Gemini 1.5 Pro Now Available in 180+ Countries; with Native Audio Understanding, System Instructions, JSON Mode and more
We are continuing to work on making Google AI Studio and the Gemini API the easiest way to build with the latest Gemini model.

In the fast-paced world of software development, Continuous Integration and Continuous Deployment (CI/CD) have become cornerstones, enabling teams to deliver high-quality software faster than ever. However, the rise of rapid innovation, increasing use of third-party libraries, and AI-generated code have accelerated vulnerabilities and risks. Therefore, addressing these issues early in the development lifecycle is essential so that teams can launch their products quickly and confidently.
The introduction of Checks privacy compliance CI/CD tooling feature represents a significant stride towards addressing these concerns, by reducing manual intervention and automating compliance and privacy standards as part of a release cycle.
In this post, we explore the meaning of CI/CD for compliance team members unfamiliar with this technology and how Checks can weave privacy and compliance protection practices into that pipeline.
Continuous Integration (CI) and Continuous Deployment (CD) are foundational practices in modern software development. They enable development teams to increase efficiency, improve quality, and accelerate delivery.
Continuous Integration (CI) automatically integrates code changes from multiple contributors into a software project. This practice enables teams to detect problems early by running automated tests on each change before it is merged into the main branch.
 |
Continuous Deployment (CD) takes automation further by automatically deploying all code changes to a testing or production environment after the build stage. This means that, in addition to automated testing, automated release processes ensure that new changes are accessible to users as quickly as possible.
The automation of CI/CD processes is typically called “pipelines.” CI/CD pipelines automate the steps software changes go through, from development to deployment. These steps include compiling code, running tests (unit tests, integration tests, etc.), security scans, and more. If all automated tests pass, the changes go live without human intervention in a specific environment, such as testing or production.
These pipelines are designed to catch issues as early as possible, embodying the practice known as “shifting left.” The benefits of “shifting left”, particularly when applied through CI/CD pipelines, include:
- Improved quality and security: Automated testing in CI/CD pipelines ensures that code is rigorously tested for functional and compliance issues before it reaches production. This early detection enables teams to address vulnerabilities and errors when they are generally easier and less costly to fix.
- Faster release cycles: By catching and addressing issues early, teams avoid the bottlenecks associated with late-stage discovery of problems. This efficiency reduces the time from development to deployment, enabling faster release cycles and more responsive delivery of features and fixes.
- Reduced costs: Detecting issues later in the development process can be significantly more expensive to resolve, especially if they're found after deployment. Early detection through CI/CD pipelines minimizes these costs by preventing complex rollbacks and the need for emergency fixes in production environments.
- Increased reliability and trust: Software that undergoes thorough testing before release is generally more reliable and secure. This reliability builds trust among users and stakeholders, crucial for maintaining a positive reputation and ensuring user satisfaction.
TChecks CI/CD tooling seamlessly integrates app compliance scanning into CI/CD pipelines via plugins for GitHub, Jenkins, and FastLane. You can also use Checks in any other CI/CD system that supports custom scripts, such as GitLab, TeamCity, Bitbucket, and more.
 |
When Checks scans an app, the binary undergoes dynamic and static analysis to understand your data collection and sharing practices, including app dependencies such as SDKs, permissions, and endpoints. This data is then tested against global regulatory requirements, store policies, your custom Checks policies, and your privacy policy to find potential issues and opportunities for improvement.
