When developers use, choose, and contribute to open source software, effective documentation can make all the difference between a positive experience or a negative experience.
In fact, a
2017 GitHub survey that “Incomplete or Confusing Documentation” is the top complaint about open source software,
TechRepublic writes “Ask a developer what her primary gripes with open source are, and documentation gets top billing, and by a wide margin.”
Technical writers across Google are addressing this issue, starting with open source projects in Google Cloud. We'll be sharing what we learn along the way and are excited to offer this brief guide as a starting point.
Open source software documentation
Providing effective documentation for open source software can build strong, inclusive communities and increase the usage of your product. The same factors that encourage collaborative development in open source projects can have the same positive results with documentation. Open source software provides unique ways to create effective documentation.
When software is open sourced, users are regarded as contributors and can access the source code and the documentation. They’re encouraged to submit additions, fix code, report bugs, and update documentation. Having more contributors can increase the rate at which software and documentation evolve.
The best way to accelerate software adoption is to describe its benefits and demonstrate how to use it. The benefits of timely, effective, and accurate content are numerous. Because documentation can save enough time and money to pay for itself, it:
- Helps to create inclusive communities
- Makes for a better software product
- Promotes product adoption
- Reduces cost of ownership
- Reduces the user’s learning curve
- Makes for happy users
- Improves the user interface
When documentation is inadequate, the opposite can occur. Incorrect, old, or missing documentation can:
- Waste time
- Cause errors and destroy data
- Turn away customers
- Increase support costs
- Shorten a product’s life span
Why supplying effective documentation can be such a challenge
Useful documentation takes time to write and must be updated with the software. Did the installation process change? Are there better ways to configure performance? Was the user interface modified? Were new features introduced? Updates like these must be explained to new and existing customers.
It’s not enough to add words to a file and call it documentation.
How many times have you tried to use documentation that was five years out-of-date? How long did it take you to find another solution? (Not long, right?) Using old documentation can be like hiking an overgrown trail. The prospects of rogue branches, poison ivy, and getting lost suggest you are unlikely to emerge unscathed.
At first blush, writing documentation may seem optional. However, as a developer, you can literally be so close to your product that you take its features and purpose for granted. But your customers have no idea what you know, or how to apply what you know to address their business challenges. And time is money.
Remember the swimmer who got halfway across the English Channel only to say, “I’m tired,” before turning around and swimming back to shore? Ignoring the need for documentation is like that. Developing a software product gets you some of the way to your goal whereas helpful documentation fulfills your goal.
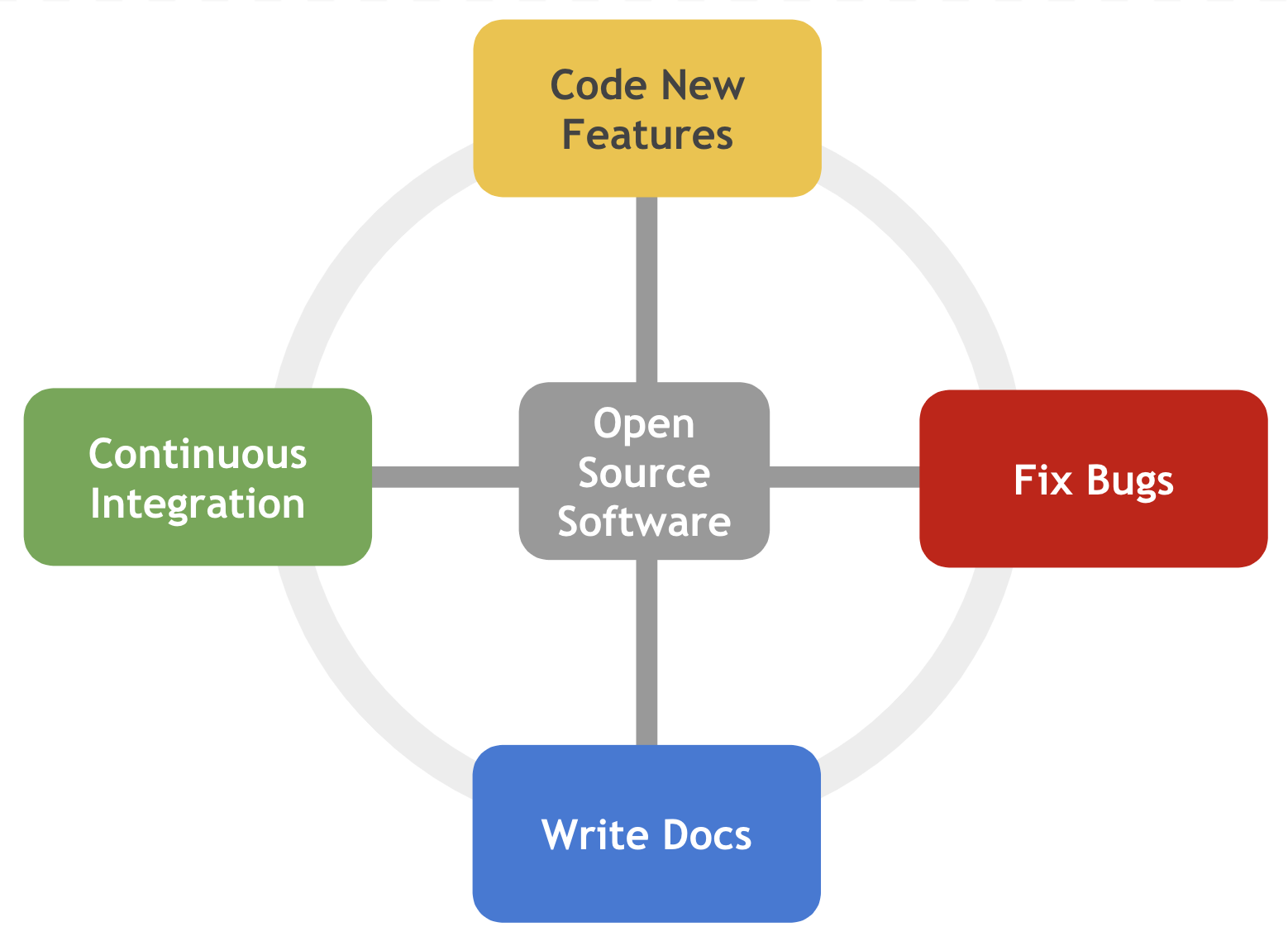
Momentum matters a lot. If you can settle into a rhythm of implementing new features, fixing bugs in the code, as well as writing and updating documentation, you can propel yourself to success.
Create an inclusive open source community
In the same GitHub survey referenced above, 95% of the respondents were men but evidence suggests that clear documentation:
- Can contribute to inclusive communities
- Is more highly valued by those groups who are typically under-represented
Documentation that effectively explains a project's processes, such as contributing to guides and defining codes of conduct, is valued more by groups that are underrepresented in the open source community, such as women.
Factors that can lead to ineffective documentation
