For more than a decade, memory safety vulnerabilities have consistently represented more than 65% of vulnerabilities across products, and across the industry. On Android, we’re now seeing something different - a significant drop in memory safety vulnerabilities and an associated drop in the severity of our vulnerabilities.
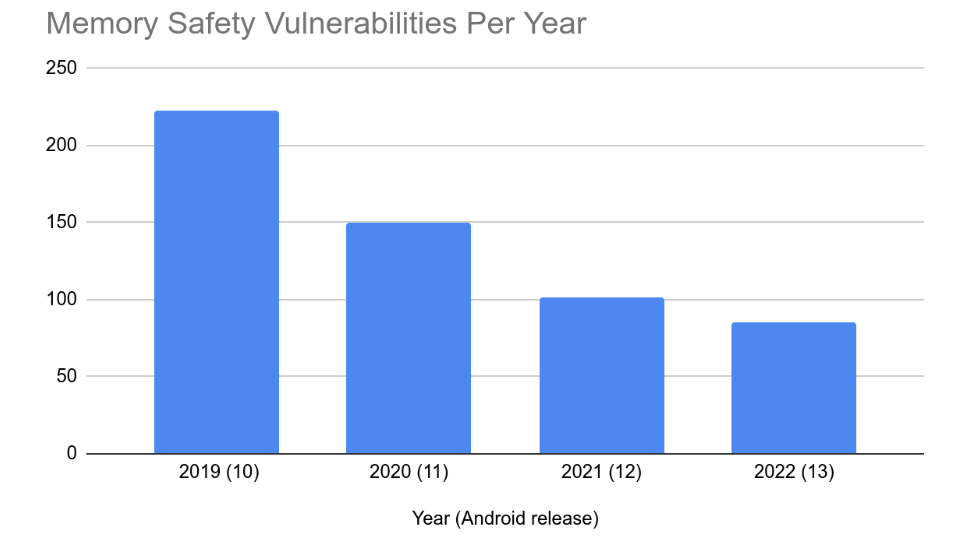
Looking at vulnerabilities reported in the Android security bulletin, which includes critical/high severity vulnerabilities reported through our vulnerability rewards program (VRP) and vulnerabilities reported internally, we see that the number of memory safety vulnerabilities have dropped considerably over the past few years/releases. From 2019 to 2022 the annual number of memory safety vulnerabilities dropped from 223 down to 85.