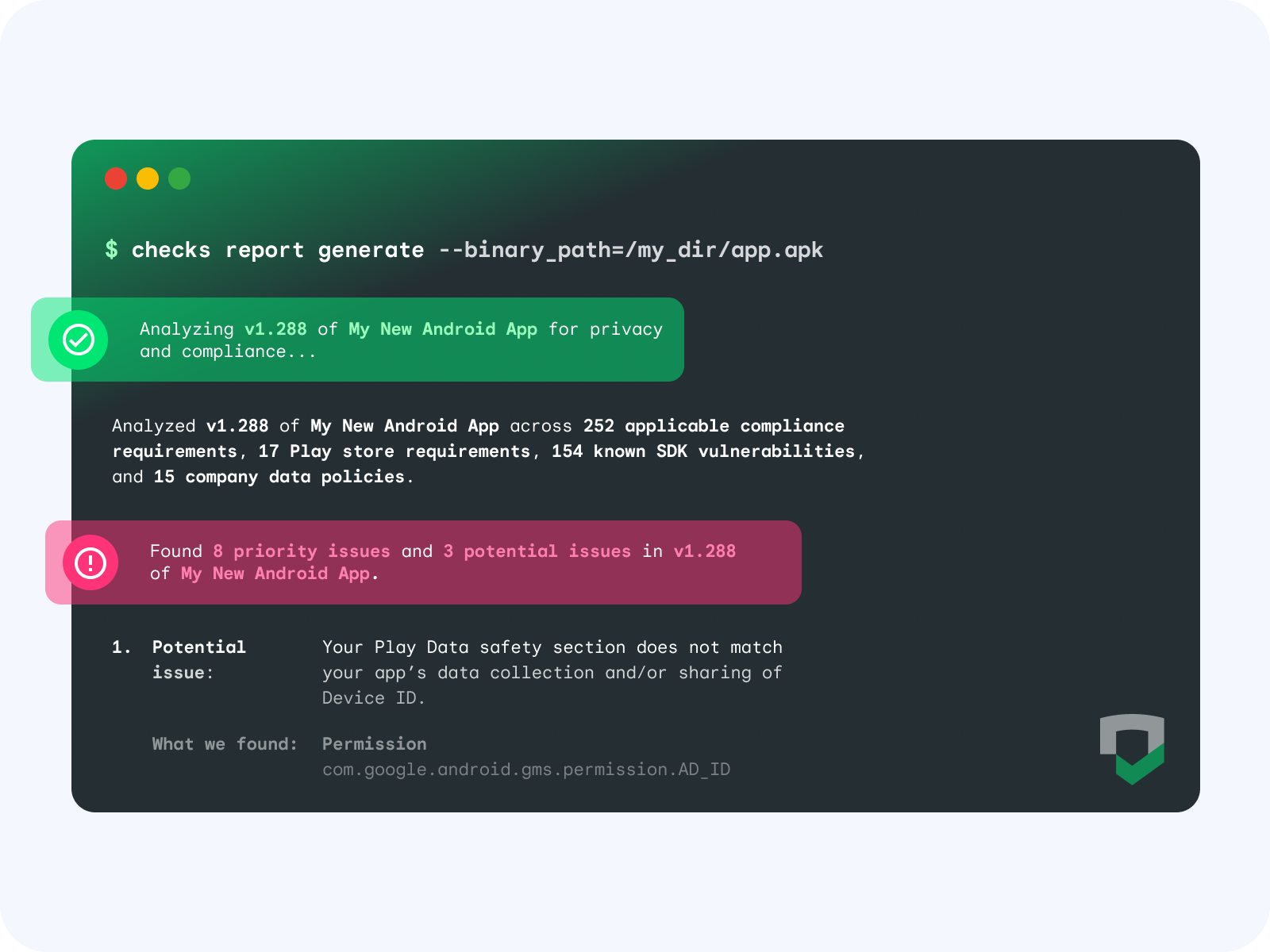 |
By adding Checks as a step in your CI/CD pipeline, you can automate app and code compliance scanning as part of the development lifecycle.
The top 5 benefits of integrating Checks in your CI/CD are:
- Real-time, intelligent alerting: You can stay informed of new compliance issues or changes in data behavior across your product portfolio with instant notifications via email or Slack.
- Understand data sharing & SDKs: Checks can help ensure secure third-party data sharing by gaining visibility into SDK integrations, permissions, and data flow analysis. By using Checks, you can be confident in your third-party dependencies before your public release.
- Ensure new builds follow your company policies: Checks enables you to automate data governance with custom policies that let you set up safeguards against specific endpoints, SDKs, data types, and permissions, tailoring privacy to your specific needs. These policies help ensure all new releases comply with your company’s data policies.
- Keep your Google Play Data safety section up-to-date: Checks can recommend Google Play Data safety section disclosures and alert you if you should make an update before releasing publicly, ensuring your declarations are always up-to-date.
- Deploy quickly and with confidence: When Checks finds issues in the CI/CD, these vulnerabilities are caught and remedied early, significantly reducing the risk of compliance violations once you deploy the app. Checks helps you maintain high compliance standards without slowing down the release cycle, enabling teams to deploy with confidence and ensuring that user data is protected from the outset.
Getting started is simple. Start by first signing up for Checks and then adding Checks to your CI/CD pipelines with these simple configuration steps. Once configured, Checks is ready to perform a variety of privacy and compliance verifications.
This proactive approach to privacy and compliance safeguards against potential risks and aligns with regulatory compliance requirements, making it an invaluable asset for any compliance and development team.
Posted by Jaclyn Konzelmann and Megan Li - Google Labs
Grab an API key in Google AI Studio, and get started with the Gemini API Cookbook
Less than two months ago, we made our next-generation Gemini 1.5 Pro model available in Google AI Studio for developers to try out. We’ve been amazed by what the community has been able to debug, create and learn using our groundbreaking 1 million context window.
