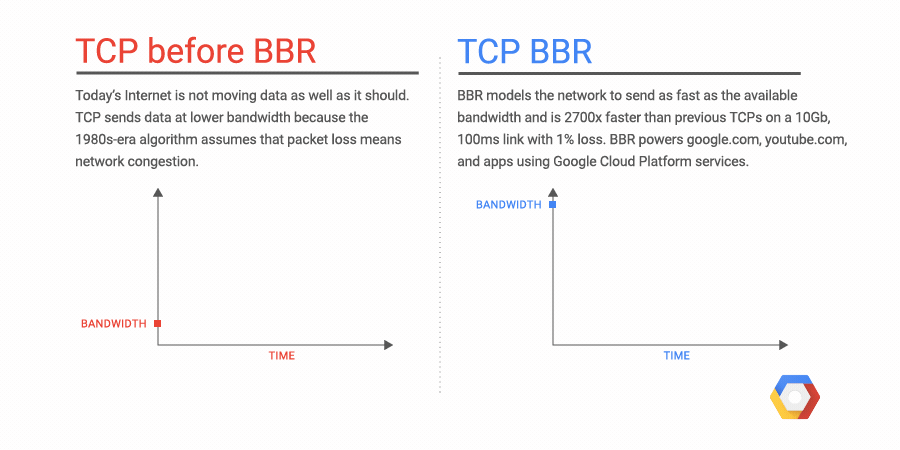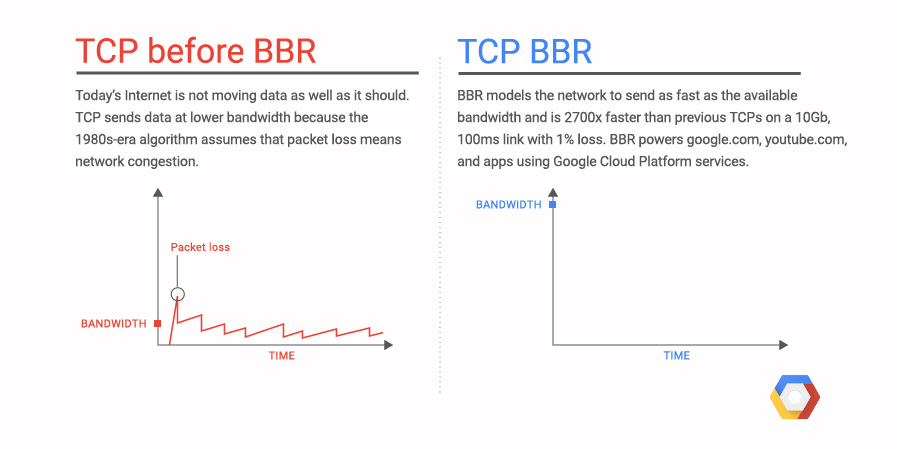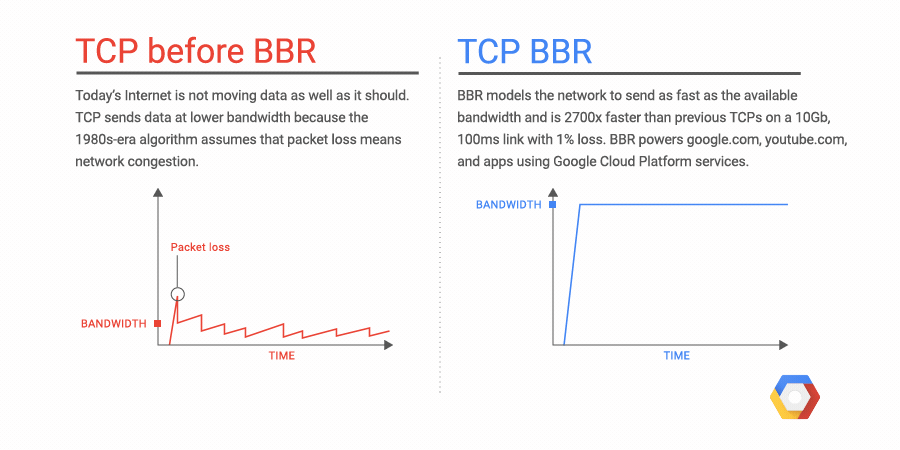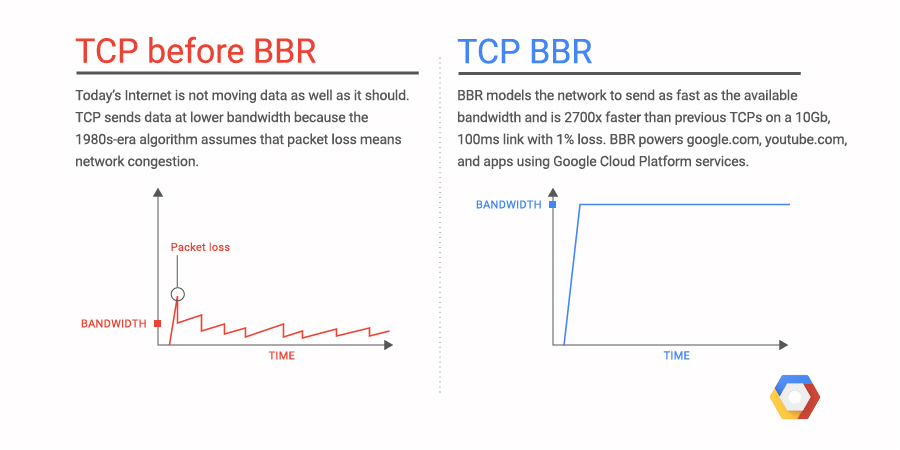
We're excited to announce Network Service Tiers Alpha. Google Cloud Platform (GCP) now offers a tiered cloud network. We let you optimize for performance by choosing Premium Tier, which uses Google’s global network with unparalleled quality of service, or optimize for cost, using the new Standard Tier, an attractively-priced network with performance comparable to that of other leading public clouds.
"Over the last 18 years, we built the world’s largest network, which by some accounts delivers 25-30% of all internet traffic” said Urs Hölzle, SVP Technical Infrastructure, Google. “You enjoy the same infrastructure with Premium Tier. But for some use cases, you may prefer a cheaper, lower-performance alternative. With Network Service Tiers, you can choose the network that’s right for you, for each application.”
Power of Premium Tier
If you use Google Cloud today, then you already use the powerful Premium Tier.Premium Tier delivers traffic over Google’s well-provisioned, low latency, highly reliable global network. This network consists of an extensive global private fiber network with over 100 points of presence (POPs) across the globe. By this measure, Google’s network is the largest of any public cloud provider.

