Despite recent leaps in imaging technology, especially on mobile devices, image noise and limited sharpness remain two of the most important levers for improving the visual quality of a photograph. These are particularly relevant when taking pictures in poor light conditions, where cameras may compensate by increasing the ISO or slowing the shutter speed, thereby exacerbating the presence of noise and, at times, increasing image blur. Noise can be associated with the particle nature of light (shot noise) or be introduced by electronic components during the readout process (read noise). The captured noisy signal is then processed by the camera image processor (ISP) and later may be further enhanced, amplified, or distorted by a photographic editing process. Image blur can be caused by a wide variety of phenomena, from inadvertent camera shake during capture, an incorrect setting of the camera’s focus (automatic or not), or due to the finite lens aperture, sensor resolution or the camera’s image processing.
It is far easier to minimize the effects of noise and blur within a camera pipeline, where details of the sensor, optical hardware and software blocks are understood. However, when presented with an image produced from an arbitrary (possibly unknown) camera, improving noise and sharpness becomes much more challenging due to the lack of detailed knowledge and access to the internal parameters of the camera. In most situations, these two problems are intrinsically related: noise reduction tends to eliminate fine structures along with unwanted details, while blur reduction seeks to boost structures and fine details. This interconnectedness increases the difficulty of developing image enhancement techniques that are computationally efficient to run on mobile devices.
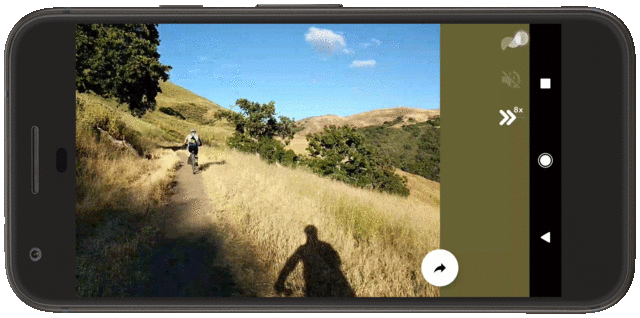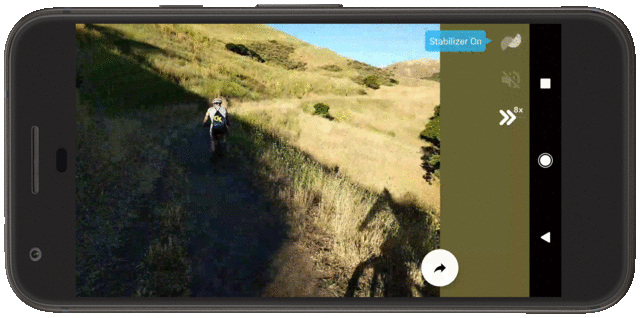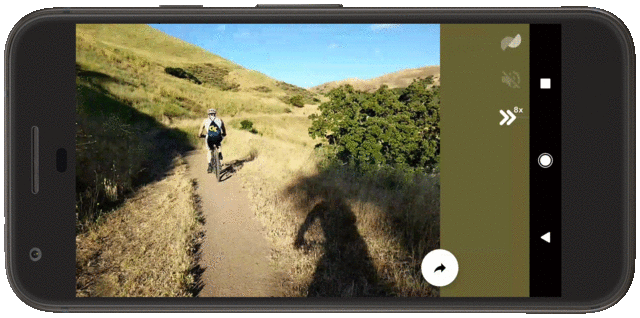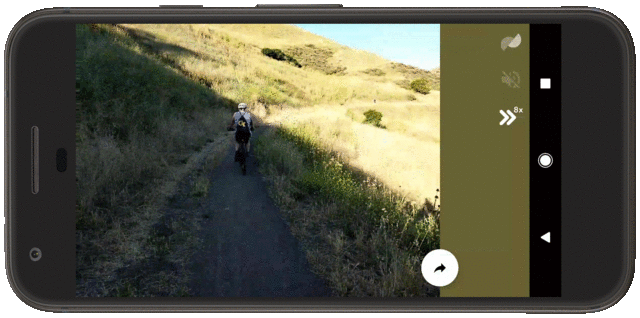
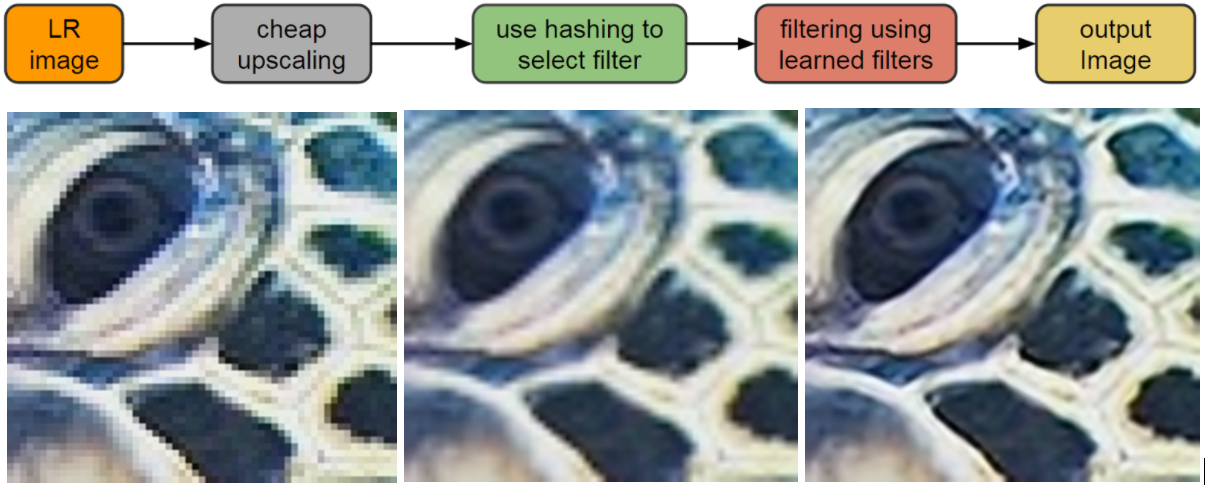
Today, we present a new approach for camera-agnostic estimation and elimination of noise and blur that can improve the quality of most images. We developed a pull-push denoising algorithm that is paired with a deblurring method, called polyblur. Both of these components are designed to maximize computational efficiency, so users can successfully enhance the quality of a multi-megapixel image in milliseconds on a mobile device. These noise and blur reduction strategies are critical components of the recent Google Photos editor updates, which includes “Denoise” and “Sharpen” tools that enable users to enhance images that may have been captured under less than ideal conditions, or with older devices that may have had more noisy sensors or less sharp optics.