Today, we’re making Gemini 1.5 Pro available in 180+ countries via the Gemini API in public preview, with a first-ever native audio (speech) understanding capability and a new File API to make it easy to handle files. We’re also launching new features like system instructions and JSON mode to give developers more control over the model’s output. Lastly, we’re releasing our next generation text embedding model that outperforms comparable models. Go to Google AI Studio to create or access your API key, and start building.
We’re expanding the input modalities for Gemini 1.5 Pro to include audio (speech) understanding in both the Gemini API and Google AI Studio. Additionally, Gemini 1.5 Pro is now able to reason across both image (frames) and audio (speech) for videos uploaded in Google AI Studio, and we look forward to adding API support for this soon.
 |
| You can upload a recording of a lecture, like this 117,000+ token lecture from Jeff Dean, and Gemini 1.5 Pro can turn it into a quiz with an answer key. Video sped up for demo purposes. |
Today, we’re addressing a number of top developer requests:
1. System instructions: Guide the model’s responses with system instructions, now available in Google AI Studio and the Gemini API. Define roles, formats, goals, and rules to steer the model's behavior for your specific use case.
Set System Instructions easily in Google AI Studio
2. JSON mode: Instruct the model to only output JSON objects. This mode enables structured data extraction from text or images. You can get started with cURL, and Python SDK support is coming soon.
3. Improvements to function calling: You can now select modes to limit the model’s outputs, improving reliability. Choose text, function call, or just the function itself.
Starting today, developers will be able to access our next generation text embedding model via the Gemini API. The new model, text-embedding-004, (text-embedding-preview-0409 in Vertex AI), achieves a stronger retrieval performance and outperforms existing models with comparable dimensions, on the MTEB benchmarks.
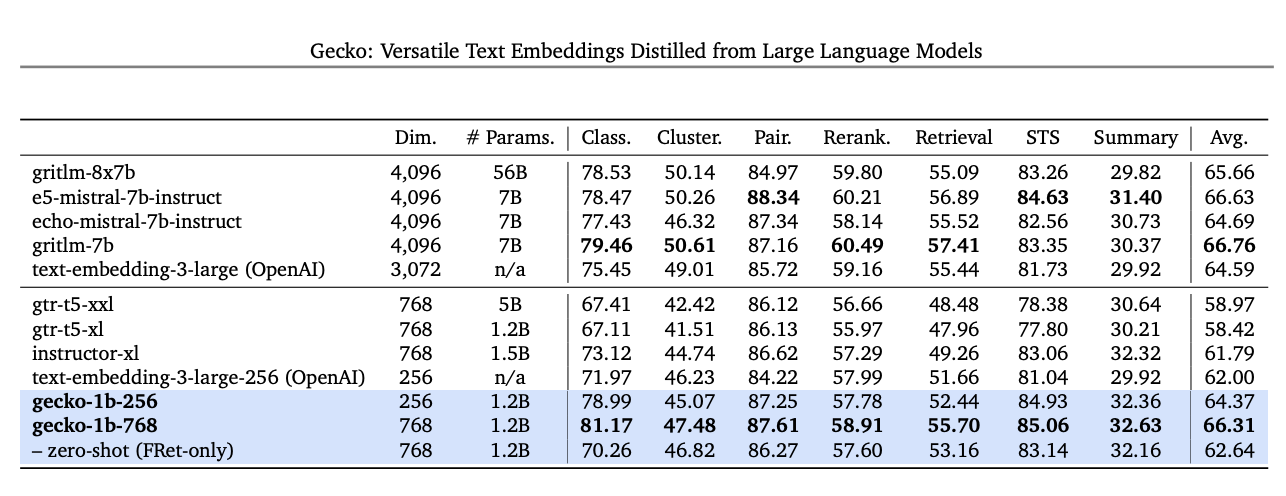 |
| 'Text-embedding-004' (aka Gecko) using 256 dims output outperforms all larger 768 dim output models on MTEB benchmarks |
These are just the first of many improvements coming to the Gemini API and Google AI Studio in the next few weeks. We’re continuing to work on making Google AI Studio and the Gemini API the easiest way to build with Gemini. Get started today in Google AI Studio with Gemini 1.5 Pro, explore code examples and quickstarts in our new Gemini API Cookbook, and join our community channel on Discord.

Startups are at the forefront of developing solutions for some of humanity's most pressing challenges by using AI, driving breakthroughs across industries from healthcare to cybersecurity.
