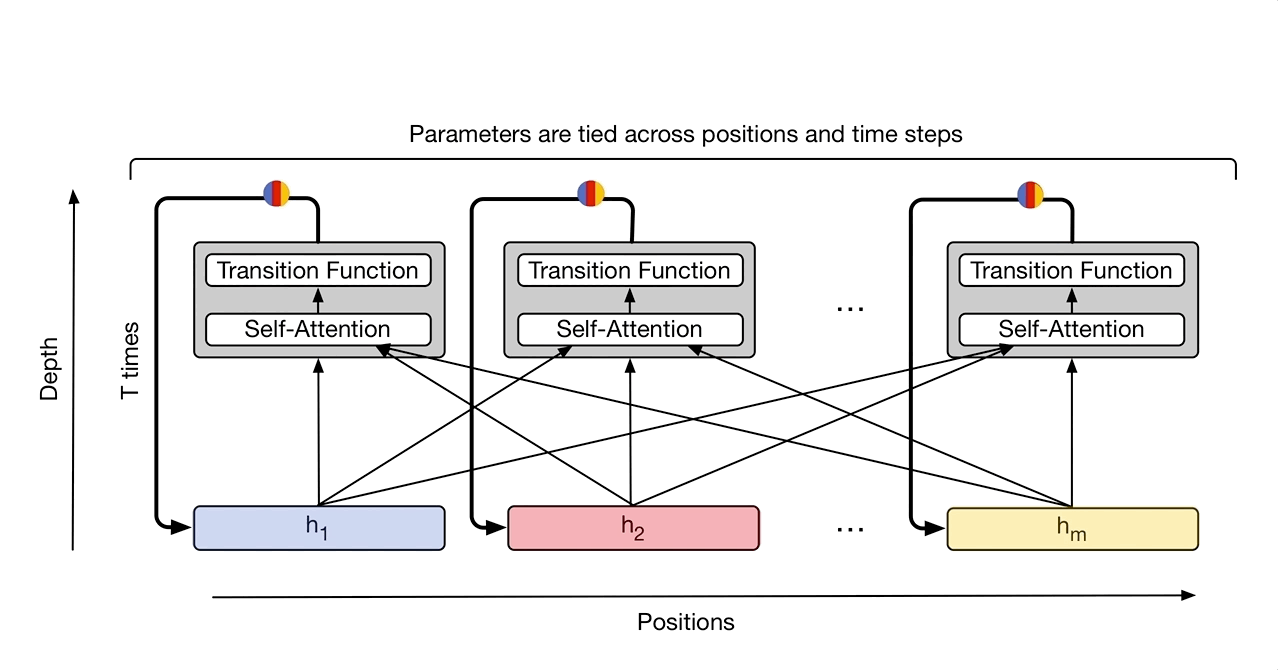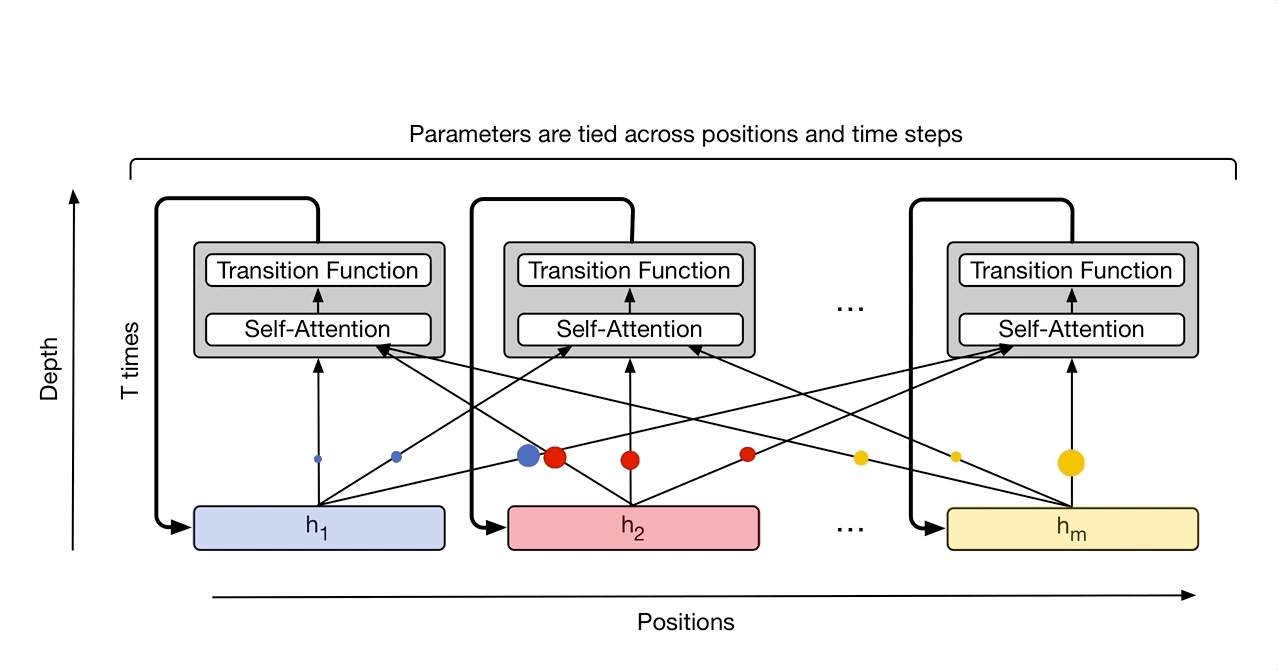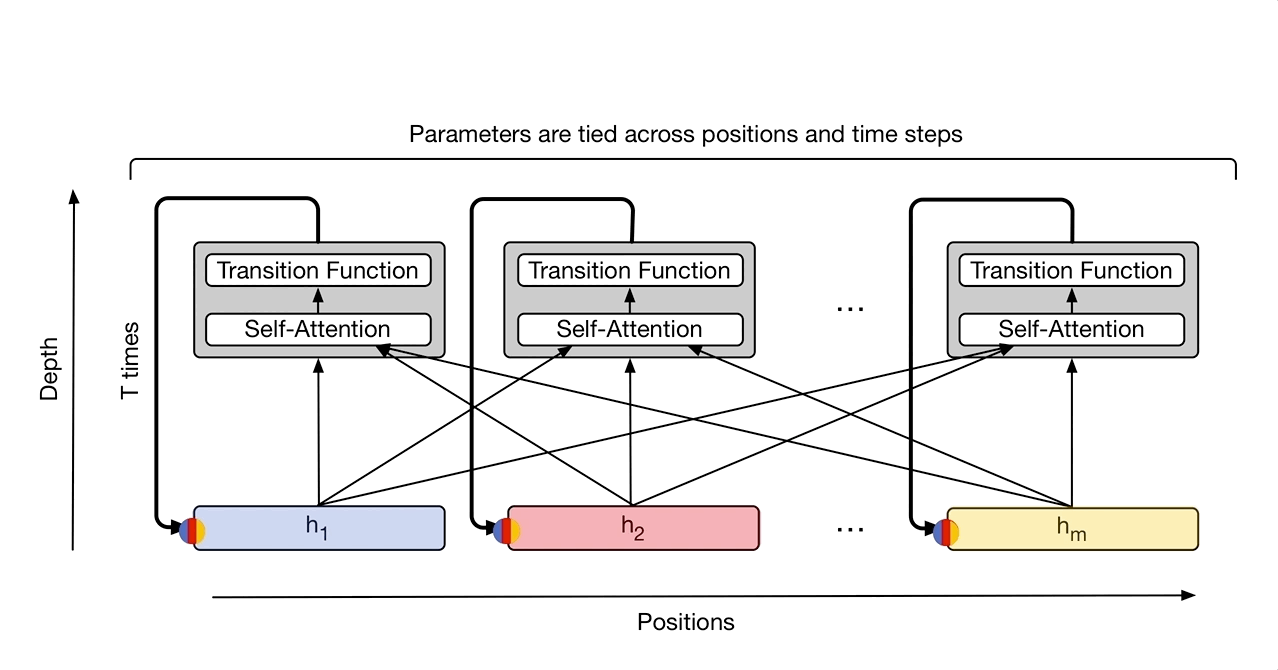
In “Universal Transformers” we extend the standard Transformer to be computationally universal (Turing complete) using a novel, efficient flavor of parallel-in-time recurrence which yields stronger results across a wider range of tasks. We built on the parallel structure of the Transformer to retain its fast training speed, but we replaced the Transformer’s fixed stack of different transformation functions with several applications of a single, parallel-in-time recurrent transformation function (i.e. the same learned transformation function is applied to all symbols in parallel over multiple processing steps, where the output of each step feeds into the next). Crucially, where an RNN processes a sequence symbol-by-symbol (left to right), the Universal Transformer processes all symbols at the same time (like the Transformer), but then refines its interpretation of every symbol in parallel over a variable number of recurrent processing steps using self-attention. This parallel-in-time recurrence mechanism is both faster than the serial recurrence used in RNNs, and also makes the Universal Transformer more powerful than the standard feedforward Transformer.
