A guest post by Neurons Lab
Please note that the information, uses, and applications expressed in the below post are solely those of our guest author, Neurons Lab, and not necessarily those of Google.
How the idea emerged
With the advancement of technology, drones have become not only smaller, but also have more compute. There are many examples of iPhone-sized quadcopters in the consumer drone market and the computing power to do live tracking while recording 4K video. However, the most important element has not changed much - the controller. It is still bulky and not intuitive for beginners to use. There is a smartphone with on-display control as an option; however, the control principle is still the same.
That is how the idea for this project emerged: a more personalised approach to control the drone using gestures. ML Engineer Nikita Kiselov (me) together with consultation from my colleagues at Neurons Lab undertook this project.
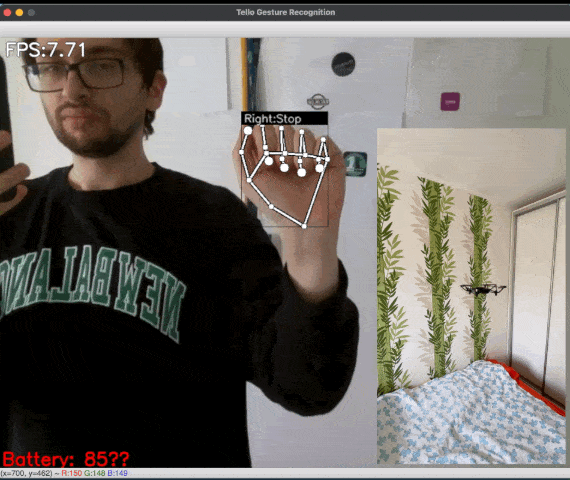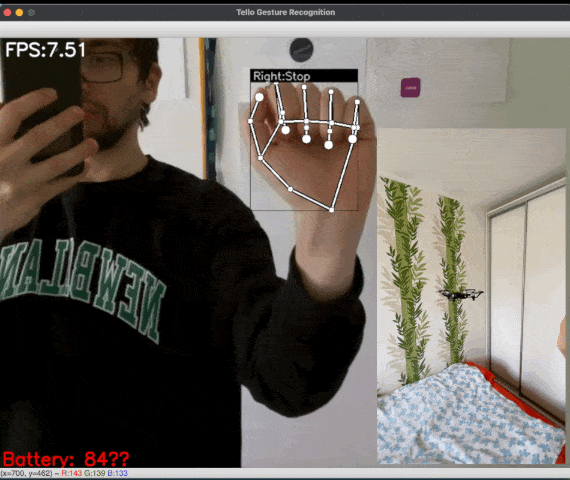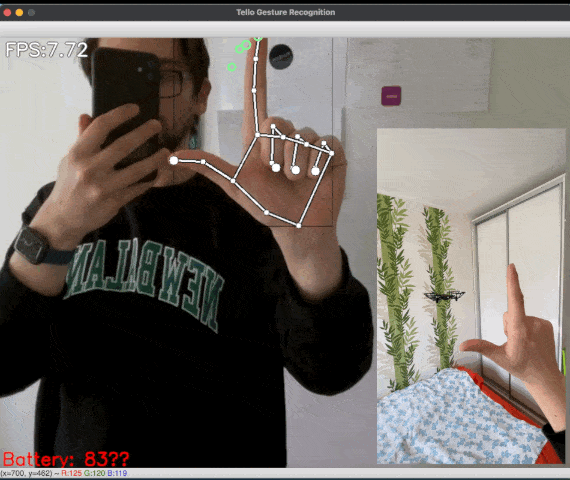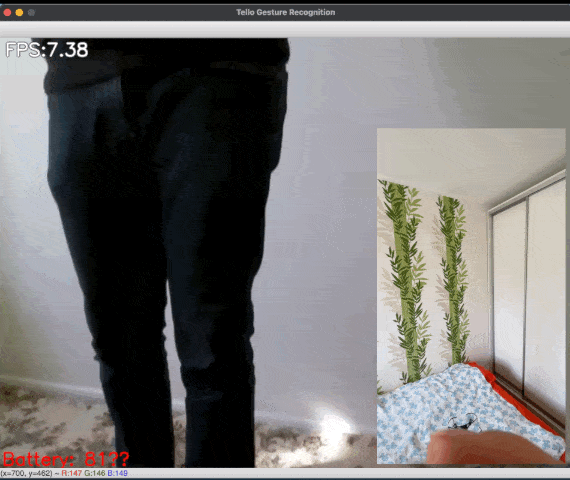
Figure 1: [GIF] Demonstration of drone flight control via gestures using MediaPipe Hands
Why use gesture recognition?
