Google Cloud SQL is an easy-to-use service that delivers fully managed MySQL databases. It lets you hand off to Google the mundane, but necessary and often time consuming tasks — like applying patches and updates, managing backups and configuring replications — so you can put your focus on building great applications. And because we use vanilla MySQL, it’s easy to connect from just about any application, anywhere.
The first generation of Cloud SQL was launched in October 2011 and has helped thousands of developers and companies build applications. As
Compute Engine and
Persistent Disk have made great advancements since their launch, the second generation of Cloud SQL builds on their innovation to deliver an even better, more performant MySQL solution at a better price/performance ratio. We’re excited to announce the beta availability of the second generation of Cloud SQL — a new and improved Cloud SQL for Google Cloud Platform.
Speed, more speed and scalability
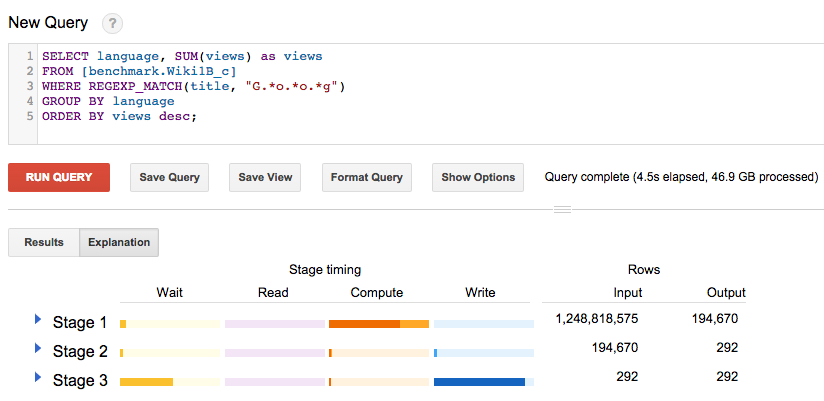
The two principal goals of the second generation of Cloud SQL are: better performance and scalability per dollar. The performance graph below speaks for itself. Second generation Cloud SQL is more than seven times faster than the first generation of Cloud SQL. And it scales to 10TB of data, 15,000 IOPS and 104GB of RAM per instance — well beyond the first generation.
 |
| Source: Google internal testing |
Yoga for your database (Cloud SQL is flexible)
Cloud users appreciate flexibility. And while flexibility is not a word frequently associated with relational databases, with Cloud SQL we’ve changed that. Flexibility means easily scaling a database up and down. For example, a database that’s growing in size and number of queries per day might require more CPU cores and RAM. A Cloud SQL instance can be changed to allocate additional resources to the database with minimal downtime. Scaling down is just as easy.
Flexibility means easily connecting to your database from any client with Internet access, including Compute Engine, Managed VMs, Container Engine and your workstation. Connectivity from
App Engine is only offered for Cloud SQL First Generation right now, but that will change soon. Because we embrace open standards by supporting MySQL Wire Protocol, the standard connection protocol for MySQL databases, you can access your managed Cloud SQL database from just about any application, running anywhere. For example:
- Use all your favorite tools, such as MySQL Workbench, Toad and the MySQL command-line tool to manage your Cloud SQL instances
- Get low latency connections from applications running on Compute Engine and Managed VMs
- Use standard drivers, such as Connector/J, Connector/ODBC, and Connector/NET, making it exceptionally easy to access Cloud SQL from most applications
Flexibility also means easily starting and stopping databases. Many databases must run 24x7, but some are used only occasionally for brief or infrequent tasks. Cloud SQL can be managed using the
Cloud Console (our browser-based administration console),
command line (part of our gCloud SDK) or a
RESTful API. The command line interface (CLI) and API make Cloud SQL administration scriptable and help users maximize their budgets by running their databases only when they’re needed.
The graph below shows the number of active Cloud SQL database instances running over time. Notice the clusters of five sawtooth-like ridges and then a drop for two additional ridges. These clusters show an increased number of databases running during business hours on Monday through Friday each week. Database activity, measured by the number of active databases, falls outside of business hours, especially on the weekends. This repeated rise and fall of database instances is a great example of flexibility. Its magnitude is helped significantly by first generation Cloud SQL’s ability to automatically sleep when it is not being accessed. While this is not a design goal of the second generation of Cloud SQL, users can quickly create and delete, or start and stop databases that only need to run on occasion. Cloud SQL users get the most from their budget because of the service’s flexibility.
What is a "managed" MySQL database?
Cloud SQL delivers fully managed MySQL databases, but what does that really mean? It means Google will apply patches and updates to MySQL, manage your backups, configure replication and provide automatic failover for High Availability (HA) in the event of a zone outage. It also means that you get Google’s operational expertise for your MySQL database. Google’s team of MySQL experts make configuring replication and automatic failover a breeze, so your data is protected and available. They also patch your database when important security updates are delivered. You choose when (day and time of week) the updates should be applied, and Google’s team takes care of the rest. This combined with Cloud SQL’s automatic encryption on database tables, temporary files and backups ensures your data is secure.
High Availability, replication and backups are configurable, so you can choose what's appropriate for each of your database instances. For development instances, you can choose to opt out of replication and automatic failover, while your production instances are fully protected. Even though we manage the database, you’re still in control.
Pricing: commitment issues
Getting the best Cloud SQL price doesn’t require you to commit to a one- or three-year contract. To get the best Cloud SQL price, just run your database 24x7 for the month. That’s it. If you use a database infrequently, you’ll be charged by the minute at the standard price. But there’s no need to decide upfront and Google helps find savings for you. No commitment, no strings attached. As a bonus, everyone gets the 100% sustained use discount during Beta, regardless of usage.
Ready to get started?
If you haven’t signed up for Google Cloud Platform, do so now and get a
$300 credit to test drive Cloud SQL. The second generation Cloud SQL has inexpensive micro instances for small applications, and easily scales up and out to serve performance-intensive applications.
You can also take advantage of our growing
partner ecosystem and tools to make working in Cloud SQL even easier. We’ve partnered with
Talend,
Attunity,
Dbvisit and
xPlenty to help you streamline the process of loading your data into Cloud SQL and with analytics products
Tableau,
Looker,
YellowFin and
Bime so you can easily create rich visualizations for meaningful insights. We’ve also integrated with
ScaleArc and
WebYog to help you monitor and manage your database and have partnered with service providers like
Pythian, so you can have expert support during your Cloud SQL implementations. Reach out to any of our partners if you need help getting up and running.
Bottom Line
Cloud SQL Second Generation makes what customers love about Cloud SQL First Generation faster and more scalable, at a better price per performance.
-
Posted by Brett Hesterberg, Product Manager, Google Cloud Platform