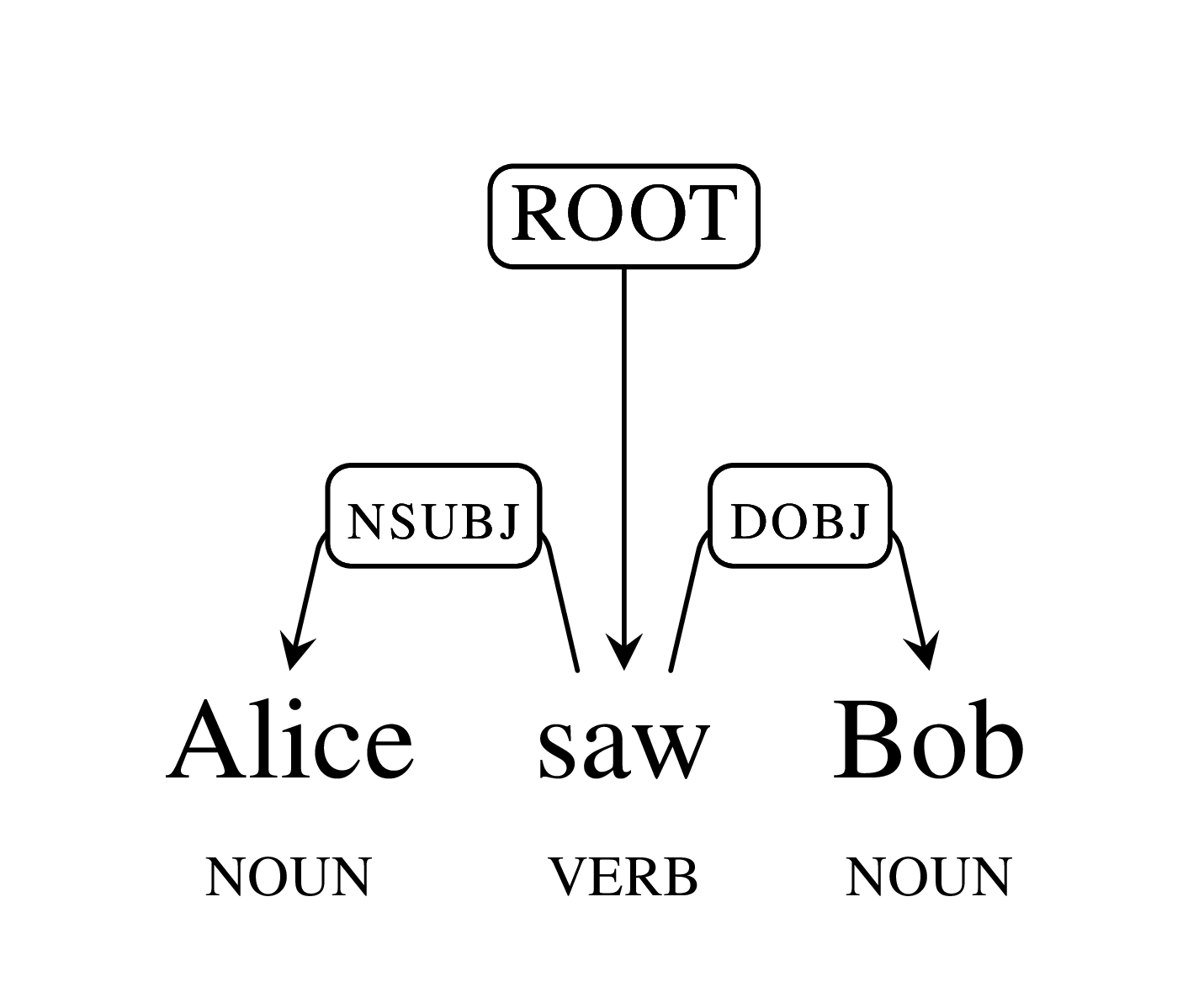
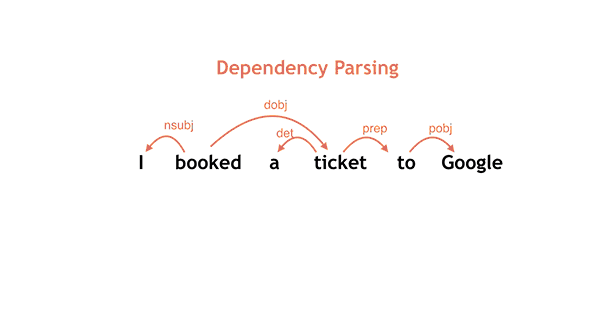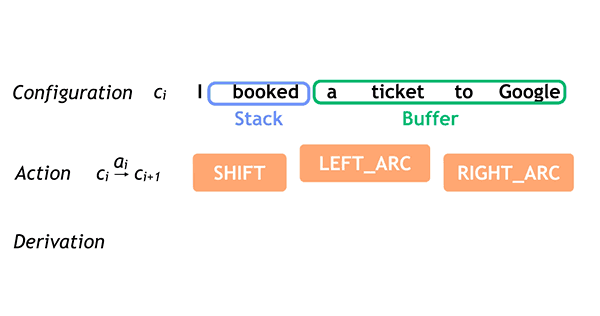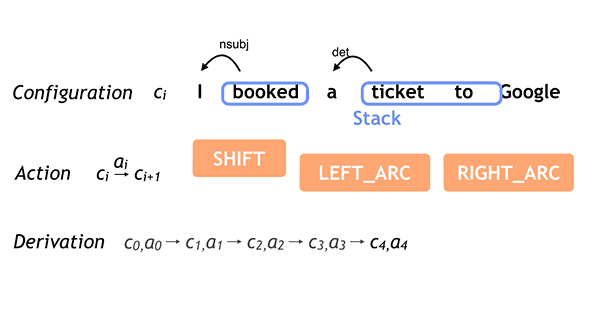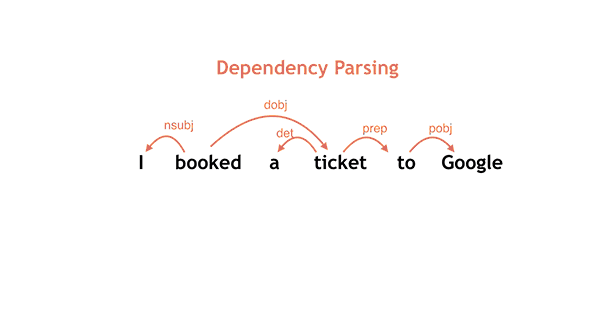
Just in time for ACL 2016, we are pleased to announce that Parsey McParseface, released in May as part of SyntaxNet and the basis for the Cloud Natural Language API, now has 40 cousins! Parsey’s Cousins is a collection of pretrained syntactic models for 40 languages, capable of analyzing the native language of more than half of the world’s population at often unprecedented accuracy. To better address the linguistic phenomena occurring in these languages we have endowed SyntaxNet with new abilities for Text Segmentation and Morphological Analysis.
When we released Parsey, we were already planning to expand to more languages, and it soon became clear that this was both urgent and important, because researchers were having trouble creating top notch SyntaxNet models for other languages.
The reason for that is a little bit subtle. SyntaxNet, like other TensorFlow models, has a lot of knobs to turn, which affect accuracy and speed. These knobs are called hyperparameters, and control things like the learning rate and its decay, momentum, and random initialization. Because neural networks are more sensitive to the choice of these hyperparameters than many other machine learning algorithms, picking the right hyperparameter setting is very important. Unfortunately there is no tested and proven way of doing this and picking good hyperparameters is mostly an empirical science -- we try a bunch of settings and see what works best.