Gestures are the most natural way for people to express information in a non-verbal way. Gesture control is an entire topic in computer science that aims to interpret human gestures using algorithms. Users can simply control devices or interact without physically touching them. Nowadays, such types of control can be found from smart TV to surgery robots, and UAVs are not the exception.
Although gesture control for drones have not been widely explored lately, the approach has some advantages:
- No additional equipment needed.
- More human-friendly controls.
- All you need is a camera that is already on all drones.
With all these features, such a control method has many applications.
Flying action camera. In extreme sports, drones are a trendy video recording tool. However, they tend to have a very cumbersome control panel. The ability to use basic gestures to control the drone (while in action) without reaching for the remote control would make it easier to use the drone as a selfie camera. And the ability to customise gestures would completely cover all the necessary actions.
This type of control as an alternative would be helpful in an industrial environment like, for example, construction conditions when there may be several drone operators (gesture can be used as a stop-signal in case of losing primary source of control).
The Emergencies and Rescue Services could use this system for mini-drones indoors or in hard-to-reach places where one of the hands is busy. Together with the obstacle avoidance system, this would make the drone fully autonomous, but still manageable when needed without additional equipment.
Another area of application is FPV (first-person view) drones. Here the camera on the headset could be used instead of one on the drone to recognise gestures. Because hand movement can be impressively precise, this type of control, together with hand position in space, can simplify the FPV drone control principles for new users.
However, all these applications need a reliable and fast (really fast) recognition system. Existing gesture recognition systems can be fundamentally divided into two main categories: first - where special physical devices are used, such as smart gloves or other on-body sensors; second - visual recognition using various types of cameras. Most of those solutions need additional hardware or rely on classical computer vision techniques. Hence, that is the fast solution, but it's pretty hard to add custom gestures or even motion ones. The answer we found is MediaPipe Hands that was used for this project.
Overall project structure
To create the proof of concept for the stated idea, a Ryze Tello quadcopter was used as a UAV. This drone has an open Python SDK, which greatly simplified the development of the program. However, it also has technical limitations that do not allow it to run gesture recognition on the drone itself (yet). For this purpose a regular PC or Mac was used. The video stream from the drone and commands to the drone are transmitted via regular WiFi, so no additional equipment was needed.
