Guest post by the Engineering teams at Mirru and Tweag
What is the Mirru App?
Mirru is a free and open source Android app under development with which one can control robotic prosthetic hands via hand tracking. With our app, a user can instantly mirror grips from their sound hand onto a robotic one, which could be 3D-printed and self-assembled at low cost. With Mirru, we want to provide a cheap, intuitive and open end-to-end alternative to existing, costly, cumbersome and proprietary technology.
Figure 1: A demonstration of using MediaPipe hand tracking to move a robotic hand’s fingers with the Mirru app.
The Mirru team is a collaboration between Violeta López and Vladimir Hermand, two independent designers and technologists currently based in Paris. To kickstart the project, the team took part in Tweag’s Open Source Fellowship program which provided funding, mentorship and data engineering expertise from one of their engineers, Dorran Howell. The fellowship helped get Mirru launched from the ground-up.
Our goal for the 3-month fellowship was to develop an initial version of the Android app that can control any bluetooth open source hand using computer vision techniques, and make the app available for free on the Google Play store so anyone can print their own hand, assemble it, and download the app. With the help of MediaPipe, we were able to quickly prototype our app without having to build our own machine learning model, as we didn’t have the resources or training data to do so.
Why use hand tracking?
Using your phone and a front-facing camera with hand tracking opens up a new, affordable, accessible, and versatile way to control prosthetics.
Let's say I'm a left hand amputee who owns a robotic prosthesis. Every day, I need my prosthetic hand to actuate a lot of different grip patterns. For example, I need to use a pinch or tripod grip to pick up small objects, or a fist grip to pick up objects like a fruit or a cup. I change and execute these grip patterns via myoelectric muscle sensors that allow me to, for example, open and close a grip by flexing and unflexing my upper limb muscles. These myoelectric muscle sensors are the main interface between my body and the prosthesis.
However, living with them is not as easy as it seems. Controlling the myoelectric sensors can take a lot of time to get used to, and many never do. It can also be quite expensive to get these sensors fitted by a prosthetist, especially for people in developing countries or anyone without health insurance. Finally, the number of grips on many devices currently on the market is limited to less than ten, and only few models come with ways to create custom grips, which are often cumbersome.
Mirru provides an alternative interface. Using just their phone, a tool many have access to, a user can digitally mirror their sound hand in real-time and communicate with their prosthesis in an intuitive way. This removes the expensive need to be fitted by a prosthetist and enables the user to quickly program an unlimited amount of grips. For now, Mirru stays away from electromyography altogether as reliable muscle sensors are expensive. The programmed grips therefore need to be triggered via the android phone, which is why this first version of our app is more suited for activities like sweeping, holding a book while reading it, or holding a cup or shopping bag. In the future we hope to combine myoelectric sensors with hand tracking to get the benefits of both.
Programming a grip with the Mirru app looks like the following: Let’s say that I want to grab an object with my robotic hand. I bring my prosthesis near the object and I then form the desired grip with my sound hand in front of my android phone and Mirru mirrors it in real-time to the prosthesis. I then lock my prosthesis into this new grip and free up my vsound hand. Finally I might save this grip for later use and add it to my library of grips.
Figure 2: A user tester using hand-tracking on their phone to program their prosthesis’s grip to pick up a measuring tape and measure with the other hand.
The Brunel Hand and the Mirru Arduino Sketch
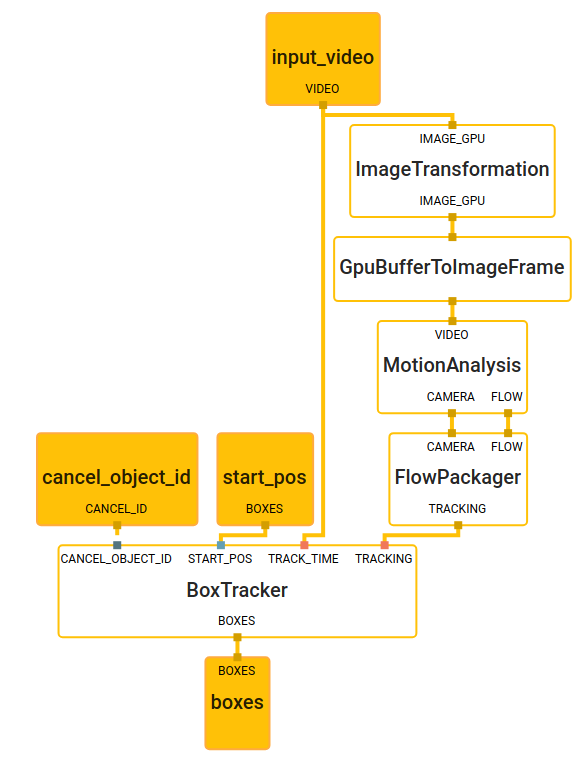
In order to accomplish our goal of allowing as many people as possible to print, assemble, and control their own hand, we designed the Mirru android app to be compatible with any robotic hand that is controlled by a bluetooth-enabled Arduino board and servo motors.