This drop coincides with a shift in programming language usage away from memory unsafe languages. Android 13 is the first Android release where a majority of new code added to the release is in a memory safe language.

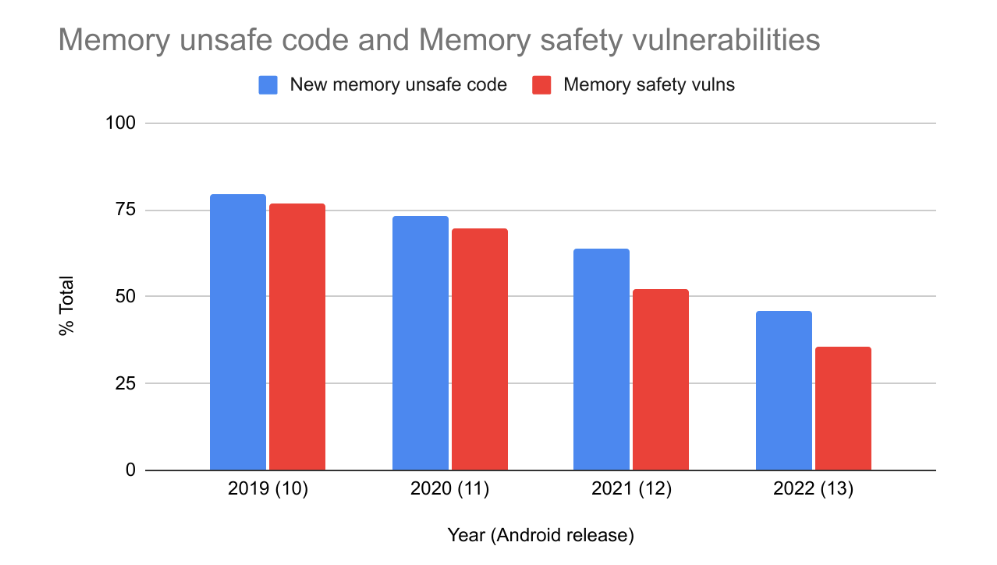
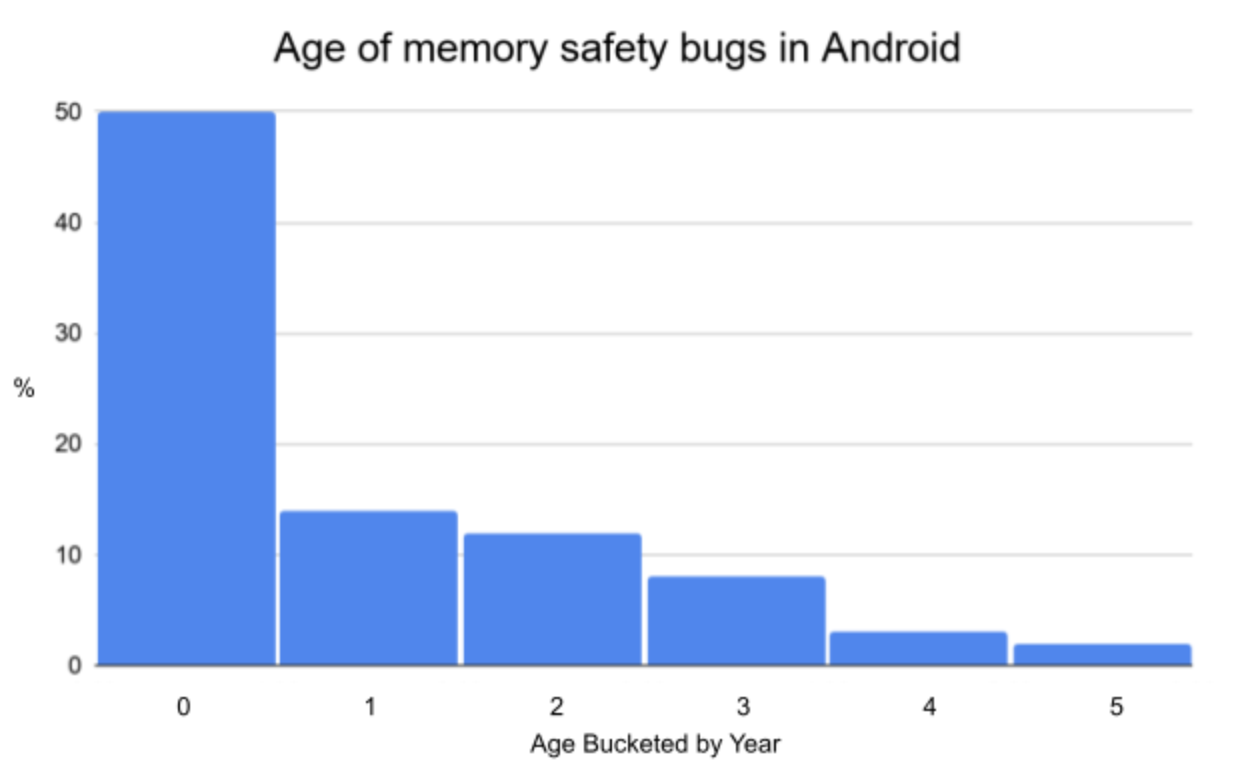
While correlation doesn’t necessarily mean causation, it’s interesting to note that the percent of vulnerabilities caused by memory safety issues seems to correlate rather closely with the development language that’s used for new code. This matches the expectations published in our blog post 2 years ago about the age of memory safety vulnerabilities and why our focus should be on new code, not rewriting existing components. Of course there may be other contributing factors or alternative explanations. However, the shift is a major departure from industry-wide trends that have persisted for more than a decade (and likely longer) despite substantial investments in improvements to memory unsafe languages.