To make the program structure as plain as possible and add the opportunity for easily adding gestures, the program architecture is modular, with a control module and a gesture recognition module.
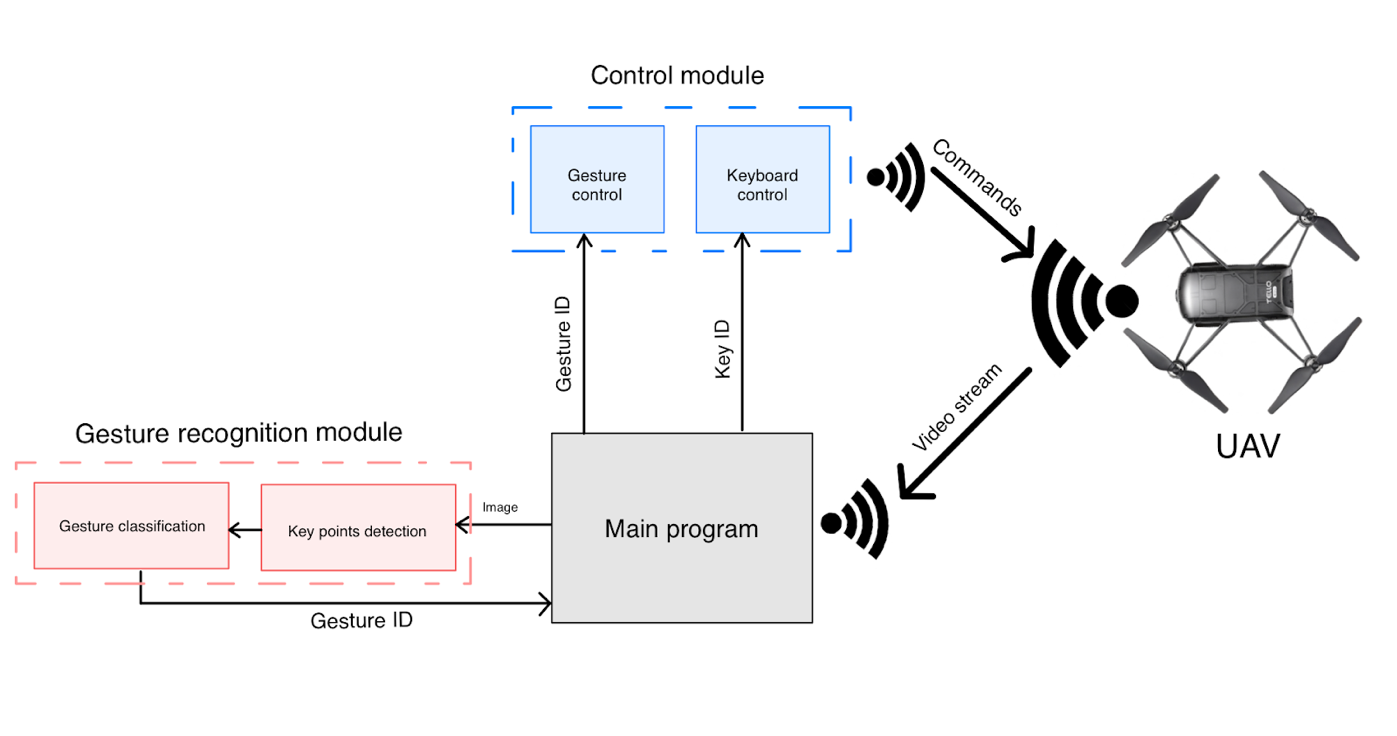
Figure 2: Scheme that shows overall project structure and how videostream data from the drone is processed
The application is divided into two main parts: gesture recognition and drone controller. Those are independent instances that can be easily modified. For example, to add new gestures or change the movement speed of the drone.
Video stream is passed to the main program, which is a simple script with module initialisation, connections, and typical for the hardware while-true cycle. Frame for the videostream is passed to the gesture recognition module. After getting the ID of the recognised gesture, it is passed to the control module, where the command is sent to the UAV. Alternatively, the user can control a drone from the keyboard in a more classical manner.
So, you can see that the gesture recognition module is divided into keypoint detection and gesture classifier. Exactly the bunch of the MediaPipe key point detector along with the custom gesture classification model distinguishes this gesture recognition system from most others.
Gesture recognition with MediaPipe
Utilizing MediaPipe Hands is a winning strategy not only in terms of speed, but also in flexibility. MediaPipe already has a simple gesture recognition calculator that can be inserted into the pipeline. However, we needed a more powerful solution with the ability to quickly change the structure and behaviour of the recognizer. To do so and classify gestures, the custom neural network was created with 4 Fully-Connected layers and 1 Softmax layer for classification.

Figure 3: Scheme that shows the structure of classification neural network
This simple structure gets a vector of 2D coordinates as an input and gives the ID of the classified gesture.
Instead of using cumbersome segmentation models with a more algorithmic recognition process, a simple neural network can easily handle such tasks. Recognising gestures by keypoints, which is a simple vector with 21 points` coordinates, takes much less data and time. What is more critical, new gestures can be easily added because model retraining tasks take much less time than the algorithmic approach.
To train the classification model, dataset with keypoints` normalised coordinates and ID of a gesture was used. The numerical characteristic of the dataset was that:
- 3 gestures with 300+ examples (basic gestures)
- 5 gestures with 40 -150 examples
All data is a vector of x, y coordinates that contain small tilt and different shapes of hand during data collection.