 |
| A demonstration of the “Denoise” and “Sharpen” tools now available in the Google Photos editor. |
How Noisy is An Image?
In order to accurately process a photographic image and successfully reduce the unwanted effects of noise and blur, it is vitally important to first characterize the types and levels of noise and blur found in the image. So, a camera-agnostic approach for noise reduction begins by formulating a method to gauge the strength of noise at the pixel level from any given image, regardless of the device that created it. The noise level is modeled as a function of the brightness of the underlying pixel. That is, for each possible brightness level, the model estimates a corresponding noise level in a manner agnostic to either the actual source of the noise or the processing pipeline.
To estimate this brightness-based noise level, we sample a number of small patches across the image and measure the noise level within each patch, after roughly removing any underlying structure in the image. This process is repeated at multiple scales, making it robust to artifacts that may arise from compression, image resizing, or other non-linear camera processing operations.
 |
| The two segments on the left illustrate signal-dependent noise present in the input image (center). The noise is more prominent in the bottom, darker crop and is unrelated to the underlying structure, but rather to the light level. Such image segments are sampled and processed to generate the spatially-varying noise map (right) where red indicates more noise is present. |
Reducing Noise Selectively with a Pull-Push Method
We take advantage of self-similarity of patches across the image to denoise with high fidelity. The general principle behind such so-called “non-local” denoising is that noisy pixels can be denoised by averaging pixels with similar local structure. However, these approaches typically incur high computational costs because they require a brute force search for pixels with similar local structure, making them impractical for on-device use. In our “pull-push” approach1, the algorithmic complexity is decoupled from the size of filter footprints thanks to effective information propagation across spatial scales.
