Mobile devices offer a myriad of functionalities that can assist in everyday activities. However, many of these functionalities are not easily discoverable or accessible to users, forcing users to look up how to perform a specific task -- how to turn on the traffic mode in Maps or change notification settings in YouTube, for example. While searching the web for detailed instructions for these questions is an option, it is still up to the user to follow these instructions step-by-step and navigate UI details through a small touchscreen, which can be tedious and time consuming, and results in reduced accessibility. What if one could design a computational agent to turn these language instructions into actions and automatically execute them on the user’s behalf?
In “Mapping Natural Language Instructions to Mobile UI Action Sequences”, published at ACL 2020, we present the first step towards addressing the problem of automatic action sequence mapping, creating three new datasets used to train deep learning models that ground natural language instructions to executable mobile UI actions. This work lays the technical foundation for task automation on mobile devices that would alleviate the need to maneuver through UI details, which may be especially valuable for users who are visually or situationally impaired. We have also open-sourced our model code and data pipelines through our GitHub repository, in order to spur further developments among the research community.
Constructing Language Grounding Models
People often provide one another with instructions in order to coordinate joint efforts and accomplish tasks involving complex sequences of actions, for example, following a recipe to bake a cake, or having a friend walk you through setting up a home network. Building computational agents able to help with similar interactions is an important goal that requires true language grounding in the environments in which the actions take place.
The learning task addressed here is to predict a sequence of actions for a mobile platform given a set of instructions, a sequence of screens produced as the system transitions from one screen to another, as well as the set of interactive elements on those screens. Training such a model end-to-end would require paired language-action data, which is difficult to acquire at a large scale.
Instead, we deconstruct the problem into two sequential steps: an action phrase-extraction step and a grounding step.
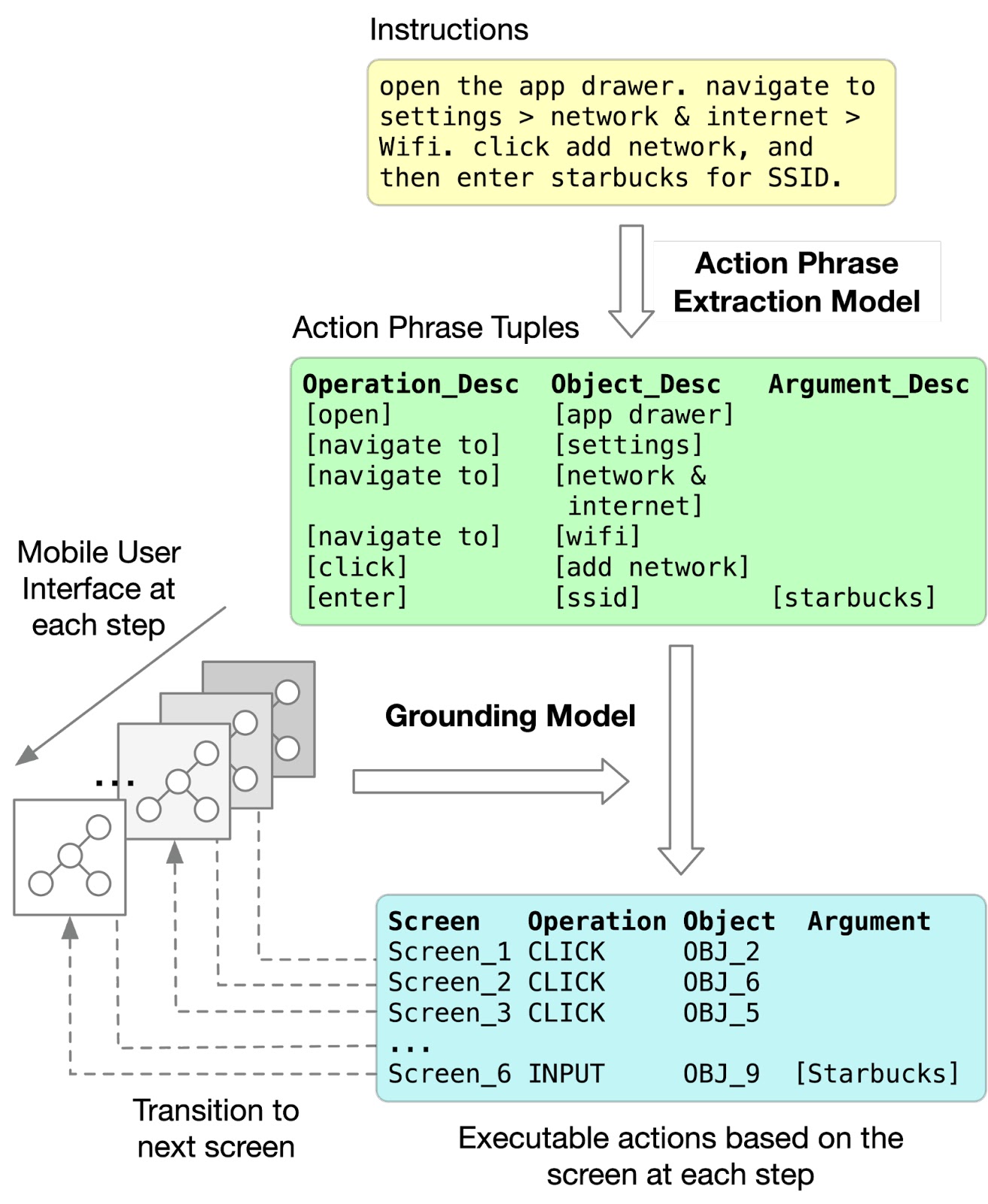 |
| The workflow of grounding language instructions to executable actions. |
 |
| The action phrase extraction model takes a word sequence of a natural language instruction and outputs a sequence of spans (denoted in red boxes) that indicate the phrases describing the operation, the object and the argument of each action in the task. |
 |
| The grounding model takes the extracted spans as input and grounds them to executable actions, including the object an action is applied to, given the UI screen at each step during execution. |