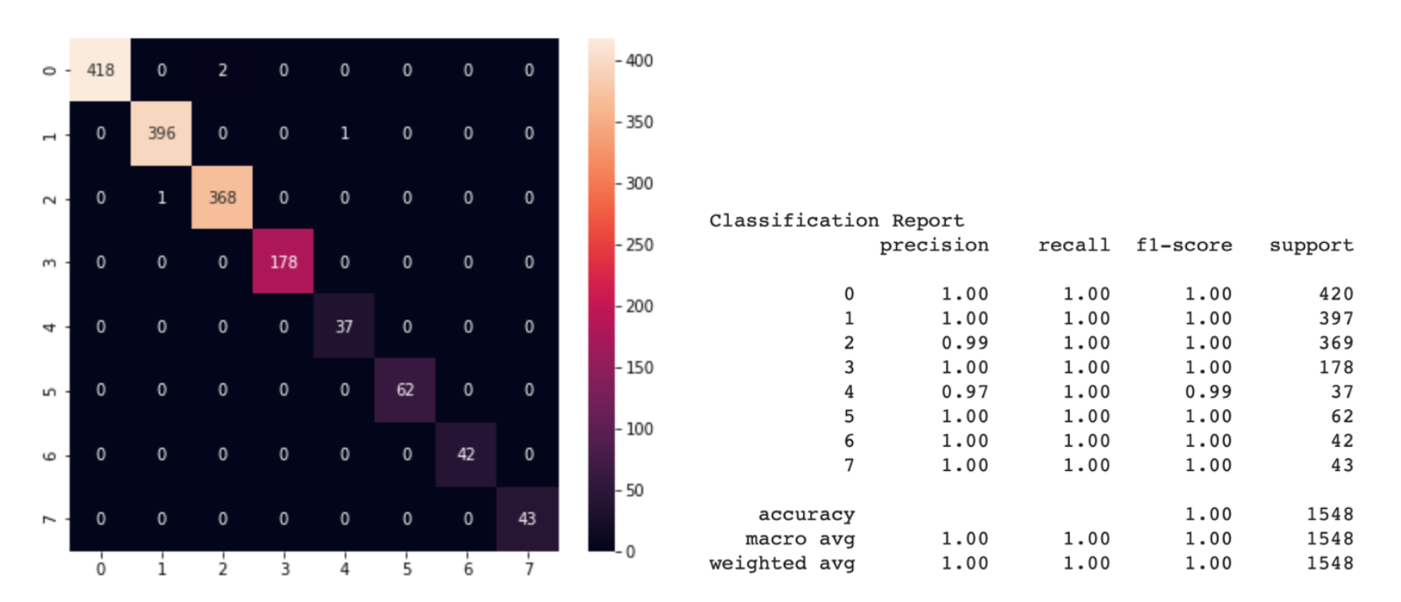
Figure 4: Confusion matrix and classification report for classification
We can see from the classification report that the precision of the model on the test dataset (this is 30% of all data) demonstrated almost error-free for most classes, precision > 97% for any class. Due to the simple structure of the model, excellent accuracy can be obtained with a small number of examples for training each class. After conducting several experiments, it turned out that we just needed the dataset with less than 100 new examples for good recognition of new gestures. What is more important, we don’t need to retrain the model for each motion in different illumination because MediaPipe takes over all the detection work.
![Figure 5: [GIF] Test that demonstrates how fast classification network can distinguish newly trained gestures using the information from MediaPipe hand detector](https://1.bp.blogspot.com/-P79noq5JrSM/YTqBpNUHNJI/AAAAAAAAKwI/Xp1WqAMKAJckPIX1CPUDfGOVn8evY_djQCLcBGAsYHQ/s0/figure%2B5.gif)
Figure 5: [GIF] Test that demonstrates how fast classification network can distinguish newly trained gestures using the information from MediaPipe hand detector
From gestures to movements
To control a drone, each gesture should represent a command for a drone. Well, the most excellent part about Tello is that it has a ready-made Python API to help us do that without explicitly controlling motors hardware. We just need to set each gesture ID to a command.
