Posted by Zizhao Zhang, Software Engineer, Google Research, Cloud AI Team In visual understanding, the Visual Transformer (ViT) and its variants have received significant attention recently due to their superior performance on many core visual applications, such as image classification, object detection, and video understanding. The core idea of ViT is to utilize the power of self-attention layers to learn global relationships between small patches of images. However, the number of connections between patches increases quadratically with image size. Such a design has been observed to be data inefficient — although the original ViT can perform better than convolutional networks with hundreds of millions of images for pre-training, such a data requirement is not always practical, and it still underperforms compared to convolutional networks when given less data. Many are exploring to find more suitable architectural re-designs that can learn visual representations effectively, such as by adding convolutional layers and building hierarchical structures with local self-attention.
The principle of hierarchical structure is one of the core ideas in vision models, where bottom layers learn more local object structures on the high-dimensional pixel space and top layers learn more abstracted and high-level knowledge at low-dimensional feature space. Existing ViT-based methods focus on designing a variety of modifications inside self-attention layers to achieve such a hierarchy, but while these offer promising performance improvements, they often require substantial architectural re-designs. Moreover, these approaches lack an interpretable design, so it is difficult to explain the inner-workings of trained models.
To address these challenges, in “Nested Hierarchical Transformer: Towards Accurate, Data-Efficient and Interpretable Visual Understanding”, we present a rethinking of existing hierarchical structure–driven designs, and provide a novel and orthogonal approach to significantly simplify them. The central idea of this work is to decouple feature learning and feature abstraction (pooling) components: nested transformer layers encode visual knowledge of image patches separately, and then the processed information is aggregated. This process is repeated in a hierarchical manner, resulting in a pyramid network structure. The resulting architecture achieves competitive results on ImageNet and outperforms results on data-efficient benchmarks. We have shown such a design can meaningfully improve data efficiency with faster convergence and provide valuable interpretability benefits. Moreover, we introduce GradCAT, a new technique for interpreting the decision process of a trained model at inference time.
Architecture Design
The overall architecture is simple to implement by adding just a few lines of Python code to the source code of the original ViT. The original ViT architecture divides an input image into small patches, projects pixels of each patch to a vector with predefined dimension, and then feeds the sequences of all vectors to the overall ViT architecture containing multiple stacked identical transformer layers. While every layer in ViT processes information of the whole image, with this new method, stacked transformer layers are used to process only a region (i.e., block) of the image containing a few spatially adjacent image patches. This step is independent for each block and is also where feature learning occurs. Finally, a new computational layer called block aggregation then combines all of the spatially adjacent blocks. After each block aggregation, the features corresponding to four spatially adjacent blocks are fed to another module with a stack of transformer layers, which then process those four blocks jointly. This design naturally builds a pyramid hierarchical structure of the network, where bottom layers can focus on local features (such as textures) and upper layers focus on global features (such as object shape) at reduced dimensionality thanks to the block aggregation.
 |
| A visualization of the network processing an image: Given an input image, the network first partitions images into blocks, where each block contains 4 image patches. Image patches in every block are linearly projected as vectors and processed by a stack of identical transformer layers. Then the proposed block aggregation layer aggregates information from each block and reduces its spatial size by 4 times. The number of blocks is reduced to 1 at the top hierarchy and classification is conducted after the output of it. |
Interpretability
This architecture has a non-overlapping information processing mechanism, independent at every node. This design resembles a decision tree-like structure, which manifests unique interpretability capabilities because every tree node contains independent information of an image block that is being received by its parent nodes. We can trace the information flow through the nodes to understand the importance of each feature. In addition, our hierarchical structure retains the spatial structure of images throughout the network, leading to learned spatial feature maps that are effective for interpretation. Below we showcase two kinds of visual interpretability.
First, we present a method to interpret the trained model on test images, called gradient-based class-aware tree-traversal (GradCAT). GradCAT traces the feature importance of each block (a tree node) from top to bottom of the hierarchy structure. The main idea is to find the most valuable traversal from the root node at the top layer to a child node at the bottom layer that contributes the most to the classification outcomes. Since each node processes information from a certain region of the image, such traversal can be easily mapped to the image space for interpretation (as shown by the overlaid dots and lines in the image below).