The Universal Transformer repeatedly refines a series of vector representations (shown as h1 to hm) for each position of the sequence in parallel, by combining information from different positions using self-attention and applying a recurrent transition function. Arrows denote dependencies between operations.
At each step, information is communicated from each symbol (e.g. word in the sentence) to all other symbols using self-attention, just like in the original Transformer. However, now the number of times this transformation is applied to each symbol (i.e. the number of recurrent steps) can either be manually set ahead of time (e.g. to some fixed number or to the input length), or it can be decided dynamically by the Universal Transformer itself. To achieve the latter, we added an adaptive computation mechanism to each position which can allocate more processing steps to symbols that are more ambiguous or require more computations.
As an intuitive example of how this could be useful, consider the sentence “I arrived at the bank after crossing the river”. In this case, more context is required to infer the most likely meaning of the word “bank” compared to the less ambiguous meaning of “I” or “river”. When we encode this sentence using the standard Transformer, the same amount of computation is applied unconditionally to each word. However, the Universal Transformer’s adaptive mechanism allows the model to spend increased computation only on the more ambiguous words, e.g. to use more steps to integrate the additional contextual information needed to disambiguate the word “bank”, while spending potentially fewer steps on less ambiguous words.
At first it might seem restrictive to allow the Universal Transformer to only apply a single learned function repeatedly to process its input, especially when compared to the standard Transformer which learns to apply a fixed sequence of distinct functions. But learning how to apply a single function repeatedly means the number of applications (processing steps) can now be variable, and this is the crucial difference. Beyond allowing the Universal Transformer to apply more computation to more ambiguous symbols, as explained above, it further allows the model to scale the number of function applications with the overall size of the input (more steps for longer sequences), or to decide dynamically how often to apply the function to any given part of the input based on other characteristics learned during training. This makes the Universal Transformer more powerful in a theoretical sense, as it can effectively learn to apply different transformations to different parts of the input. This is something that the standard Transformer cannot do, as it consists of fixed stacks of learned Transformation blocks applied only once.
But while increased theoretical power is desirable, we also care about empirical performance. Our experiments confirm that Universal Transformers are indeed able to learn from examples how to copy and reverse strings and how to perform integer addition much better than a Transformer or an RNN (although not quite as well as Neural GPUs). Furthermore, on a diverse set of challenging language understanding tasks the Universal Transformer generalizes significantly better and achieves a new state of the art on the bAbI linguistic reasoning task and the challenging LAMBADA language modeling task. But perhaps of most interest is that the Universal Transformer also improves translation quality by 0.9 BLEU1 over a base Transformer with the same number of parameters, trained in the same way on the same training data. Putting things in perspective, this almost adds another 50% relative improvement on top of the previous 2.0 BLEU improvement that the original Transformer showed over earlier models when it was released last year.