To help AI-focused startups scale quickly while building responsibly, we’re thrilled to introduce the inaugural class of the Google for Startups Accelerator: AI-First program in North America. This new program is for startups building AI solutions based in the U.S. and Canada. This is the first of several AI-focused programs we'll offer throughout the year in Europe, India and Brazil.
This equity-free program provides 10 weeks of hands-on mentorship and technical project support to startups using AI in their core service or product. Selected startups will collaborate with a cohort of top peer founders and engage with leaders across Google. The curriculum will give founders access to the latest AI tools (including Google’s own Gemini), and will also include workshops on tech and infrastructure, UX and product, growth, sales, leadership and OKRs.
We’re thrilled to introduce the 15 AI startups selected for this accelerator:
Aptori, San Jose, CA. Aptori assists developers and security engineers to build secure, high-quality software.
Augmend, Seattle, WA. Augmend is an AI native Loom made for developers, making it possible to share expertise, not just videos.
Backpack Healthcare, Elkridge, MA. Backpack Healthcare is a pediatric mental health company utilizing proprietary AI technology, an engagement platform, and live therapists to offer personalized care to patients.
BrainLogic AI, Menlo Park, CA. BrainLogic AI has built a localized AI agent that connects users and businesses through whatsapp.
Cicerai, The Woodlands, TX. Cicerai is an AI-native Legal Practice Management Platform, boosting productivity and enhancing quality.
CLIKA, San Jose, CA. CLIKA simplifies deploying AI models on diverse hardware by offering automated model compression and format compilation.
Easel AI, Inc., Los Angeles, CA. Easel AI is an AI avatar-based social chat app that runs on iMessage.
Findly, San Francisco, CA. Findly is a data visualization integrator using a natural language chat interface.
Glass Health, San Francisco, CA. Glass Health empowers clinicians with the best-in-class AI platform for clinical decision support.
Kodif, Sunnyvale, CA. Kodif is a low-code AI-powered automation platform for support agent workflows to resolve customer issues.
Liminal, Indianapolis, IN. Liminal empowers regulated enterprises to securely deploy and use generative AI, horizontally covering every interaction and use case.
Mbue, Austin, TX. Mbue leverages AI to instantly review architectural drawings, catching errors earlier and streamlining the process.
Modulo Bio, San Diego, CA. Modulo Bio is building a platform to discover therapeutics that prevent or reverse neurodegenerative diseases.
Rocket Doctor, Toronto, ON, Canada. Rocket Doctor is a digital health platform and marketplace that intelligently matches patients and clinicians in a telemedicine 2.0 approach.
Sibli, Montreal, QC, Canada. Sibli is a fintech platform that processes unstructured data and identifies key insights for financial analysts.
The program kicks off at Cloud Next 2024 and culminates with a high profile Demo Day in June for potential partners, customers and investors.
After graduation, startups join the dynamic Google for Startups accelerator community, where they receive ongoing support and have the opportunity to build lasting connections with like-minded founders, mentors and investors.
We are honored to partner with this cohort of companies through this accelerator and beyond, to advance their AI technologies. Register your interest to get updates on the program, and join us in celebrating these exceptional startups!

In February we announced Gemma, our family of lightweight, state-of-the-art open models built from the same research and technology used to create the Gemini models. The community's incredible response – including impressive fine-tuned variants, Kaggle notebooks, integration into tools and services, recipes for RAG using databases like MongoDB, and lots more – has been truly inspiring.
Today, we're excited to announce our first round of additions to the Gemma family, expanding the possibilities for ML developers to innovate responsibly: CodeGemma for code completion and generation tasks as well as instruction following, and RecurrentGemma, an efficiency-optimized architecture for research experimentation. Plus, we're sharing some updates to Gemma and our terms aimed at improvements based on invaluable feedback we've heard from the community and our partners.
Harnessing the foundation of our Gemma models, CodeGemma brings powerful yet lightweight coding capabilities to the community. CodeGemma models are available as a 7B pretrained variant that specializes in code completion and code generation tasks, a 7B instruction-tuned variant for code chat and instruction-following, and a 2B pretrained variant for fast code completion that fits on your local computer. CodeGemma models have several advantages:
- Intelligent code completion and generation: Complete lines, functions, and even generate entire blocks of code – whether you're working locally or leveraging cloud resources.
- Enhanced accuracy: Trained on 500 billion tokens of primarily English language data from web documents, mathematics, and code, CodeGemma models generate code that's not only more syntactically correct but also semantically meaningful, helping reduce errors and debugging time.
