 Posted by Avneet Singh, Product Manager and Sisi Jin, UX Designer, Google PI, and Lance Carr, Collaborator
Posted by Avneet Singh, Product Manager and Sisi Jin, UX Designer, Google PI, and Lance Carr, Collaborator
At I/O 2023, Google launched Project Gameface, an open-source, hands-free gaming ‘mouse’ enabling people to control a computer's cursor using their head movement and facial gestures. People can raise their eyebrows to click and drag, or open their mouth to move the cursor, making gaming more accessible.
The project was inspired by the story of quadriplegic video game streamer Lance Carr, who lives with muscular dystrophy, a progressive disease that weakens muscles. And we collaborated with Lance to bring Project Gameface to life. The full story behind the product is available on the Google Keyword blog here.
It’s been an extremely interesting experience to think about how a mouse cursor can be controlled in such a novel way. We conducted many experiments and found head movement and facial expressions can be a unique way to program the mouse cursor. MediaPipe’s new Face Landmarks Detection API with blendshape option made this possible as it allows any developer to leverage 478 3-dimensional face landmarks and 52 blendshape scores (coefficients representing facial expression) to infer detailed facial surfaces in real-time.
Product Construct and Details
In this article, we share technical details of how we built Project Gamefaceand the various open source technologies we leveraged to create the exciting product!
Using head movement to move the mouse cursor
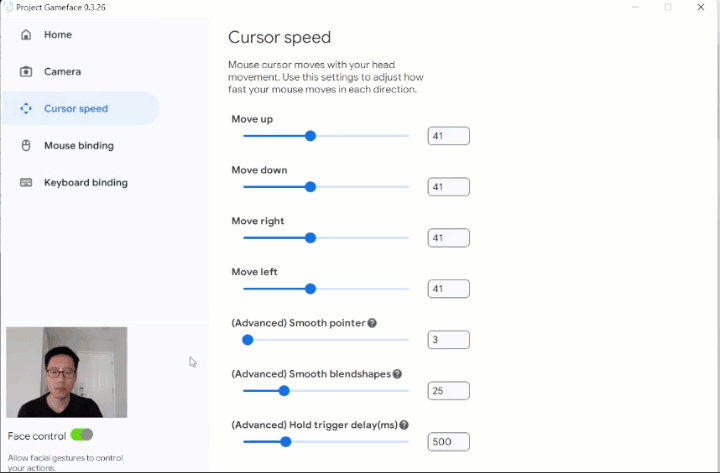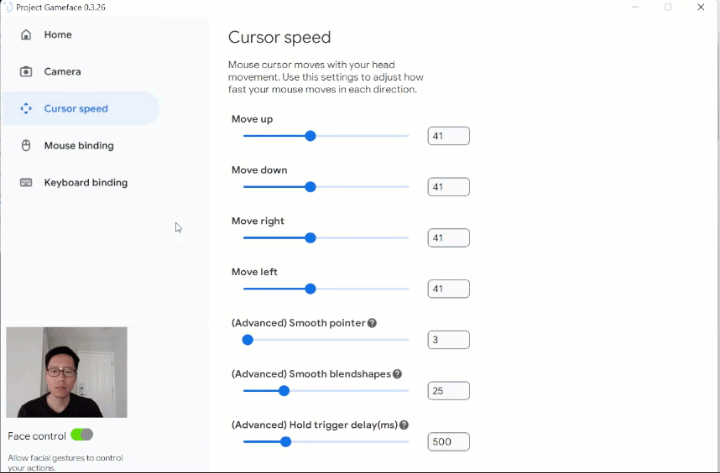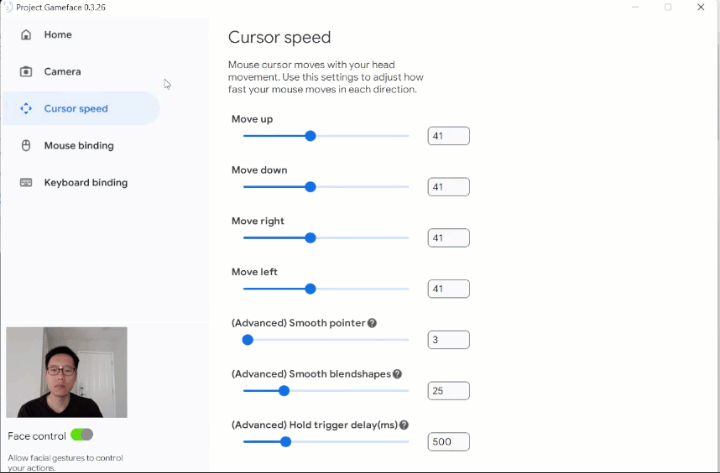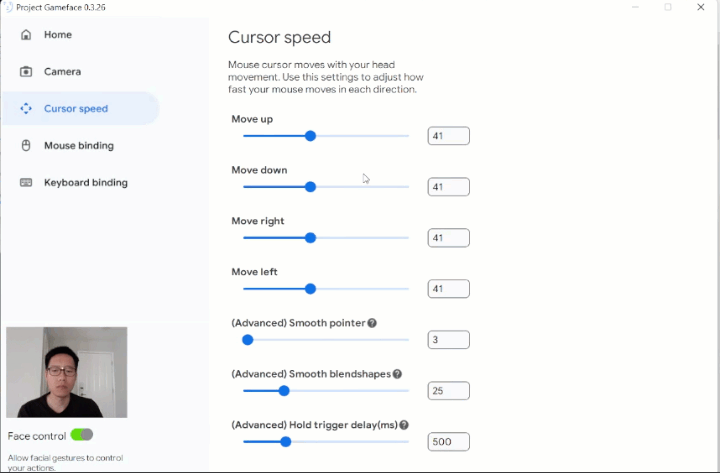 |
| Caption: Controlling head movement to move mouse cursors and customizing cursor speed to adapt to different screen resolutions. |
Through this project, we explored the concept of using the head movement to be able to move the mouse cursor. We focused on the forehead and iris as our two landmark locations. Both forehead and iris landmarks are known for their stability. However, Lance noticed that the cursor didn't work well while using the iris landmark. The reason was that the iris may move slightly when people blink, causing the cursor to move unintendedly. Therefore, we decided to use the forehead landmark as a default tracking option.