The Universal Transformer thus closes the gap between practical sequence models competitive on large-scale language understanding tasks such as machine translation, and computationally universal models such as the Neural Turing Machine or the Neural GPU, which can be trained using gradient descent to perform arbitrary algorithmic tasks. We are enthusiastic about recent developments on parallel-in-time sequence models, and in addition to adding computational capacity and recurrence in processing depth, we hope that further improvements to the basic Universal Transformer presented here will help us build learning algorithms that are both more powerful, more data efficient, and that generalize beyond the current state-of-the-art.
If you’d like to try this for yourself, the code used to train and evaluate Universal Transformers can be found here in the open-source Tensor2Tensor repository.
1 A translation quality benchmark widely used in the machine translation community, computed on the standard WMT newstest2014 English to German translation test data set.↩
Posted by Posted by Kenton Lee, Research Scientist and Slav Petrov, Principal Scientist, Language Team, Google AI
This week, New Orleans, LA hosted the North American Association of Computational Linguistics (NAACL) conference, a venue for the latest research on computational approaches to understanding natural language. Google once again had a strong presence, presenting our research on a diverse set of topics, including dialog, summarization, machine translation, and linguistic analysis. In addition to contributing publications, Googlers were also involved as committee members, workshop organizers, panelists and presented one of the conference keynotes. We also provided telepresence robots, which enabled researchers who couldn’t attend in person to present their work remotely at the Widening Natural Language Processing Workshop (WiNLP).
Googler Margaret Mitchell and a researcher using our telepresence robots to remotely present their work at the WiNLP workshop.
This year NAACL also introduced a new Test of Time Award recognizing influential papers published between 2002 and 2012. We are happy and honored to recognize that all three papers receiving the award (listed below with a shot summary) were co-authored by researchers who are now at Google (in blue):
BLEU: a Method for Automatic Evaluation of Machine Translation (2002) Kishore Papineni, Salim Roukos, Todd Ward, Wei-Jing Zhu Before the introduction of the BLEU metric, comparing Machine Translation (MT) models required expensive human evaluation. While human evaluation is still the gold standard, the strong correlation of BLEU with human judgment has permitted much faster experiment cycles. BLEU has been a reliable measure of progress, persisting through multiple paradigm shifts in MT.
Discriminative Training Methods for Hidden Markov Models: Theory and Experiments with Perceptron Algorithms (2002) Michael Collins The structured perceptron is a generalization of the classical perceptron to structured prediction problems, where the number of possible "labels" for each input is a very large set, and each label has rich internal structure. Canonical examples are speech recognition, machine translation, and syntactic parsing. The structured perceptron was one of the first algorithms proposed for structured prediction, and has been shown to be effective in spite of its simplicity.
Thumbs up?: Sentiment Classification using Machine Learning Techniques (2002) Bo Pang, Lillian Lee, Shivakumar Vaithyanathan This paper is amongst the first works in sentiment analysis and helped define the subfield of sentiment and opinion analysis and review mining. The paper introduced a new way to look at document classification, developed the first solutions to it using supervised machine learning methods, and discussed insights and challenges. This paper also had significant data impact -- the movie review dataset has supported much of the early work in this area and is still one of the commonly used benchmark evaluation datasets.
If you attended NAACL 2018, we hope that you stopped by the booth to check out some demos, meet our researchers and discuss projects and opportunities at Google that go into solving interesting problems for billions of people. You can learn more about Google research presented at NAACL 2018 below (Googlers highlighted in blue), and visit the Google AI Language Team page.
Posted by Yinfei Yang, Software Engineer and Chris Tar, Engineering Manager, Google AI
The recent rapid progress of neural network-based natural language understanding research, especially on learning semantic text representations, can enable truly novel products such as Smart Compose and Talk to Books. It can also help improve performance on a variety of natural language tasks which have limited amounts of training data, such as building strong text classifiers from as few as 100 labeled examples.
Below, we discuss two papers reporting recent progress on semantic representation research at Google, as well as two new models available for download on TensorFlow Hub that we hope developers will use to build new and exciting applications.