- Multi-language proficiency: Your invaluable coding assistant for Python, JavaScript, Java, and other popular languages.
- Streamlined workflows: Integrate a CodeGemma model into your development environment to write less boilerplate, and focus on interesting and differentiated code that matters – faster.
 |
| This table compares the performance of CodeGemma with other similar models on both single and multi-line code completion tasks. Learn more in the technical report. |
Learn more about CodeGemma in our report or try it in this quickstart guide.
RecurrentGemma is a technically distinct model that leverages recurrent neural networks and local attention to improve memory efficiency. While achieving similar benchmark score performance to the Gemma 2B model, RecurrentGemma's unique architecture results in several advantages:
- Reduced memory usage: Lower memory requirements allow for the generation of longer samples on devices with limited memory, such as single GPUs or CPUs.
- Higher throughput: Because of its reduced memory usage, RecurrentGemma can perform inference at significantly higher batch sizes, thus generating substantially more tokens per second (especially when generating long sequences).
- Research innovation: RecurrentGemma showcases a non-transformer model that achieves high performance, highlighting advancements in deep learning research.
 |
| This chart reveals how RecurrentGemma maintains its sampling speed regardless of sequence length, while Transformer-based models like Gemma slow down as sequences get longer. |
To understand the underlying technology, check out our paper. For practical exploration, try the notebook, which demonstrates how to finetune the model.
Guided by the same principles of the original Gemma models, the new model variants offer:
- Open availability: Encourages innovation and collaboration with its availability to everyone and flexible terms of use.
- High-performance and efficient capabilities: Advances the capabilities of open models with code-specific domain expertise and optimized design for exceptionally fast completion and generation.
- Responsible design: Our commitment to responsible AI helps ensure the models deliver safe and reliable results.
- Flexibility for diverse software and hardware:
- Both CodeGemma and RecurrentGemma: Built with JAX and compatible with JAX, PyTorch, , Hugging Face Transformers, and Gemma.cpp. Enable local experimentation and cost-effective deployment across various hardware, including laptops, desktops, NVIDIA GPUs, and Google Cloud TPUs.
- CodeGemma: Additionally compatible with Keras, NVIDIA NeMo, TensorRT-LLM, Optimum-NVIDIA, MediaPipe, and availability on Vertex AI.
- RecurrentGemma: Support for all the aforementioned products will be available in the coming weeks.
Alongside the new model variants, we're releasing Gemma 1.1, which includes performance improvements. Additionally, we've listened to developer feedback, fixed bugs, and updated our terms to provide more flexibility.
These first Gemma model variants are available in various places worldwide, starting today on Kaggle, Hugging Face, and Vertex AI Model Garden. Here's how to get started:
- Access the models: Visit the Gemma website, Vertex AI Model Garden, Hugging Face, NVIDIA NIM APIs, or Kaggle for download instructions.
- Explore integration options: Find guides and resources for integrating the models with your favorite tools and platforms.
- Experiment and innovate: Add a Gemma model variant to your next project and explore its capabilities.
We invite you to try the CodeGemma and RecurrentGemma models and share your feedback on Kaggle. Together, let's shape the future of AI-powered content creation and understanding.

The ML Olympiad consists of Kaggle Community Competitions organized by ML GDE, TFUG, and other ML communities, aiming to provide developers with opportunities to learn and practice machine learning. Following successful rounds in 2022 and 2023, the third round has now launched with support from Google for Developers for each competition host. Over the last two rounds, 605 teams participated in 32 competitions, generating 105 discussions and 170 notebooks. We encourage you to join this round to gain hands-on experience with machine learning and tackle real-world challenges.
Over 20 ML Olympiad community competitions are currently open. Visit the ML Olympiad page to participate.
To see all the community competitions around the ML Olympiad, search "ML Olympiad" on Kaggle and look for further related posts on social media using #MLOlympiad. Browse through the available competitions and participate in those that interest you!
 Posted by Fergus Hurley – Co-Founder & GM, Checks, and Evan Otero – Product Manager, Checks
Posted by Fergus Hurley – Co-Founder & GM, Checks, and Evan Otero – Product Manager, Checks



 Posted by Matt Ridenour, Head of Startup Developer Ecosystem - USA
Posted by Matt Ridenour, Head of Startup Developer Ecosystem - USA
 Posted by Tris Warkentin – Director, Product Management and Jane Fine - Senior Product Manager
Posted by Tris Warkentin – Director, Product Management and Jane Fine - Senior Product Manager
 Posted by Bitnoori Keum – DevRel Community Manager
Posted by Bitnoori Keum – DevRel Community Manager