We continue to invest in tools to improve the safety of our C/C++. Over the past few releases we’ve introduced the Scudo hardened allocator, HWASAN, GWP-ASAN, and KFENCE on production Android devices. We’ve also increased our fuzzing coverage on our existing code base. Vulnerabilities found using these tools contributed both to prevention of vulnerabilities in new code as well as vulnerabilities found in old code that are included in the above evaluation. These are important tools, and critically important for our C/C++ code. However, these alone do not account for the large shift in vulnerabilities that we’re seeing, and other projects that have deployed these technologies have not seen a major shift in their vulnerability composition. We believe Android’s ongoing shift from memory-unsafe to memory-safe languages is a major factor.
Rust for Native Code
In Android 12 we announced support for the Rust programming language in the Android platform as a memory-safe alternative to C/C++. Since then we’ve been scaling up our Rust experience and usage within the Android Open Source Project (AOSP).
As we noted in the original announcement, our goal is not to convert existing C/C++ to Rust, but rather to shift development of new code to memory safe languages over time.

In Android 13, about 21% of all new native code (C/C++/Rust) is in Rust. There are approximately 1.5 million total lines of Rust code in AOSP across new functionality and components such as Keystore2, the new Ultra-wideband (UWB) stack, DNS-over-HTTP3, Android’s Virtualization framework (AVF), and various other components and their open source dependencies. These are low-level components that require a systems language which otherwise would have been implemented in C++.
Security impact
To date, there have been zero memory safety vulnerabilities discovered in Android’s Rust code.
We don’t expect that number to stay zero forever, but given the volume of new Rust code across two Android releases, and the security-sensitive components where it’s being used, it’s a significant result. It demonstrates that Rust is fulfilling its intended purpose of preventing Android’s most common source of vulnerabilities. Historical vulnerability density is greater than 1/kLOC (1 vulnerability per thousand lines of code) in many of Android’s C/C++ components (e.g. media, Bluetooth, NFC, etc). Based on this historical vulnerability density, it’s likely that using Rust has already prevented hundreds of vulnerabilities from reaching production.
What about unsafe Rust?
Operating system development requires accessing resources that the compiler cannot reason about. For memory-safe languages this means that an escape hatch is required to do systems programming. For Java, Android uses JNI to access low-level resources. When using JNI, care must be taken to avoid introducing unsafe behavior. Fortunately, it has proven significantly simpler to review small snippets of C/C++ for safety than entire programs. There are no pure Java processes in Android. It’s all built on top of JNI. Despite that, memory safety vulnerabilities are exceptionally rare in our Java code.
Rust likewise has the unsafe{} escape hatch which allows interacting with system resources and non-Rust code. Much like with Java + JNI, using this escape hatch comes with additional scrutiny. But like Java, our Rust code is proving to be significantly safer than pure C/C++ implementations. Let’s look at the new UWB stack as an example.
There are exactly two uses of unsafe in the UWB code: one to materialize a reference to a Rust object stored inside a Java object, and another for the teardown of the same. Unsafe was actively helpful in this situation because the extra attention on this code allowed us to discover a possible race condition and guard against it.
In general, use of unsafe in Android’s Rust appears to be working as intended. It’s used rarely, and when it is used, it’s encapsulating behavior that’s easier to reason about and review for safety.
Safety measures make memory-unsafe languages slow
Mobile devices have limited resources and we’re always trying to make better use of them to provide users with a better experience (for example, by optimizing performance, improving battery life, and reducing lag). Using memory unsafe code often means that we have to make tradeoffs between security and performance, such as adding additional sandboxing, sanitizers, runtime mitigations, and hardware protections. Unfortunately, these all negatively impact code size, memory, and performance.