For our project, we printed and assembled an open source robotic hand called the Brunel Hand made by Open Bionics. First, we 3D printed the Brunel Hand’s 3D printable files that are made available under the CC Attribution-Sharealike 4.0 International License. We then bought the necessary servos, springs, and screws to assemble the hand. In combination with printing and buying the servos, the hand costs around €500 to purchase and assemble.
The Brunel Hand comes with myoelectric-based firmware and a PCB board developed by Open Bionics, but since the hand is in essence just 4 servo motors, any microcontroller could be used. We ended up using an Adafruit ESP32 feather board for its bluetooth capabilities and created an Arduino sketch that can be downloaded, customized, and uploaded for anyone who is printing and assembling their own hand. They could then download the Mirru app to use as the control-interface for their printed hand.
Hand-tracking with MediaPipe
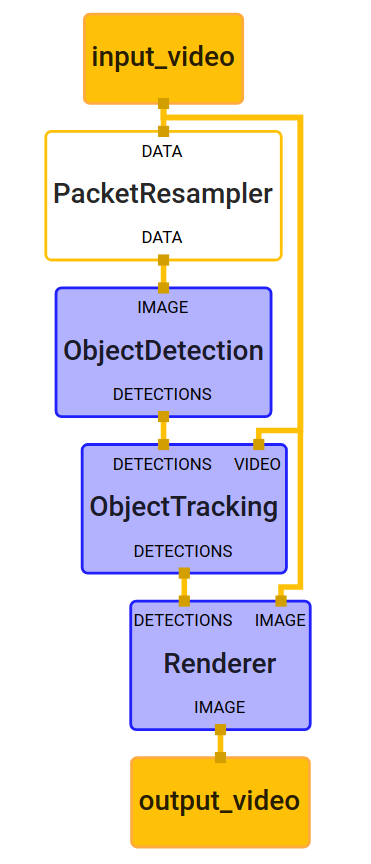
There are many computer vision solutions available for hand tracking that could be used for this project, but we needed a fast, open source solution that didn’t require us to train our own model, and that could be used reliably on a portable device such as a phone.
MediaPipe provides great out of the box support for hand tracking, and since we didn’t have the training data or resources available to create a model from scratch, it was perfect for our team. We were able to build the Android example apps easily and were excited to find that the performance was promising. Even better, no tweaking on the ready-made hand tracking model or the graphs was necessary, as the hand landmark model provided all the necessary outputs for our prototype.
When testing the prosthesis on real users, we were happy to hear that many of them were impressed with how fast the app was able to translate their movements, and that nothing else exists on the market that allows you to make custom grips as fast and on-the-fly.
Figure 3: A user tester demonstrates how quickly the MediaPipe hand-tracking can translate her moving fingers to the movement of her prosthesis’s fingers.
Translating 3D MediaPipe points into inputs for Robotics
To achieve the goals of the Mirru app, we need to use hand tracking to independently control each finger of the Brunel Hand in real-time. In the Brunel Hand, the index, middle, and ring fingers are actuated using servos that move at an angle from 0 to 180 degrees; 0 means the finger is fully upright and 180 means the finger is fully flexed down. As we lacked adequate training data to create a model from scratch that could calculate these servo angles for us, we opted to use a heuristic to relate the default hand tracking landmark outputs to the inputs required by our hardware for an initial version of our prototype.
Figure 4: In the lab testing the translation of the outputs to inputs with the app and the prototype.
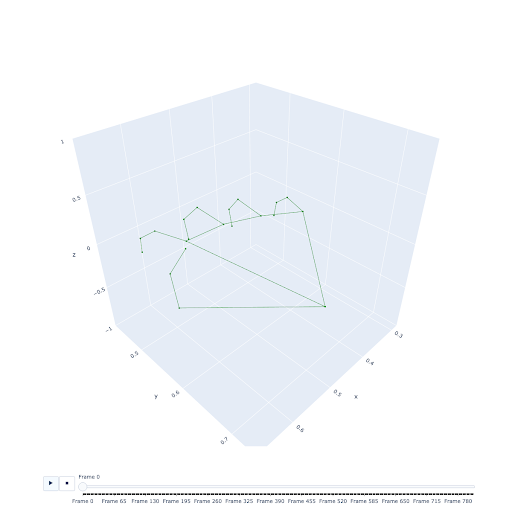
We were initially unsure whether the estimated depth (Z) coordinate in the 3D landmarks would be accurate enough for the translation of inputs or if we would be limited to working in 2D. As an initial step, we recorded an example dataset and spun up a visualization of the points in a Jupyter Notebook with Plotly. We were immediately impressed by the quality and accuracy of the coordinates, considering that the technology only uses a single camera without any depth sensors. As noted in the MediaPipe documentation, The Z coordinates have a slightly different scale than the X/Y coordinates, but this didn’t seem to pose a significant challenge for our prototype.