Conditions like these almost always compromise the quality of documentation:
- Belief that it’s enough for open source software to just work.
- Notion that a specification is as good as instructional text.
- Idea that casual unreviewed contributions are sufficient.
- Belief that unscheduled and unspecified software updates are acceptable.
- Minimal to no style guidelines.
Conquer your documentation challenges
Use these best practices to provide helpful and timely documentation:
1. Identify common terminology
Define and influence the usage and adoption of terminology for your open source project. Use the same terminology in the guides and in the product. Involving a writer early in product development can lead to a natural synergy between the user interface, guides, and training materials.
With clear definitions of terms and consistent usage in the documentation, you can teach your community to speak a common language. As a result, everyone in your products’ ecosystem can communicate more effectively with each other.
2. Provide contribution guidelines
Opensource.com describes exactly why
contribution guidelines are so important. Consider how
Kubernetes describes the types of documentation contributions your users can make and how to make them.
3. Create a documentation template
To make sure your contributors provide details in a consistent format, consider providing a document template to capture details for common topics such as:
- Overview
- Prerequisites
- Procedural steps
- What’s next
4. Document new and updated features
When a feature is added or updated, ask that it be documented. You can even provide guidelines to capture key information. Initially, some may think it cumbersome to require that instructions be provided early in the development process. However, think of documentation to be like testing in that nobody really wants to do it but things work so much better. Sufficient testing and teaching are good for quality and momentum.
Code reviewers and maintainers of open source software have power. Code reviewers can (and should) withhold approval until documentation is sufficient.
Remember, not all changes require documentation updates. Here’s a good rule of thumb:
If an update to a project will require users to change their behavior, then documentation updates may be required.If not, how will your customers find the new feature you worked so hard to implement? Said another way, if a change doesn't require tests, it probably doesn't require docs, either. Use your best judgement. For example, code refactoring and experimental tweaks need not be tested or documented.
As always, simplify and automate this process as much as possible. At Google, teams can enforce a presubmit check that either looks for a flag that indicates a doc update isn't necessary (presubmit checks for style issues can prevent a lot of arguments, too). We also allow owners of a file to submit changes without a review.
If your team balks at this requirement, remind them that simple project documentation is about sharing the information you have in your head so that many others can access it later without bothering you.
Documentation updates aren't typically onerous! The size of your documentation change scales with the size of your pull request (PR). If your PR contains a thousand lines of code, you may need to write a few hundred lines of documentation. If the PR contains a one-line change, you may need to change a word or two.
Finally, remember that documentation needn’t be perfect, but instead fit for use. What's most important is that key information is clearly conveyed.
5. Conduct regular freshness reviews
At least every quarter, review and update your content. Many hands make for many voices, many typos, and many inconsistencies. Don’t let content persist unchecked for years without periodically confirming it’s still useful.
In conclusion, success breeds success. By effectively documenting open source software, everybody wins.
We hope you'll put this guidance to work and help your open source project become even more successful! We'd love to hear from you if you do, or if you have questions or useful advice to share.
By Janet Davies, Google OpenDocs