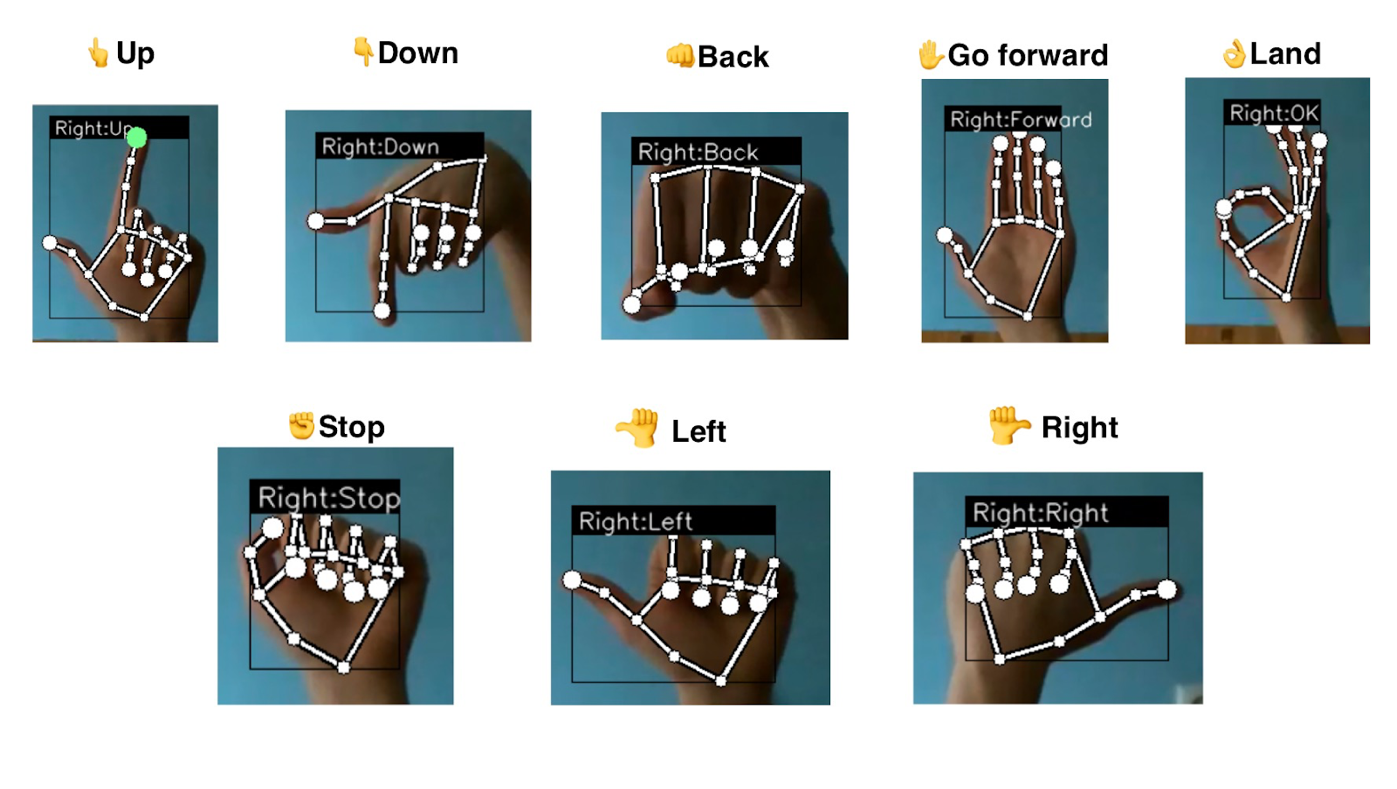
Figure 6: Command-gesture pairs representation
Each gesture sets the speed for one of the axes; that’s why the drone’s movement is smooth, without jitter. To remove unnecessary movements due to false detection, even with such a precise model, a special buffer was created, which is saving the last N gestures. This helps to remove glitches or inconsistent recognition.
The fundamental goal of this project is to demonstrate the superiority of the keypoint-based gesture recognition approach compared to classical methods. To demonstrate all the potential of this recognition model and its flexibility, there is an ability to create the dataset on the fly … on the drone`s flight! You can create your own combinations of gestures or rewrite an existing one without collecting massive datasets or manually setting a recognition algorithm. By pressing the button and ID key, the vector of detected points is instantly saved to the overall dataset. This new dataset can be used to retrain classification network to add new gestures for the detection. For now, there is a notebook that can be run on Google Colab or locally. Retraining the network-classifier takes about 1-2 minutes on a standard CPU instance. The new binary file of the model can be used instead of the old one. It is as simple as that. But for the future, there is a plan to do retraining right on the mobile device or even on the drone.