In Premium Tier, inbound traffic from your end user to your application in Google Cloud enters Google’s private, high performance network at the POP closest to your end user, and GCP delivers this traffic to your application over its private network.
 |
| Outbound and Inbound traffic delivery |
We architected the Google network to be highly redundant, to ensure high availability for your applications. There are at least three independent paths (N+2 redundancy) between any two locations on the Google network, helping ensure that traffic continues to flow between these two locations even in the event of a disruption. As a result, with Premium Tier, your traffic is unaffected by a single fiber cut. In many situations, traffic can flow to and from your application without interruption even with two simultaneous fiber cuts.
GCP customers use Global Load Balancing, another Premium Tier feature, extensively. You not only get the management simplicity of a single anycast IPv4 or IPv6 Virtual IP (VIP), but can also expand seamlessly across regions, and overflow or fail over to other regions.

"75% of homedepot.com is now served out of Google Cloud. From the get-go, we wanted to run across multiple regions for high availability. Google's global network is one of the strongest features for choosing Google Cloud."
— Ravi Yeddula, Senior Director Platform Architecture & Application Development, The Home Depot.
Introducing Standard Tier
Our new Standard Tier delivers network quality comparable to that of other major public clouds, at a lower price than our Premium Tier.
Why is Standard Tier less expensive? Because we deliver your outbound traffic from GCP to the internet over transit (ISP) networks instead of Google’s network.
 |
| Outbound and Inbound traffic delivery |
Standard Tier provides lower network performance and availability compared to Premium Tier. Since we deliver your outbound and inbound traffic on Google’s network only on the short hop between GCP and the POP closest to it, the performance, availability and redundancy characteristics of Standard Tier depend on the transit provider(s) carrying your traffic. Your traffic may experience congestion or outages more frequently relative to Premium Tier, but at a level comparable to other major public clouds.
We also provide only regional network services in Standard Tier, such as the new regional Cloud Load Balancing service. In this tier, your Load Balancing Virtual IP (VIP) is regional, similar to other public cloud offerings, and adds management complexity compared to Premium Tier Global Load Balancing, if you require multi-region deployment.

Compare performance of tiers
We commissioned Cedexis, an internet performance monitoring and optimization tools company, to take preliminary performance measurements for both Network Service Tiers. As expected, Premium Tier delivers higher throughput and lower latency than Standard Tier. You can view the live dashboards at www.cedexis.com/google-reports/ under the "Network Tiers" section. Cedexis also details their testing methodology on their website.Cedexis graph below shows throughput for Premium and Standard Tier for HTTP Load Balancing traffic at 50th percentile. Standard (blue line) throughput is 3,223 kbps while Premium (green line) is 5,401 kbps, making Premium throughput ~1.7x times that of Standard. See Cedexis graph below:

In general, Premium Tier displays considerably higher throughput, at every percentile, than Standard Tier.
Compare pricing for tiers
We're introducing new pricing for Premium and Standard Tiers. You can review detailed pricing for both tiers here. This pricing will take effect when Network Service Tiers become Generally Available (GA). While in alpha and beta, existing internet egress pricing applies.
With the new Network Tiers pricing (effective at GA), outbound traffic (GCP to internet) is priced 24-33% lower in Standard Tier than in Premium Tier for North America and Europe. Standard Tier is less expensive than internet egress options offered by other major public cloud providers (based on typical published prices for July, 2017). Inbound traffic remains free for both Premium and Standard Tiers. We'll also change our current destination-based pricing for Premium Tier to be based on both source and destination of traffic since the cost of network traffic varies with the distance your traffic travels over Google’s network. In contrast, Standard Tier traffic will be source-based since it does not travel much over Google’s network.
Choose the right tier
Here’s a decision tree to help you choose the tier that best fits your requirements.

Configure the tier for your application(s)
One size does not fit all, and your applications in Google Cloud often have differing availability, performance, footprint and cost requirements. Configure the tier at the resource-level (per Instance, Instance template, Load balancer) if you want granular control or at the overarching project-level if you want to use the same tier across all resources.

Try Network Service Tiers today
“Cloud customers want choices in service levels and cost. Matching the right service to the right business requirements provides the alignment needed by customers. Google is the first public cloud provider to recognize that in the alpha release of Network Service Tiers. Premium Tier caters to those who need assured quality, and Standard Tier to those who need lower costs or have limited need for global networking.”
— Dan Conde, Analyst at ESG
Learn more by visiting Network Service Tiers website, and give Network Service Tiers a spin by signing up for alpha. We look forward to your feedback!