The following is an example of the model's top-4 predictions and corresponding interpretability results on the left input image (containing 4 animals). As shown below, GradCAT highlights the decision path along the hierarchical structure as well as the corresponding visual cues in local image regions on the images.
 |
| Given the left input image (containing four objects), the figure visualizes the interpretability results of the top-4 prediction classes. The traversal locates the model decision path along the tree and simultaneously locates the corresponding image patch (shown by the dotted line on images) that has the highest impact to the predicted target class. |
Moreover, the following figures visualize results on the ImageNet validation set and show how this approach enables some intuitive observations. For instance, the example of the lighter below (upper left panel) is particularly interesting because the ground truth class — lighter/matchstick — actually defines the bottom-right matchstick object, while the most salient visual features (with the highest node values) are actually from the upper-left red light, which conceptually shares visual cues with a lighter. This can also be seen from the overlaid red lines, which indicate the image patches with the highest impact on the prediction. Thus, although the visual cue is a mistake, the output prediction is correct. In addition, the four child nodes of the wooden spoon below have similar feature importance values (see numbers visualized in the nodes; higher indicates more importance), which is because the wooden texture of the table is similar to that of the spoon.
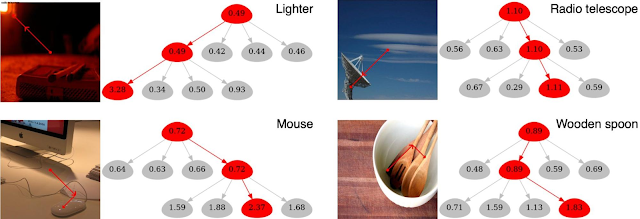 |
| Visualization of the results obtained by the proposed GradCAT. Images are from the ImageNet validation dataset. |
Second, different from the original ViT, our hierarchical architecture retains spatial relationships in learned representations. The top layers output low-resolution features maps of input images, enabling the model to easily perform attention-based interpretation by applying Class Attention Map (CAM) on the learned representations at the top hierarchical level. This enables high-quality weakly-supervised object localization with just image-level labels. See the following figure for examples.
 |
| Visualization of CAM-based attention results. Warmer colors indicate higher attention. Images are from the ImageNet validation dataset. |
Convergence Advantages
With this design, feature learning only happens at local regions independently, and feature abstraction happens inside the aggregation function. This design and simple implementation is general enough for other types of visual understanding tasks beyond classification. It also improves the model convergence speed greatly, significantly reducing the training time to reach the desired maximum accuracy.
We validate this advantage in two ways. First, we compare the ViT structure on the ImageNet accuracy with a different number of total training epochs. The results are shown on the left side of the figure below, demonstrating much faster convergence than the original ViT, e.g., around 20% improvement in accuracy over ViT with 30 total training epochs.
Second, we modify the architecture to conduct unconditional image generation tasks, since training ViT-based models for image generation tasks is challenging due to convergence and speed issues. Creating such a generator is straightforward by transposing the proposed architecture: the input is an embedding vector, the output is a full image in RGB channels, and the block aggregation is replaced by a block de-aggregation component supported by Pixel Shuffling. Surprisingly, we find our generator is easy to train and demonstrates faster convergence speed, as well as better FID score (which measures how similar generated images are to real ones), than the capacity-comparable SAGAN.
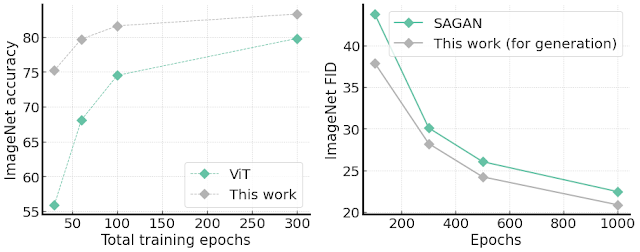 |
| Left: ImageNet accuracy given different number of total training epochs compared with standard ViT architecture. Right: ImageNet 64x64 image generation FID scores (lower is better) with single 1000-epoch training. On both tasks, our method shows better convergence speed. |
Conclusion
In this work we demonstrate the simple idea that decoupled feature learning and feature information extraction in this nested hierarchy design leads to better feature interpretability through a new gradient-based class-aware tree traversal method. Moreover, the architecture improves convergence on not only classification tasks but also image generation tasks. The proposed idea is focusing on aggregation function and thereby is orthogonal to advanced architecture design for self-attention. We hope this new research encourages future architecture designers to explore more interpretable and data-efficient ViT-based models for visual understanding, like the adoption of this work for high-resolution image generation. We have also released the source code for the image classification portion of this work.
Acknowledgements
We gratefully acknowledge the contributions of other co-authors, including Han Zhang, Long Zhao, Ting Chen, Sercan Arik, Tomas Pfister. We also thank Xiaohua Zhai, Jeremy Kubica, Kihyuk Sohn, and Madeleine Udell for the valuable feedback of the work.