The first step in pull-push is to build an image pyramid (i.e., multiscale representation) in which each successive level is generated recursively by a “pull” filter (analogous to downsampling). This filter uses a per-pixel weighting scheme to selectively combine existing noisy pixels together based on their patch similarities and estimated noise, thus reducing the noise at each successive, “coarser” level. Pixels at coarser levels (i.e., with lower resolution) pull and aggregate only compatible pixels from higher resolution, “finer” levels. In addition to this, each merged pixel in the coarser layers also includes an estimated reliability measure computed from the similarity weights used to generate it. Thus, merged pixels provide a simple per-pixel, per-level characterization of the image and its local statistics. By efficiently propagating this information through each level (i.e., each spatial scale), we are able to track a model of the neighborhood statistics for increasingly larger regions in a multiscale manner.
After the pull stage is evaluated to the coarsest level, the “push” stage fuses the results, starting from the coarsest level and generating finer levels iteratively. At a given scale, the push stage generates “filtered” pixels following a process similar to that of the pull stage, but going from coarse to finer levels. The pixels at each level are fused with those of coarser levels by doing a weighted average of same-level pixels along with coarser-level filtered pixels using the respective reliability weights. This enables us to reduce pixel noise while preserving local structure, because only average reliable information is included. This selective filtering and reliability (i.e. information) multiscale propagation is what makes push-pull different from existing frameworks.
 |
| This series of images shows how filtering progresses through the pull-push process. Coarser level pixels pull and aggregate only compatible pixels from finer levels, as opposed to the traditional multiscale approaches using a fixed (non-data dependent) kernel. Notice how the noise is reduced throughout the stages. |
The pull-push approach has a low computational cost, because the algorithm to selectively filter similar pixels over a very large neighborhood has a complexity that is only linear with the number of image pixels. In practice, the quality of this denoising approach is comparable to traditional non-local methods with much larger kernel footprints, but operates at a fraction of the computational cost.
 |
 |
| Image enhanced using the pull-push denoising method. |
How Blurry Is an Image?
An image with poor sharpness can be thought of as being a more pristine latent image that was operated on by a blur kernel. So, if one can identify the blur kernel, it can be used to reduce the effect. This is referred to as “deblurring”, i.e., the removal or reduction of an undesired blur effect induced by a particular kernel on a particular image. In contrast, “sharpening” refers to applying a sharpening filter, built from scratch and without reference to any particular image or blur kernel. Typical sharpening filters are also, in general, local operations that do not take account of any other information from other parts of the image, whereas deblurring algorithms estimate the blur from the whole image. Unlike arbitrary sharpening, which can result in worse image quality when applied to an image that is already sharp, deblurring a sharp image with a blur kernel accurately estimated from the image itself will have very little effect.
We specifically target relatively mild blur, as this scenario is more technically tractable, more computationally efficient, and produces consistent results. We model the blur kernel as an anisotropic (elliptical) Gaussian kernel, specified by three parameters that control the strength, direction and aspect ratio of the blur.