Semantic Textual Similarity In “Learning Semantic Textual Similarity from Conversations”, we introduce a new way to learn sentence representations for semantic textual similarity. The intuition is that sentences are semantically similar if they have a similar distribution of responses. For example, “How old are you?” and “What is your age?” are both questions about age, which can be answered by similar responses such as “I am 20 years old”. In contrast, while “How are you?” and “How old are you?” contain almost identical words, they have very different meanings and lead to different responses.
Sentences are semantically similar if they can be answered by the same responses. Otherwise, they are semantically different.
In this work, we aim to learn semantic similarity by way of a response classification task: given a conversational input, we wish to classify the correct response from a batch of randomly selected responses. But, the ultimate goal is to learn a model that can return encodings representing a variety of natural language relationships, including similarity and relatedness. By adding another prediction task (In this case, the SNLIentailment dataset) and forcing both through shared encoding layers, we get even better performance on similarity measures such as the STSBenchmark (a sentence similarity benchmark) and CQA task B (a question/question similarity task). This is because logical entailment is quite different from simple equivalence and provides more signal for learning complex semantic representations.
For a given input, classification is considered a ranking problem against potential candidates.
Universal Sentence Encoder In “Universal Sentence Encoder”, we introduce a model that extends the multitask training described above by adding more tasks, jointly training them with a skip-thought-like model that predicts sentences surrounding a given selection of text. However, instead of the encoder-decoder architecture in the original skip-thought model, we make use of an encode-only architecture by way of a shared encoder to drive the prediction tasks. In this way, training time is greatly reduced while preserving the performance on a variety of transfer tasks including sentiment and semantic similarity classification. The aim is to provide a single encoder that can support as wide a variety of applications as possible, including paraphrase detection, relatedness, clustering and custom text classification.
Pairwise semantic similarity comparison via outputs from TensorFlow Hub Universal Sentence Encoder.
As described in our paper, one version of the Universal Sentence Encoder model uses a deep average network (DAN) encoder, while a second version uses a more complicated self attended network architecture, Transformer.
Multi-task training as described in “Universal Sentence Encoder”. A variety of tasks and task structures are joined by shared encoder layers/parameters (grey boxes).
With the more complicated architecture, the model performs better than the simpler DAN model on a variety of sentiment and similarity classification tasks, and for short sentences is only moderately slower. However, compute time for the model using Transformer increases noticeably as sentence length increases, whereas the compute time for the DAN model stays nearly constant as sentence length is increased.
New Models In addition to the Universal Sentence Encoder model described above, we are also sharing two new models on TensorFlow Hub: the Universal Sentence Encoder - Large and Universal Sentence Encoder - Lite. These are pretrained Tensorflow models that return a semantic encoding for variable-length text inputs. The encodings can be used for semantic similarity measurement, relatedness, classification, or clustering of natural language text.
The Large model is trained with the Transformer encoder described in our second paper. It targets scenarios requiring high precision semantic representations and the best model performance at the cost of speed & size.
The Lite model is trained on a Sentence Piece vocabulary instead of words in order to significantly reduce the vocabulary size, which is a major contributor of model size. It targets scenarios where resources like memory and CPU are limited, such as on-device or browser based implementations.
We're excited to share this research, and these models, with the community. We believe that what we're showing here is just the beginning, and that there remain important research problems to be addressed, such as extending the techniques to more languages (the models discussed above currently support English). We also hope to further develop this technology so it can understand text at the paragraph or even document level. In achieving these tasks, it may be possible to make an encoder that is truly “universal”.
Acknowledgements Daniel Cer, Mario Guajardo-Cespedes, Sheng-Yi Kong, Noah Constant for training the models, Nan Hua, Nicole Limtiaco, Rhomni St. John for transferring tasks, Steve Yuan, Yunhsuan Sung, Brian Strope, Ray Kurzweil for discussion of the model architecture. Special thanks to Sheng-Yi Kong and Noah Constant for training the Lite model.
Posted by Yonghui Wu, Principal Engineer, Google Brain Team
Last week at Google I/O, we introduced Smart Compose, a new feature in Gmail that uses machine learning to interactively offer sentence completion suggestions as you type, allowing you to draft emails faster. Building upon technology developed for Smart Reply, Smart Compose offers a new way to help you compose messages — whether you are responding to an incoming email or drafting a new one from scratch.