To investigate the feasibility of this task and the effectiveness of our approach, we construct three new datasets to train and evaluate our model. The first dataset includes 187 multi-step English instructions for operating Pixel phones along their corresponding action-screen sequences and enables assessment of full task performance on naturally occurring instructions, which is used for testing end-to-end grounding quality. For action phrase extraction training and evaluation, we obtain English “how-to” instructions that can be found abundantly from the web and annotate phrases that describe each action. To train the grounding model, we synthetically generate 295K single-step commands to UI actions, covering 178K different UI objects across 25K mobile UI screens from a public android UI corpus.
A Transformer with area attention obtains 85.56% accuracy for predicting span sequences that completely match the ground truth. The phrase extractor and grounding model together obtain 89.21% partial and 70.59% complete accuracy for matching ground-truth action sequences on the more challenging task of mapping language instructions to executable actions end-to-end. We also evaluated alternative methods and representations of UI objects, such as using a graph convolutional network (GCN) or a feedforward network, and found those that can represent an object contextually in the screen lead to better grounding accuracy. The new datasets, models and results provide an important first step on the challenging problem of grounding natural language instructions to mobile UI actions.
Conclusion
This research, and language grounding in general, is an important step for translating multi-stage instructions into actions on a graphical user interface. Successful application of task automation to the UI domain has the potential to significantly improve accessibility, where language interfaces might help individuals who are visually impaired perform tasks with interfaces that are predicated on sight. This also matters for situational impairment when one cannot access a device easily while encumbered by tasks at hand.
By deconstructing the problem into action phrase extraction and language grounding, progress on either can improve full task performance and it alleviates the need to have language-action paired datasets, which are difficult to collect at scale. For example, action span extraction is related to both semantic role labeling and extraction of multiple facts from text and could benefit from innovations in span identification and multitask learning. Reinforcement learning that has been applied in previous grounding work may help improve out-of-sample prediction for grounding in UIs and improve direct grounding from hidden state representations. Although our datasets were based on Android UIs, our approach can be applied generally to instruction grounding on other user interface platforms. Lastly, our work provides a technical foundation for investigating user experiences in language-based human computer interaction.
Acknowledgements
Many thanks to my collaborators on this work at Google Research. Xin Zhou and Jiacong He contributed substantially to the data pipelines and the creation of the datasets. Yuan Zhang and Jason Baldridge provided much valuable advice for the project and contributed to the presentation of the work. Gang Li provided generous help for creating open-source datasets. Many thanks to Ashwin Kakarla, Muqthar Mohammad and Mohd Majeed for their help with the annotations.
















































{kind=link}