Figure 5: A data visualization of the hand made up of 21 3D hand landmarks provided by MediaPipe.
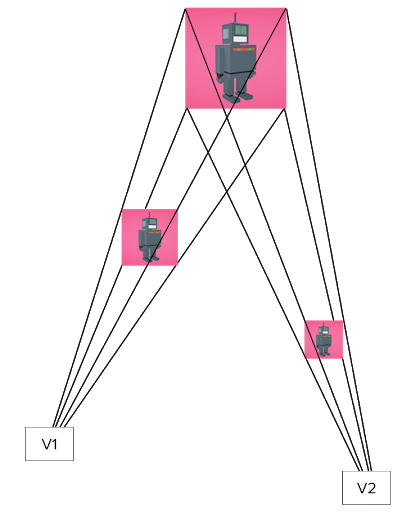
Given the accuracy of the 3D landmarks, we opted to use a calculation in 3D for relating landmark outputs to the inputs required by the prosthesis. In our approach, we calculate the acute angles of the fingers in relation to the palm by calculating the angle between the finger direction and the normal of the plane defined by the palm. An angle of 0° corresponds to maximum closure of the finger, and an angle of 180° indicates a fully extended finger. We were able to calculate the finger direction by calculating the vector from the landmark at the base of the fingers to the landmark on the tip of the fingers.
Figure 6: Diagram showing the 3D landmarks and which ones we used to calculate the finger direction vector, the palm normal, and the angle that both form.
We calculate the palm normal by selecting three points in the plane of the palm. Using Landmark 0 as the reference point, we calculate the vectors for side 1 and side 2, and compute the cross product of those vectors to give us the palm normal. Finally, we compute the angle of the finger direction and the palm normal. This returns an angle in radians that we use to calculate degrees.
We had to do some extra processing to match the degrees of freedom for the thumb on our prosthetic hand. The thumb moves in more complex ways than the rest of the fingers. In order to get our app to work with the thumb, we did similar calculations for thumb direction and the palm normal, but we used different landmarks.
Once we do the calculation of the servo angles on the android phone, we send those values via bluetooth to the Arduino board, and the Arduino board moves the servos to the proper position. Due to some noise in the model outputs, we add a smoothing step to the pipeline, which is important so that the movements of the robotic fingers aren’t too jittery for precise grips.
Figure 7: A user tester makes a pinch grip on her prosthesis with the Mirru app.
Summary
The Mirru app and Mirru Arduino Sketch are designed to allow anyone to control an open source prosthesis with their sound hand and an Android phone. This is a novel and frugal alternative to muscle sensors, and MediaPipe has proven that it is the right tool for the essential hand tracking component of the full application. The Mirru team was able to get started quickly with MediaPipe’s out of the box solutions without having to gather any training data or having to design a model from scratch. The speed of the real-time translation from hand tracking points to the robotic hand has especially excited all of our users in our testing sessions and opens up many possibilities for the future of prostheses.
We see exciting potential for combining the MediaPipe hand tracking features with existing myoelectric prostheses which could open powerful and advanced ways to create and save custom prosthesis grips in real-time. Also, with the help of MediaPipe, we have been able to provide an open source alternative to proprietary prostheses without the need for myoelectric sensors or a visit to a prosthetist, at a cost that is much lower than what is already on the market, and whose source code can be customized and built-upon by other developers. Our team is excited to see what other ideas the open source community might come up with, and to see what hand tracking can bring to users and manufacturers of prostheses.
As for the current state of the Mirru application, we have yet to implement the possibility of recording and saving moving gestures that are longer sequences compared to the static grip positions. For example, imagine being able to record the movement of the fingers to play a bass line on a piano, like a loopable animated gif. There is a realm of possibilities for prostheses that is waiting to be explored, and we’re really happy that MediaPipe gives us access to it.
We are looking for contributors. If you have ideas or comments about this application, please reach out to [email protected], or visit our GitHub.
This blog post is curated by Igor Kibalchich, ML Research Product Manager at Google AI.






