There are instances where people may encounter challenges when moving their head in certain directions. For example, Lance can move his head more quickly to the right than left. To address this issue, we introduced a user-friendly solution: separate cursor speed adjustment for each direction. This feature allows people to customize the cursor's movement according to their preferences, facilitating smoother and more comfortable navigation.
We wanted the experience to be as smooth as a hand held controller. Jitteriness of the mouse cursor is one of the major problems we wanted to overcome. The appearance of cursor jittering is influenced by various factors, including the user setup, camera, noise, and lighting conditions. We implemented an adjustable cursor smoothing feature to allow users the convenience of easily fine-tuning this feature to best suit their specific setup.
Using facial expressions to perform mouse actions and keyboard press
Very early on, one of our primary insights was that people have varying comfort levels making different facial expressions. A gesture that comes easily to one user may be extremely difficult for another to do deliberately. For instance, Lance can move his eyebrows independently with ease while the rest of the team struggled to match Lance’s skill. Hence, we decided to create a functionality for people to customize which expressions they used to control the mouse.
 |
| Caption: Using facial expressions to control mouse |
Think of it as a custom binding of a gesture to a mouse action. When deliberating about which mouse actions should the product cover, we tried to capture common scenarios such as left and right click to scrolling up and down. However, using the head to control mouse cursor movement is a different experience than the conventional manner. We wanted to give the users the option to reset the mouse cursor to the center of the screen using a facial gesture too.
