Everyday the web is used to share and store millions of pictures, enabling one to explore the world, research new topics of interest, or even share a vacation with friends and family. However, many of these images are either limited by the resolution of the device used to take the picture, or purposely degraded in order to accommodate the constraints of cell phones, tablets, or the networks to which they are connected. With the ubiquity of high-resolution displays for home and mobile devices, the demand for high-quality versions of low-resolution images, quickly viewable and shareable from a wide variety of devices, has never been greater.
With “RAISR: Rapid and Accurate Image Super-Resolution”, we introduce a technique that incorporates machine learning in order to produce high-quality versions of low-resolution images. RAISR produces results that are comparable to or better than the currently available super-resolution methods, and does so roughly 10 to 100 times faster, allowing it to be run on a typical mobile device in real-time. Furthermore, our technique is able to avoid recreating the aliasing artifacts that may exist in the lower resolution image.
Upsampling, the process of producing an image of larger size with significantly more pixels and higher image quality from a low quality image, has been around for quite a while. Well-known approaches to upsampling are linear methods which fill in new pixel values using simple, and fixed, combinations of the nearby existing pixel values. These methods are fast because they are fixed linear filters (a constant convolution kernel applied uniformly across the image). But what makes these upsampling methods fast, also makes them ineffective in bringing out vivid details in the higher resolution results. As you can see in the example below, the upsampled image looks blurry – one would hesitate to call it enhanced.
 |
| Left: Low-res original, Right: simple (bicubic) upsampled version (2x) |
With RAISR, we instead use machine learning and train on pairs of images, one low quality, one high, to find filters that, when applied to selectively to each pixel of the low-res image, will recreate details that are of comparable quality to the original. RAISR can be trained in two ways. The first is the "direct" method, where filters are learned directly from low and high-resolution image pairs. The other method involves first applying a computationally cheap upsampler to the low resolution image (as in the figure above) and then learning the filters from the upsampled and high resolution image pairs. While the direct method is computationally faster, the 2nd method allows for non-integer scale factors and better leveraging of hardware-based upsampling.
For either method, RAISR filters are trained according to edge features found in small patches of images, - brightness/color gradients, flat/textured regions, etc. - characterized by direction (the angle of an edge), strength (sharp edges have a greater strength) and coherence (a measure of how directional the edge is). Below is a set of RAISR filters, learned from a database of 10,000 high and low resolution image pairs (where the low-res images were first upsampled). The training process takes about an hour.
 |
| Collection of learned 11x11 filters for 3x super-resolution. Filters can be learned for a range of super-resolution factors, including fractional ones. Note that as the angle of the edge changes, we see the angle of the filter rotate as well. Similarly, as the strength increases, the sharpness of the filters increases, and the anisotropy of the filter increases with rising coherence. |
From left to right, we see that the learned filters correspond selectively to the direction of the underlying edge that is being reconstructed. For example, the filter in the middle of the bottom row is most appropriate for a strong horizontal edge (gradient angle of 90 degrees) with a high degree of coherence (a straight, rather than a curved, edge). If this same horizontal edge is low-contrast, then a different filter is selected such one in the top row.
In practice, at run-time RAISR selects and applies the most relevant filter from the list of learned filters to each pixel neighborhood in the low-resolution image. When these filters are applied to the lower quality image, they recreate details that are of comparable quality to the original high resolution, and offer a significant improvement to linear, bicubic, or Lanczos interpolation methods.
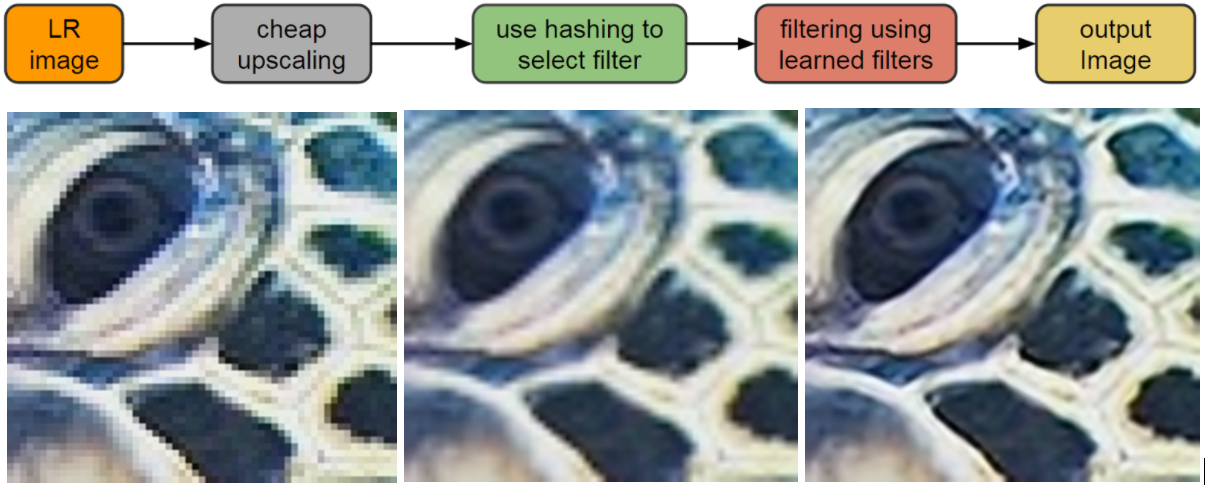 |
| Top: RAISR algorithm at run-time, applied to a cheap upscaler’s output. Bottom: Low-res original (left), bicubic upsampler 2x (middle), RAISR output (right) |
Some examples of RAISR in action can be seen below:
 |
| Top: Original, Bottom: RAISR super-resolved 2x |
 |
| Left: Original, Right: RAISR super-resolved 3x |
One of the more complex aspects of super-resolution is getting rid of aliasing artifacts such as Moire patterns and jaggies that arise when high frequency content is rendered in lower resolution (as is the case when images are purposefully degraded). Depending on the shape of the underlying features, these artifacts can be varied and hard to undo.
 |
| Example of aliasing artifacts seen on the lower right (Image source) |
{kind=link}
Linear methods simply can not recover the underlying structure, but RAISR can. Below is an example where the aliased spatial frequencies are apparent under the numbers 3 and 5 in the low-resolution original on the left, while the RAISR image on the right recovered the original structure. Another important advantage of the filter learning approach used by RAISR is that we can specialize it to remove noise, or compression artifacts unique to individual compression algorithms (such as JPEG) as part of the training process. By providing it with examples of such artifacts, RAISR can learn to undo other effects besides resolution enhancement, having them “baked” inside the resulting filters.
 |
| Left: Low res original, with strong aliasing. Right: RAISR output, removing aliasing. |
Super-resolution technology, using one or many frames, has come a long way. Today, the use of machine learning, in tandem with decades of advances in imaging technology, has enabled progress in image processing that yields many potential benefits. For example, in addition to improving digital “pinch to zoom” on your phone, one could capture, save, or transmit images at lower resolution and super-resolve on demand without any visible degradation in quality, all while utilizing less of mobile data and storage plans.
To learn more about the details of our research and a comparison to other current architectures, check out our paper, which will appear soon in the IEEE Transactions on Computational Imaging.