In developing Smart Compose, there were a number of key challenges to face, including:
Latency: Since Smart Compose provides predictions on a per-keystroke basis, it must respond ideally within 100ms for the user not to notice any delays. Balancing model complexity and inference speed was a critical issue.
Scale: Gmail is used by more than 1.4 billion diverse users. In order to provide auto completions that are useful for all Gmail users, the model has to have enough modeling capacity so that it is able to make tailored suggestions in subtly different contexts.
Fairness and Privacy: In developing Smart Compose, we needed to address sources of potential bias in the training process, and had to adhere to the same rigorous user privacy standards as Smart Reply, making sure that our models never expose user’s private information. Furthermore, researchers had no access to emails, which meant they had to develop and train a machine learning system to work on a dataset that they themselves cannot read.
Finding the Right Model Typical language generation models, such as ngram, neural bag-of-words (BoW) and RNN language (RNN-LM) models, learn to predict the next word conditioned on the prefix word sequence. In an email, however, the words a user has typed in the current email composing session is only one “signal” a model can use to predict the next word. In order to incorporate more context about what the user wants to say, our model is also conditioned on the email subject and the previous email body (if the user is replying to an incoming email).
One approach to include this additional context is to cast the problem as a sequence-to-sequence (seq2seq) machine translation task, where the source sequence is the concatenation of the subject and the previous email body (if there is one), and the target sequence is the current email the user is composing. While this approach worked well in terms of prediction quality, it failed to meet our strict latency constraints by orders of magnitude.
To improve on this, we combined a BoW model with an RNN-LM, which is faster than the seq2seq models with only a slight sacrifice to model prediction quality. In this hybrid approach, we encode the subject and previous email by averaging the word embeddings in each field. We then join those averaged embeddings, and feed them to the target sequence RNN-LM at every decoding step, as the model diagram below shows.
Smart Compose RNN-LM model architecture. Subject and previous email message are encoded by averaging the word embeddings in each field. The averaged embeddings are then fed to the RNN-LM at each decoding step.
Accelerated Model Training & Serving Of course, once we decided on this modeling approach we still had to tune various model hyperparameters and train the models over billions of examples, all of which can be very time-intensive. To speed things up, we used a full TPUv2 Pod to perform experiments. In doing so, we’re able to train a model to convergence in less than a day.
Even after training our faster hybrid model, our initial version of Smart Compose running on a standard CPU had an average serving latency of hundreds of milliseconds, which is still unacceptable for a feature that is trying to save users' time. Fortunately, TPUs can also be used at inference time to greatly speed up the user experience. By offloading the bulk of the computation onto TPUs, we improved the average latency to tens of milliseconds while also greatly increasing the number of requests that can be served by a single machine.
Fairness and Privacy Fairness in machine learning is very important, as language understanding models can reflect human cognitive biases resulting in unwanted word associations and sentence completions. As Caliskan et al. point out in their recent paper “Semantics derived automatically from language corpora contain human-like biases”, these associations are deeply entangled in natural language data, which presents a considerable challenge to building any language model. We are actively researching ways to continue to reduce potential biases in our training procedures. Also, since Smart Compose is trained on billions of phrases and sentences, similar to the way spam machine learning models are trained, we have done extensive testing to make sure that only common phrases used by multiple users are memorized by our model, using findings from this paper.
Future work We are constantly working on improving the suggestion quality of the language generation model by following state-of-the-art architectures (e.g., Transformer,RNMT+, etc.) and experimenting with most recent and advanced training techniques. We will deploy those more advanced models to production once our strict latency constraints can be met. We are also working on incorporating personal language models, designed to more accurately emulate an individual’s style of writing into our system.
Acknowledgements Smart Compose language generation model was developed by Benjamin Lee, Mia Chen, Gagan Bansal, Justin Lu, Jackie Tsay, Kaushik Roy, Tobias Bosch, Yinan Wang, Matthew Dierker, Katherine Evans, Thomas Jablin, Dehao Chen, Vinu Rajashekhar, Akshay Agrawal, Yuan Cao, Shuyuan Zhang, Xiaobing Liu, Noam Shazeer, Andrew Dai, Zhifeng Chen, Rami Al-Rfou, DK Choe, Yunhsuan Sung, Brian Strope, Timothy Sohn, Yonghui Wu, and many others.