Using Rust in Android allows us to optimize both security and system health with fewer compromises. For example, with the new UWB stack we were able to save several megabytes of memory and avoid some IPC latency by running it within an existing process. The new DNS-over-HTTP/3 implementation uses fewer threads to perform the same amount of work by using Rust’s async/await feature to process many tasks on a single thread in a safe manner.
What about non-memory-safety vulnerabilities?
The number of vulnerabilities reported in the bulletin has stayed somewhat steady over the past 4 years at around 20 per month, even as the number of memory safety vulnerabilities has gone down significantly. So, what gives? A few thoughts on that.
A drop in severity
Memory safety vulnerabilities disproportionately represent our most severe vulnerabilities. In 2022, despite only representing 36% of vulnerabilities in the security bulletin, memory-safety vulnerabilities accounted for 86% of our critical severity security vulnerabilities, our highest rating, and 89% of our remotely exploitable vulnerabilities. Over the past few years, memory safety vulnerabilities have accounted for 78% of confirmed exploited “in-the-wild” vulnerabilities on Android devices.

Many vulnerabilities have a well defined scope of impact. For example, a permissions bypass vulnerability generally grants access to a specific set of information or resources and is generally only reachable if code is already running on the device. Memory safety vulnerabilities tend to be much more versatile. Getting code execution in a process grants access not just to a specific resource, but everything that that process has access to, including attack surface to other processes. Memory safety vulnerabilities are often flexible enough to allow chaining multiple vulnerabilities together. The high versatility is perhaps one reason why the vast majority of exploit chains that we have seen use one or more memory safety vulnerabilities.
With the drop in memory safety vulnerabilities, we’re seeing a corresponding drop in vulnerability severity.

With the decrease in our most severe vulnerabilities, we’re seeing increased reports of less severe vulnerability types. For example, about 15% of vulnerabilities in 2022 are DoS vulnerabilities (requiring a factory reset of the device). This represents a drop in security risk.
Android appreciates our security research community and all contributions made to the Android VRP. We apply higher payouts for more severe vulnerabilities to ensure that incentives are aligned with vulnerability risk. As we make it harder to find and exploit memory safety vulnerabilities, security researchers are pivoting their focus towards other vulnerability types. Perhaps the total number of vulnerabilities found is primarily constrained by the total researcher time devoted to finding them. Or perhaps there’s another explanation that we have not considered. In any case, we hope that if our vulnerability researcher community is finding fewer of these powerful and versatile vulnerabilities, the same applies to adversaries.
Attack surface
Despite most of the existing code in Android being in C/C++, most of Android’s API surface is implemented in Java. This means that Java is disproportionately represented in the OS’s attack surface that is reachable by apps. This provides an important security property: most of the attack surface that’s reachable by apps isn’t susceptible to memory corruption bugs. It also means that we would expect Java to be over-represented when looking at non-memory safety vulnerabilities. It’s important to note however that types of vulnerabilities that we’re seeing in Java are largely logic bugs, and as mentioned above, generally lower in severity. Going forward, we will be exploring how Rust’s richer type system can help prevent common types of logic bugs as well.
Google’s ability to react
With the vulnerability types we’re seeing now, Google’s ability to detect and prevent misuse is considerably better. Apps are scanned to help detect misuse of APIs before being published on the Play store and Google Play Protect warns users if they have abusive apps installed.
What’s next?
Migrating away from C/C++ is challenging, but we’re making progress. Rust use is growing in the Android platform, but that’s not the end of the story. To meet the goals of improving security, stability, and quality Android-wide, we need to be able to use Rust anywhere in the codebase that native code is required. We’re implementing userspace HALs in Rust. We’re adding support for Rust in Trusted Applications. We’ve migrated VM firmware in the Android Virtualization Framework to Rust. With support for Rust landing in Linux 6.1 we’re excited to bring memory-safety to the kernel, starting with kernel drivers.
As Android migrates away from C/C++ to Java/Kotlin/Rust, we expect the number of memory safety vulnerabilities to continue to fall. Here’s to a future where memory corruption bugs on Android are rare!