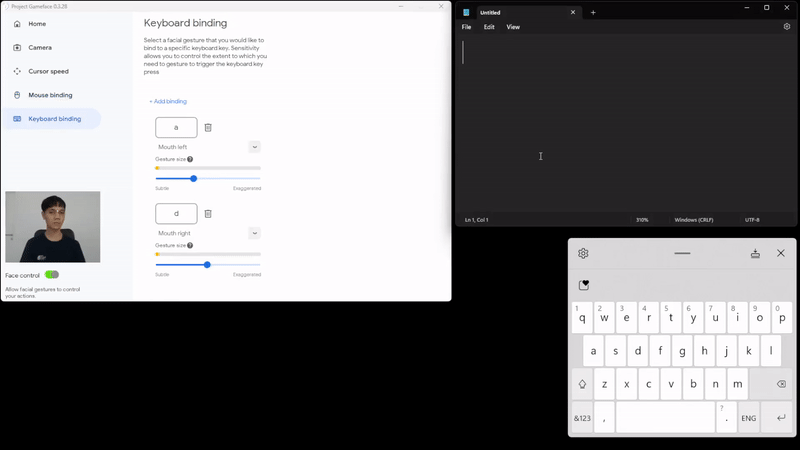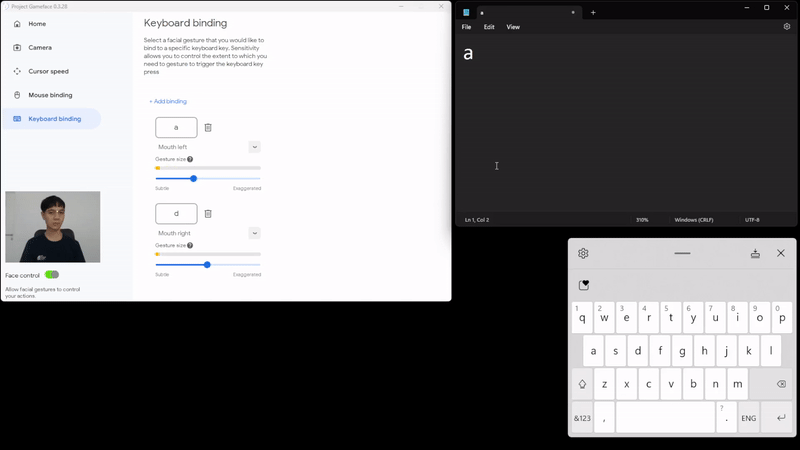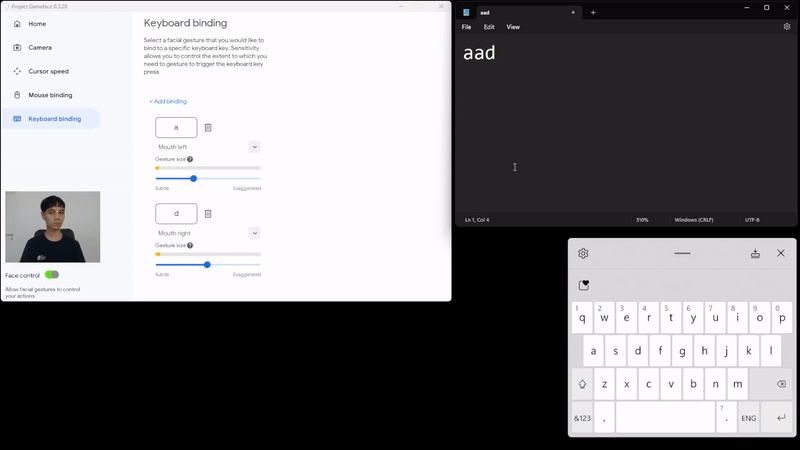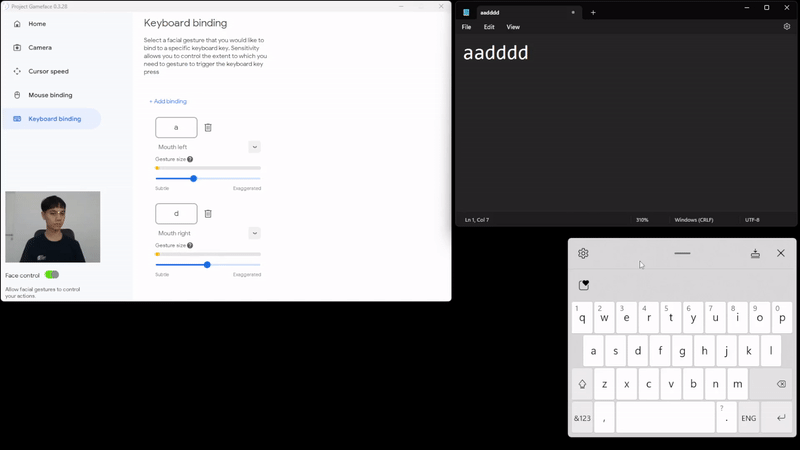 |
| Caption: Using facial expressions to control keyboard |
The most recent release of MediaPipe Face Landmarks Detection brings an exciting addition: blendshapes output. With this enhancement, the API generates 52 face blendshape values which represent the expressiveness of 52 facial gestures such as raising left eyebrow or mouth opening. These values can be effectively mapped to control a wide range of functions, offering users expanded possibilities for customization and manipulation.