Posted by Yaniv Leviathan, Principal Engineer and Yossi Matias, Vice President, Engineering, Google
A long-standing goal of human-computer interaction has been to enable people to have a natural conversation with computers, as they would with each other. In recent years, we have witnessed a revolution in the ability of computers to understand and to generate natural speech, especially with the application of deep neural networks (e.g., Google voice search, WaveNet). Still, even with today’s state of the art systems, it is often frustrating having to talk to stilted computerized voices that don't understand natural language. In particular, automated phone systems are still struggling to recognize simple words and commands. They don’t engage in a conversation flow and force the caller to adjust to the system instead of the system adjusting to the caller.
Today we announce Google Duplex, a new technology for conducting natural conversations to carry out “real world” tasks over the phone. The technology is directed towards completing specific tasks, such as scheduling certain types of appointments. For such tasks, the system makes the conversational experience as natural as possible, allowing people to speak normally, like they would to another person, without having to adapt to a machine.
One of the key research insights was to constrain Duplex to closed domains, which are narrow enough to explore extensively. Duplex can only carry out natural conversations after being deeply trained in such domains. It cannot carry out general conversations.
Here are examples of Duplex making phone calls (using different voices):
Duplex scheduling a hair salon appointment:
Duplex calling a restaurant:
While sounding natural, these and other examples are conversations between a fully automatic computer system and real businesses.
The Google Duplex technology is built to sound natural, to make the conversation experience comfortable. It’s important to us that users and businesses have a good experience with this service, and transparency is a key part of that. We want to be clear about the intent of the call so businesses understand the context. We’ll be experimenting with the right approach over the coming months.
Conducting Natural Conversations There are several challenges in conducting natural conversations: natural language is hard to understand, natural behavior is tricky to model, latency expectations require fast processing, and generating natural sounding speech, with the appropriate intonations, is difficult.
When people talk to each other, they use more complex sentences than when talking to computers. They often correct themselves mid-sentence, are more verbose than necessary, or omit words and rely on context instead; they also express a wide range of intents, sometimes in the same sentence, e.g., “So umm Tuesday through Thursday we are open 11 to 2, and then reopen 4 to 9, and then Friday, Saturday, Sunday we... or Friday, Saturday we're open 11 to 9 and then Sunday we're open 1 to 9.”
Example of complex statement:
In natural spontaneous speech people talk faster and less clearly than they do when they speak to a machine, so speech recognition is harder and we see higher word error rates. The problem is aggravated during phone calls, which often have loud background noises and sound quality issues.
In longer conversations, the same sentence can have very different meanings depending on context. For example, when booking reservations “Ok for 4” can mean the time of the reservation or the number of people. Often the relevant context might be several sentences back, a problem that gets compounded by the increased word error rate in phone calls.
Deciding what to say is a function of both the task and the state of the conversation. In addition, there are some common practices in natural conversations — implicit protocols that include elaborations (“for next Friday” “for when?” “for Friday next week, the 18th.”), syncs (“can you hear me?”), interruptions (“the number is 212-” “sorry can you start over?”), and pauses (“can you hold? [pause] thank you!” different meaning for a pause of 1 second vs 2 minutes).
Enter Duplex Google Duplex’s conversations sound natural thanks to advances in understanding, interacting, timing, and speaking.
At the core of Duplex is a recurrent neural network (RNN) designed to cope with these challenges, built using TensorFlow Extended (TFX). To obtain its high precision, we trained Duplex’s RNN on a corpus of anonymized phone conversation data. The network uses the output of Google’s automatic speech recognition (ASR) technology, as well as features from the audio, the history of the conversation, the parameters of the conversation (e.g. the desired service for an appointment, or the current time of day) and more. We trained our understanding model separately for each task, but leveraged the shared corpus across tasks. Finally, we used hyperparameter optimization from TFX to further improve the model.