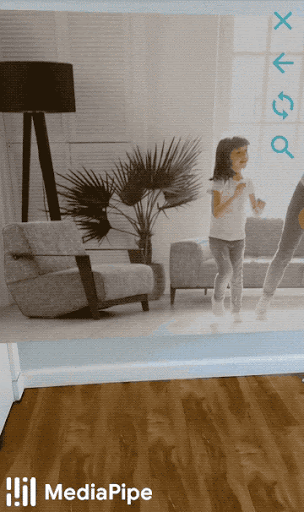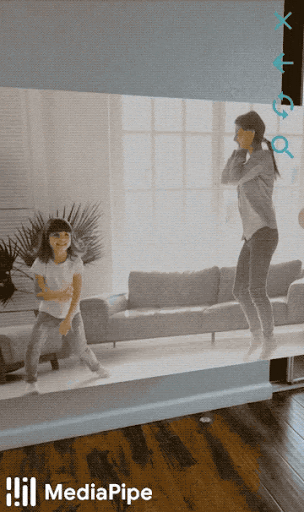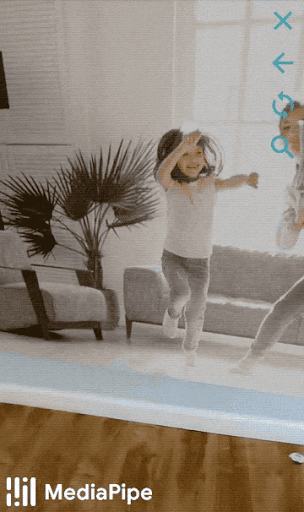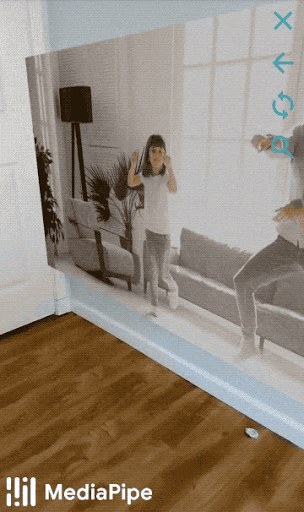














 Posted by Michael Hays and Tyler Mullen from the MediaPipe team
Posted by Michael Hays and Tyler Mullen from the MediaPipe team 


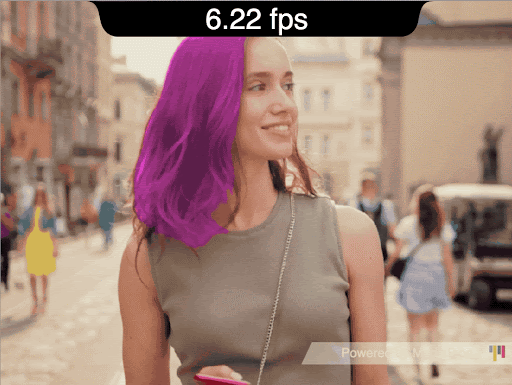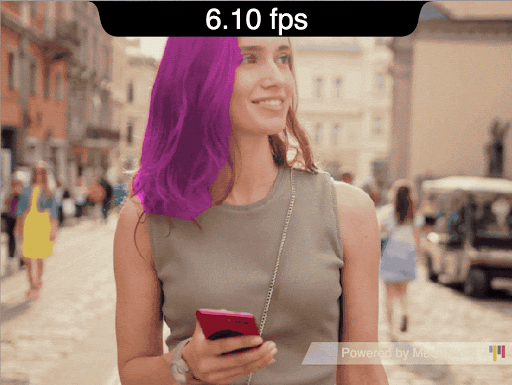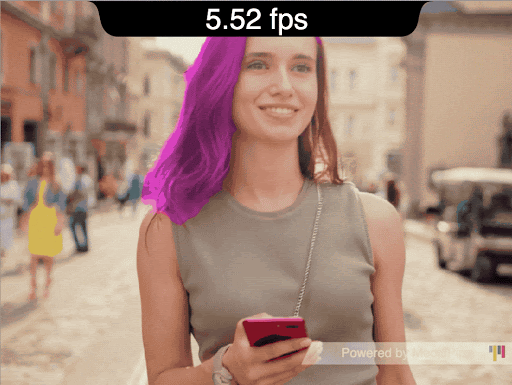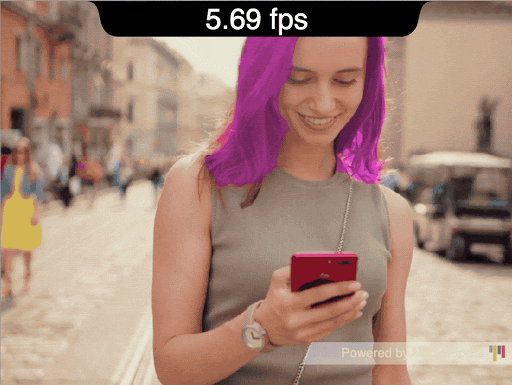


 Posted by
Posted by