We’ve been able to extend the same functionality and add the option for keyboard binding too. This helps use their facial gestures to also press some keyboard keys in a similar binding fashion.
Set Gesture Size to see when to trigger a mouse/keyboard action
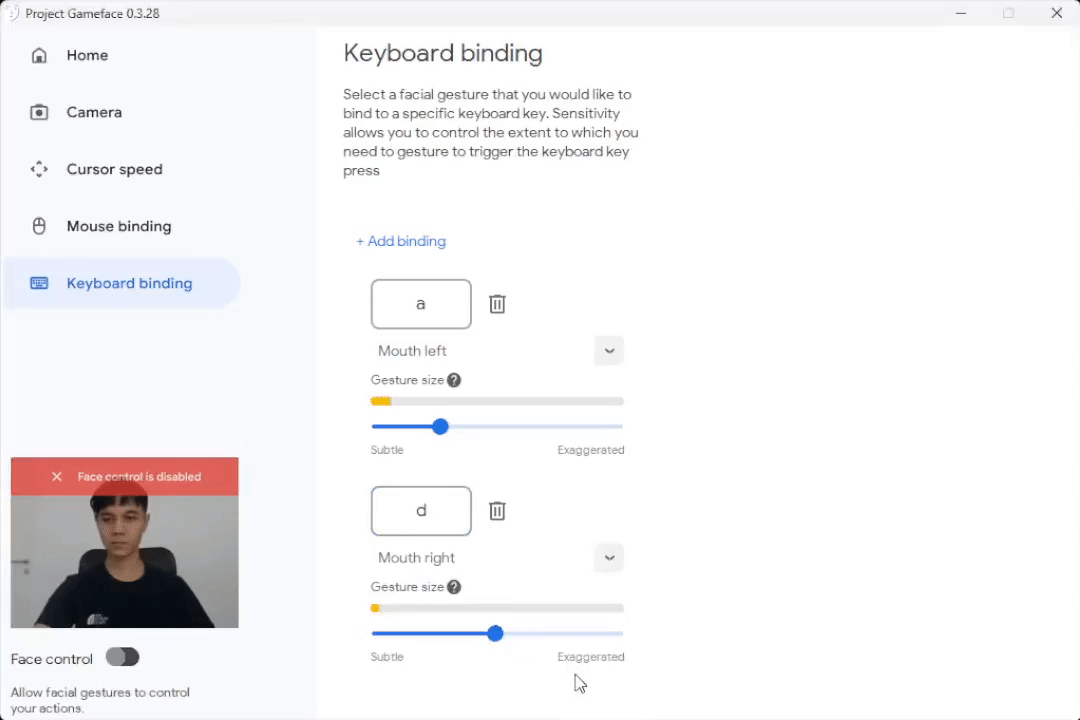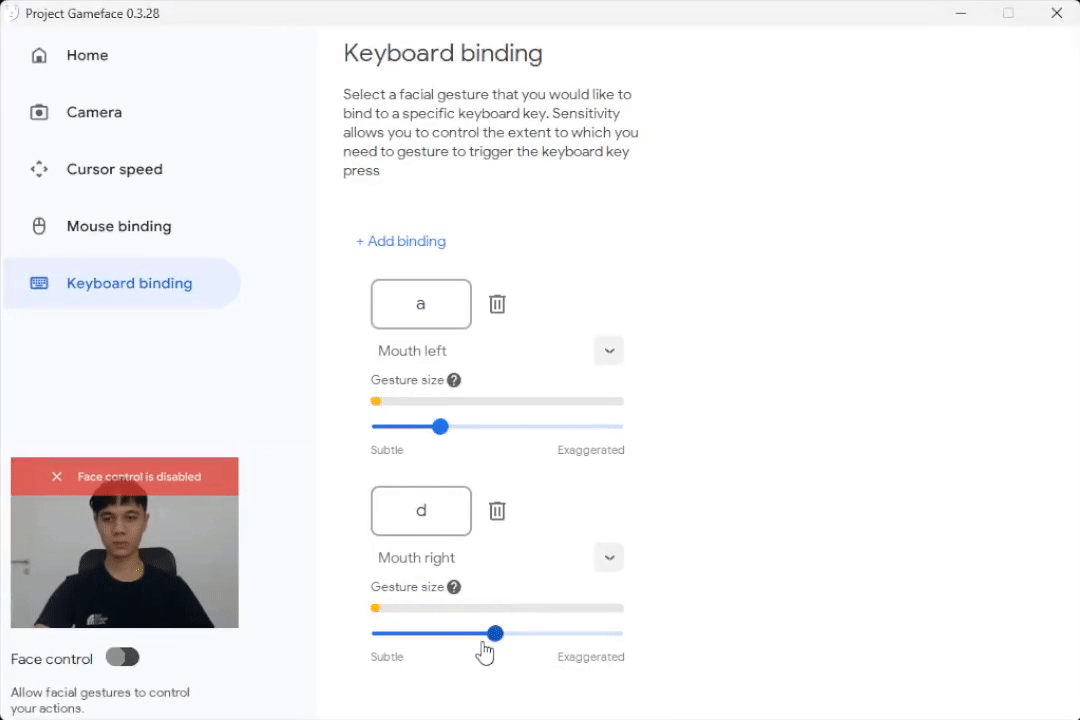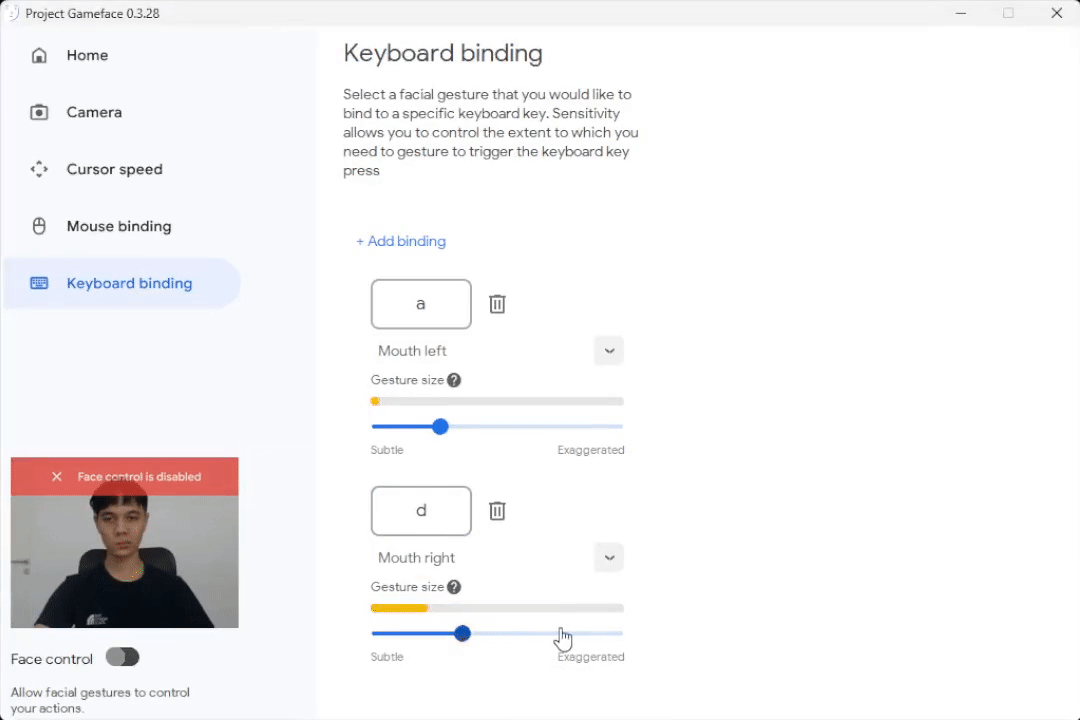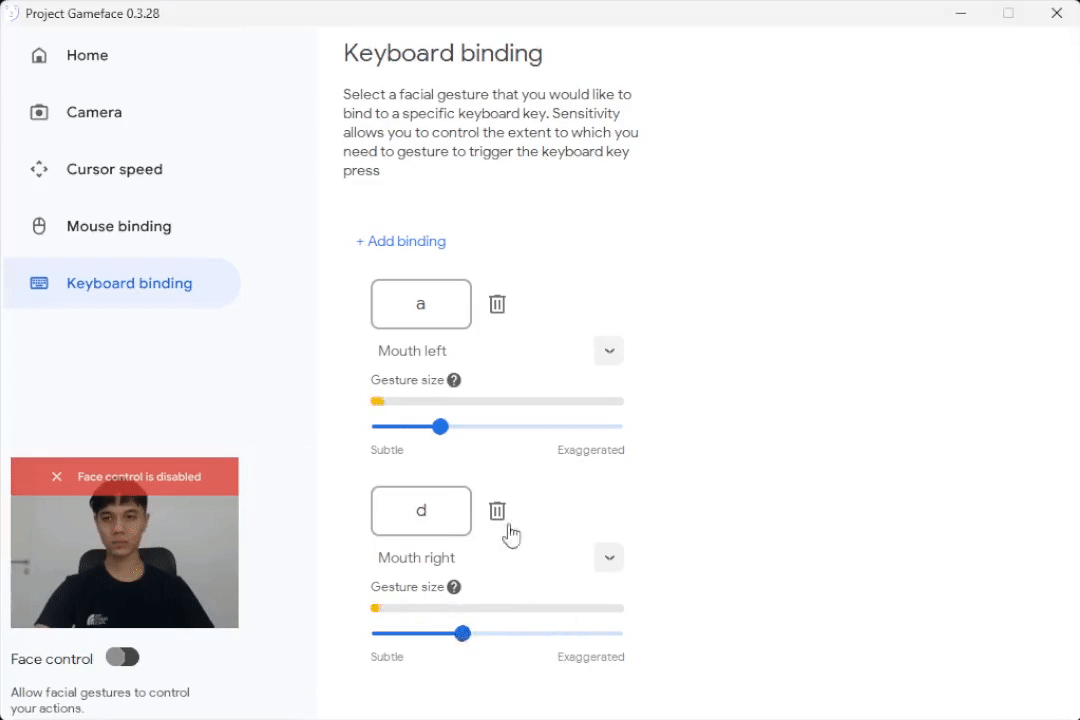 |
| Caption: Set the gesture size to trigger an action |
While testing the software, we found that facial expressions were more or less pronounced by each of us, so we’ve incorporated the idea of a gesture size, which allows people to control the extent to which they need to gesture to trigger a mouse action. Blendshapes coefficients were helpful here and different users can now set different thresholds on each specific expression and this helps them customize the experience to their comfort.
Keeping the camera feed available
Another key insight we received from Lance was gamers often have multiple cameras. For our machine learning models to operate optimally, it’s best to have a camera pointing straight to the user’s face with decent lighting. So we’ve incorporated the ability for the user to select the correct camera to help frame them and give the most optimal performance.