Incoming sound is processed through an ASR system. This produces text that is analyzed with context data and other inputs to produce a response text that is read aloud through the TTS system.
Duplex handling interruptions:
Duplex elaborating:
Duplex responding to a sync:
Sounding Natural We use a combination of a concatenative text to speech (TTS) engine and a synthesis TTS engine (using Tacotron and WaveNet) to control intonation depending on the circumstance.
The system also sounds more natural thanks to the incorporation of speech disfluencies (e.g. “hmm”s and “uh”s). These are added when combining widely differing sound units in the concatenative TTS or adding synthetic waits, which allows the system to signal in a natural way that it is still processing. (This is what people often do when they are gathering their thoughts.) In user studies, we found that conversations using these disfluencies sound more familiar and natural.
Also, it’s important for latency to match people’s expectations. For example, after people say something simple, e.g., “hello?”, they expect an instant response, and are more sensitive to latency. When we detect that low latency is required, we use faster, low-confidence models (e.g. speech recognition or endpointing). In extreme cases, we don’t even wait for our RNN, and instead use faster approximations (usually coupled with more hesitant responses, as a person would do if they didn’t fully understand their counterpart). This allows us to have less than 100ms of response latency in these situations. Interestingly, in some situations, we found it was actually helpful to introduce more latency to make the conversation feel more natural — for example, when replying to a really complex sentence.
System Operation The Google Duplex system is capable of carrying out sophisticated conversations and it completes the majority of its tasks fully autonomously, without human involvement. The system has a self-monitoring capability, which allows it to recognize the tasks it cannot complete autonomously (e.g., scheduling an unusually complex appointment). In these cases, it signals to a human operator, who can complete the task.
To train the system in a new domain, we use real-time supervised training. This is comparable to the training practices of many disciplines, where an instructor supervises a student as they are doing their job, providing guidance as needed, and making sure that the task is performed at the instructor’s level of quality. In the Duplex system, experienced operators act as the instructors. By monitoring the system as it makes phone calls in a new domain, they can affect the behavior of the system in real time as needed. This continues until the system performs at the desired quality level, at which point the supervision stops and the system can make calls autonomously.
Benefits for Businesses and Users Businesses that rely on appointment bookings supported by Duplex, and are not yet powered by online systems, can benefit from Duplex by allowing customers to book through the Google Assistant without having to change any day-to-day practices or train employees. Using Duplex could also reduce no-shows to appointments by reminding customers about their upcoming appointments in a way that allows easy cancellation or rescheduling.
Duplex calling a restaurant:
In another example, customers often call businesses to inquire about information that is not available online such as hours of operation during a holiday. Duplex can call the business to inquire about open hours and make the information available online with Google, reducing the number of such calls businesses receive, while at the same time, making the information more accessible to everyone. Businesses can operate as they always have, there’s no learning curve or changes to make to benefit from this technology.
Duplex asking for holiday hours:
For users, Google Duplex is making supported tasks easier. Instead of making a phone call, the user simply interacts with the Google Assistant, and the call happens completely in the background without any user involvement.
A user asks the Google Assistant for an appointment, which the Assistant then schedules by having Duplex call the business.
Another benefit for users is that Duplex enables delegated communication with service providers in an asynchronous way, e.g., requesting reservations during off-hours, or with limited connectivity. It can also help address accessibility and language barriers, e.g., allowing hearing-impaired users, or users who don’t speak the local language, to carry out tasks over the phone.
This summer, we’ll start testing the Duplex technology within the Google Assistant, to help users make restaurant reservations, schedule hair salon appointments, and get holiday hours over the phone.
Yaniv Leviathan, Google Duplex lead, and Matan Kalman, engineering manager on the project, enjoying a meal booked through a call from Duplex.
Duplex calling to book the above meal:
Allowing people to interact with technology as naturally as they interact with each other has been a long standing promise. Google Duplex takes a step in this direction, making interaction with technology via natural conversation a reality in specific scenarios. We hope that these technology advances will ultimately contribute to a meaningful improvement in people’s experience in day-to-day interactions with computers.