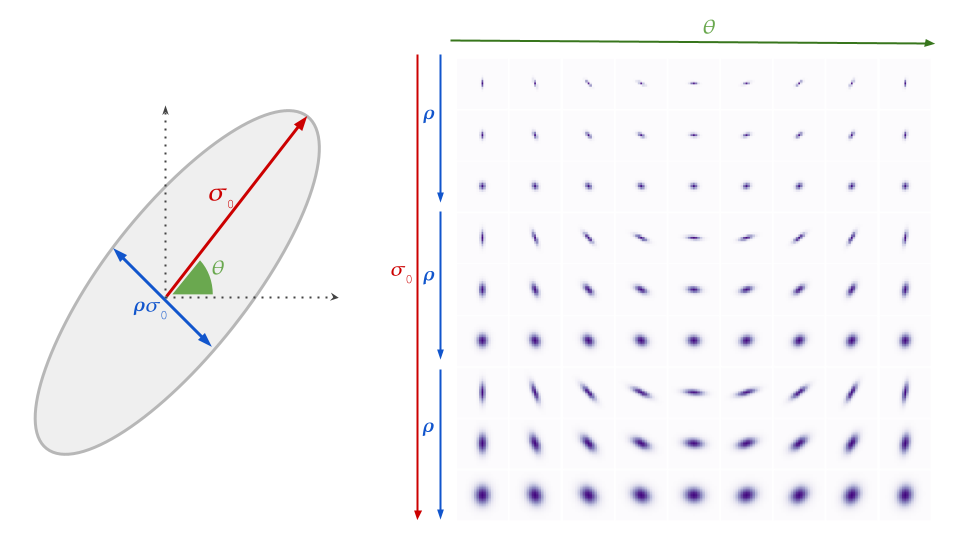 |
| Gaussian blur model and example blur kernels. Each row of the plot on the right represents possible combinations of σ0, ρ and θ. We show three different σ0 values with three different ρ values for each. |
Computing and removing blur without noticeable delay for the user requires an algorithm that is much more computationally efficient than existing approaches, which typically cannot be executed on a mobile device. We rely on an intriguing empirical observation: the maximal value of the image gradient across all directions at any point in a sharp image follows a particular distribution. Finding the maximum gradient value is efficient, and can yield a reliable estimate of the strength of the blur in the given direction. With this information in hand, we can directly recover the parameters that characterize the blur.
Polyblur: Removing Blur by Re-blurring
To recover the sharp image given the estimated blur, we would (in theory) need to solve a numerically unstable inverse problem (i.e., deblurring). The inversion problem grows exponentially more unstable with the strength of the blur. As such, we target the case of mild blur removal. That is, we assume that the image at hand is not so blurry as to be beyond practical repair. This enables a more practical approach — by carefully combining different re-applications of an operator we can approximate its inverse.
 |
 |
| Mild blur, as shown in these examples, can be effectively removed by combining multiple applications of the estimated blur. |
This means, rather counterintuitively, that we can deblur an image by re-blurring it several times with the estimated blur kernel. Each application of the (estimated) blur corresponds to a first order polynomial, and the repeated applications (adding or subtracting) correspond to higher order terms in a polynomial. A key aspect of this approach, which we call polyblur, is that it is very fast, because it only requires a few applications of the blur itself. This allows it to operate on megapixel images in a fraction of a second on a typical mobile device. The degree of the polynomial and its coefficients are set to invert the blur without boosting noise and other unwanted artifacts.
 |
| The deblurred image is generated by adding and subtracting multiple re-applications of the estimated blur (polyblur). |
Integration with Google Photos
The innovations described here have been integrated and made available to users in the Google Photos image editor in two new adjustment sliders called “Denoise” and “Sharpen”. These features allow users to improve the quality of everyday images, from any capture device. The features often complement each other, allowing both denoising to reduce unwanted artifacts, and sharpening to bring clarity to the image subjects. Try using this pair of tools in tandem in your images for best results. To learn more about the details of the work described here, check out our papers on polyblur and pull-push denoising. To see some examples of the effect of our denoising and sharpening up close, have a look at the images in this album.
Acknowledgements
The authors gratefully acknowledge the contributions of Ignacio Garcia-Dorado, Ryan Campbell, Damien Kelly, Peyman Milanfar, and John Isidoro. We are also thankful for support and feedback from Navin Sarma, Zachary Senzer, Brandon Ruffin, and Michael Milne.
1 The original pull-push algorithm was developed as an efficient scattered data interpolation method to estimate and fill in the missing pixels in an image where only a subset of the pixels are specified. Here, we extend its methodology and present a data-dependent multiscale algorithm for denoising images efficiently. ↩












{kind=link}