Our product's user interface incorporates a live camera feed, providing users with real-time visibility of their head movements and gestures. This feature brings several advantages. Firstly, users can set thresholds more effectively by directly observing their own movements. The visual representation enables informed decisions on appropriate threshold values. Moreover, the live camera feed enhances users' understanding of different gestures as they visually correlate their movements with the corresponding actions in the application. Overall, the camera feed significantly enhances the user experience, facilitating accurate threshold settings and a deeper comprehension of gestures.
Product Packaging
Our next step was to create the ability to control the mouse and keyboard using our custom defined logic. To enable mouse and keyboard control within our Python application, we utilize two libraries: PyAutoGUI for mouse control and PyDirectInput for keyboard control. PyAutoGUI is chosen for its robust mouse control capabilities, allowing us to simulate mouse movements, clicks, and other actions. On the other hand, we leverage PyDirectInput for keyboard control as it offers enhanced compatibility with various applications, including games and those relying on DirectX.
For our application packaging, we used PyInstaller to turn our Python-based application into an executable, making it easier for users to run our software without the need for installing Python or additional dependencies. PyInstaller provides a reliable and efficient means to distribute our application, ensuring a smooth user experience.
The product introduces a novel form factor to engage users in an important function like handling the mouse cursor. Making the product and its UI intuitive and easy to follow was a top priority for our design and engineering team. We worked closely with Lance to incorporate his feedback into our UX considerations, and we found CustomtKinter was able to handle most of our UI considerations in Python.
We’re excited to see the potential of Project GameFace and can’t wait for developers and enterprises to leverage it to build new experiences. The code for GameFace is open sourced on Github here.
Acknowledgements
We would like to acknowledge the invaluable contributions of the following people to this project: Lance Carr, David Hewlett, Laurence Moroney, Khanh LeViet, Glenn Cameron, Edwina Priest, Joe Fry, Feihong Chen, Boon Panichprecha, Dome Seelapun, Kim Nomrak, Pear Jaionnom, Lloyd Hightower
 Posted by Yiling Liu, Product Manager, Google Partner Innovation
Posted by Yiling Liu, Product Manager, Google Partner Innovation