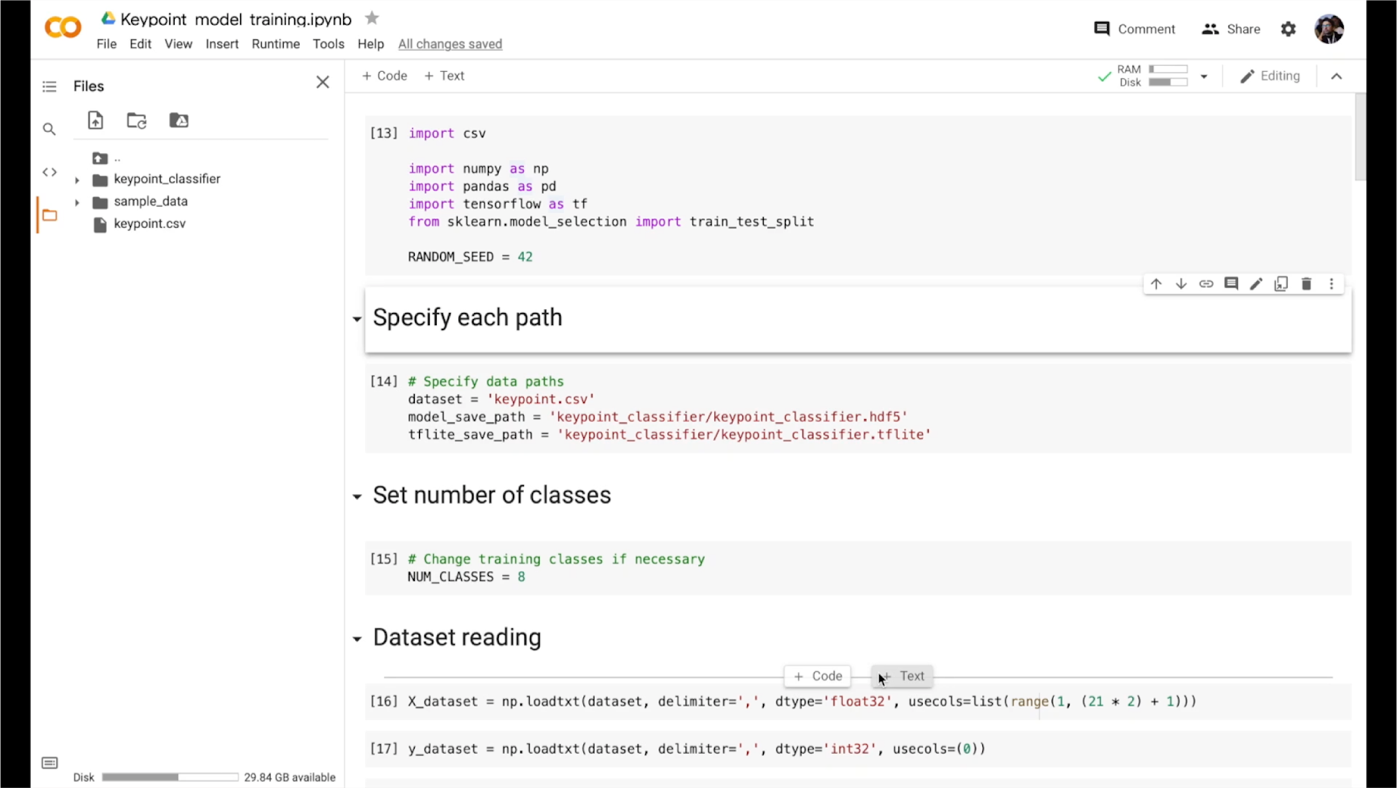
Figure 7: Notebook for model retraining in action
Summary
This project is created to make a push in the area of the gesture-controlled drones. The novelty of the approach lies in the ability to add new gestures or change old ones quickly. This is made possible thanks to MediaPipe Hands. It works incredibly fast, reliably, and ready out of the box, making gesture recognition very fast and flexible to changes. Our Neuron Lab`s team is excited about the demonstrated results and going to try other incredible solutions that MediaPipe provides.
We will also keep track of MediaPipe updates, especially about adding more flexibility in creating custom calculators for our own models and reducing barriers to entry when creating them. Since at the moment our classifier model is outside the graph, such improvements would make it possible to quickly implement a custom calculator with our model into reality.
Another highly anticipated feature is Flutter support (especially for iOS). In the original plans, the inference and visualisation were supposed to be on a smartphone with NPU\GPU utilisation, but at the moment support quality does not satisfy our requests. Flutter is a very powerful tool for rapid prototyping and concept checking. It allows us to throw and test an idea cross-platform without involving a dedicated mobile developer, so such support is highly demanded.
Nevertheless, the development of this demo project continues with available functionality, and there are already several plans for the future. Like using the MediaPipe Holistic for face recognition and subsequent authorisation. The drone will be able to authorise the operator and give permission for gesture control. It also opens the way to personalisation. Since the classifier network is straightforward, each user will be able to customise gestures for themselves (simply by using another version of the classifier model). Depending on the authorised user, one or another saved model will be applied. Also in the plans to add the usage of Z-axis. For example, tilt the palm of your hand to control the speed of movement or height more precisely. We encourage developers to innovate responsibly in this area, and to consider responsible AI practices such as testing for unfair biases and designing with safety and privacy in mind.
We highly believe that this project will motivate even small teams to do projects in the field of ML computer vision for the UAV, and MediaPipe will help to cope with the limitations and difficulties on their way (such as scalability, cross-platform support and GPU inference).
If you want to contribute, have ideas or comments about this project, please reach out to [email protected], or visit the GitHub page of the project.
This blog post is curated by Igor Kibalchich, ML Research Product Manager at Google AI.