An additional challenge is that training these models can take a long time, several days on very fast hardware. Our solution is to train many models in parallel via MapReduce, and when one looks promising, train a bunch more models with similar settings to fine-tune the results. This can really add up -- on average, we train more than 70 models per language. The plot below shows how the accuracy varies depending on the hyperparameters as training progresses. The best models are up to 4% absolute more accurate than ones trained without hyperparameter tuning.
 |
| Held-out set accuracy for various English parsing models with different hyperparameters (each line corresponds to one training run with specific hyperparameters). In some cases training is a lot slower and in many cases a suboptimal choice of hyperparameters leads to significantly lower accuracy. We are releasing the best model that we were able to train for each language. |
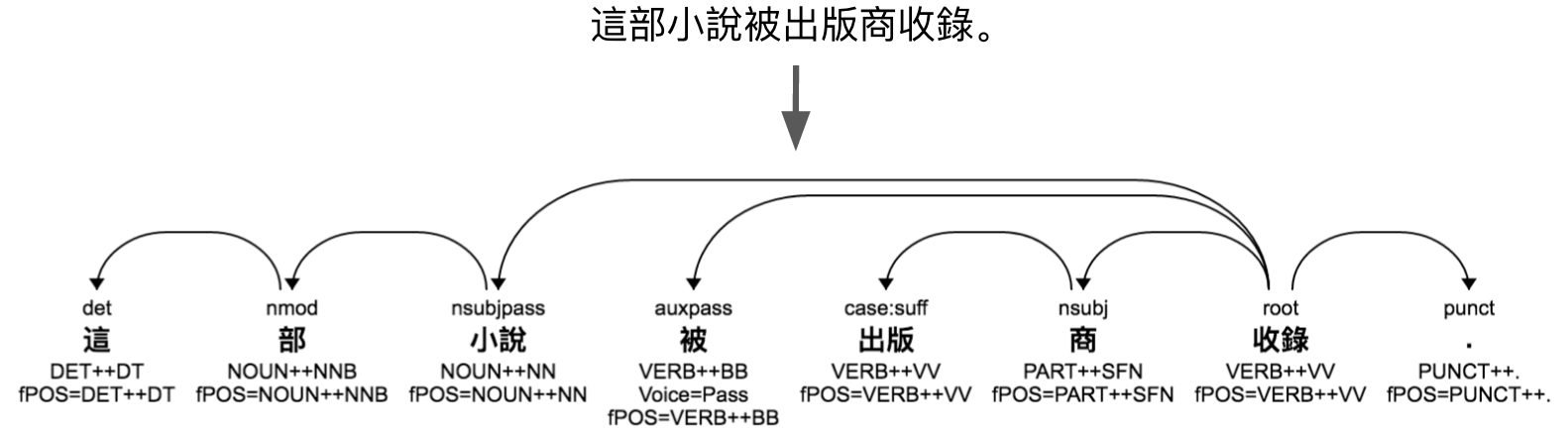 |
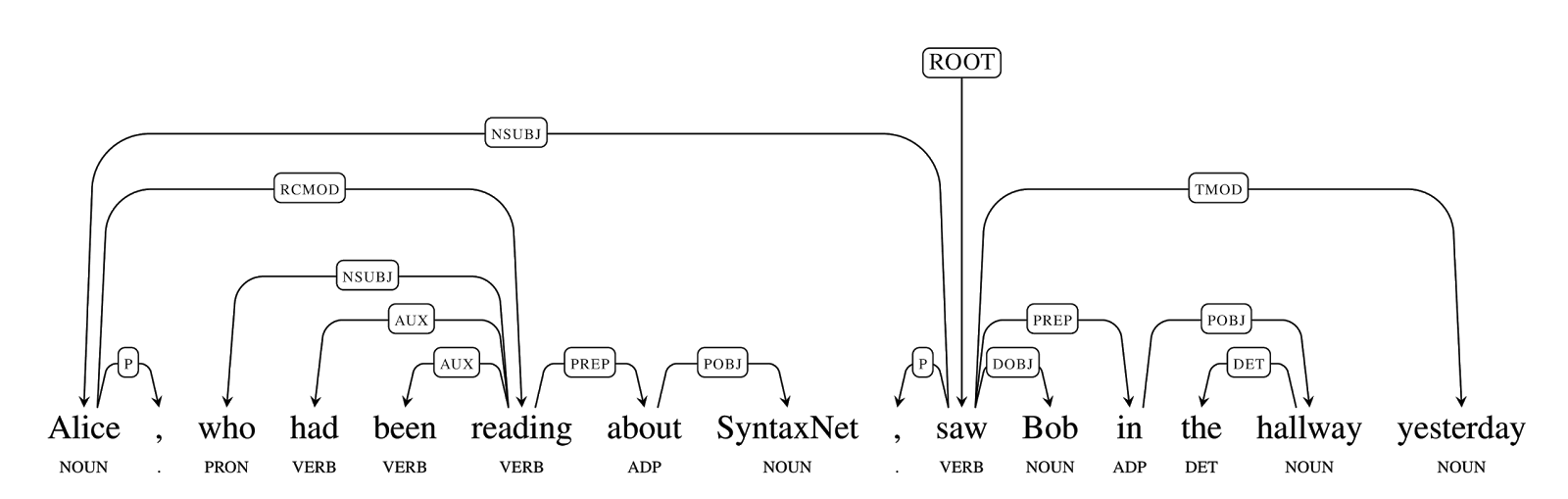
| Analysis of a Chinese string into a parse tree showing dependency labels, word tokens, and parts of speech (read top to bottom for each word token). |
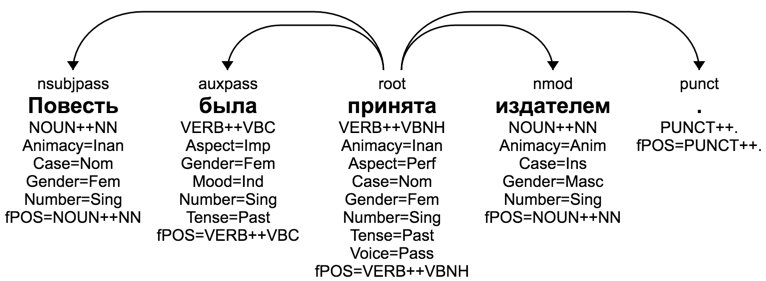 |
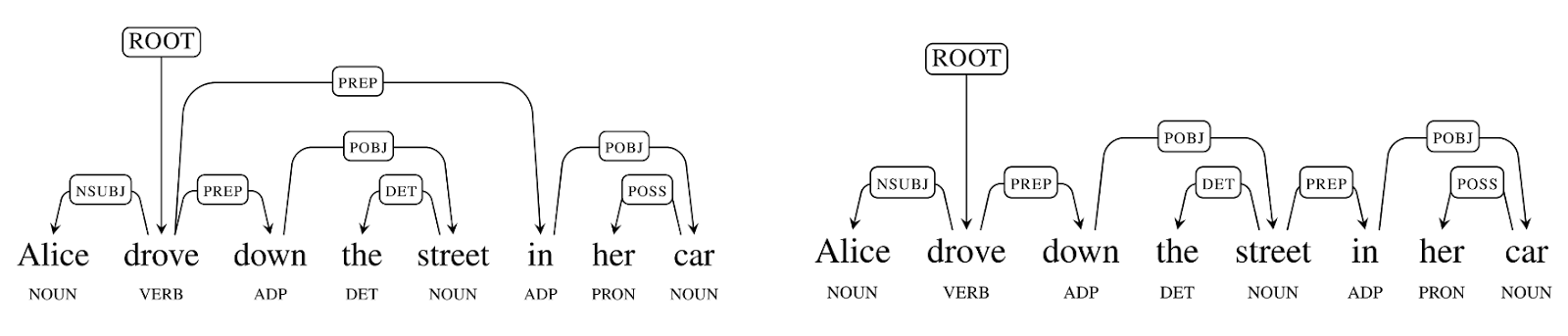
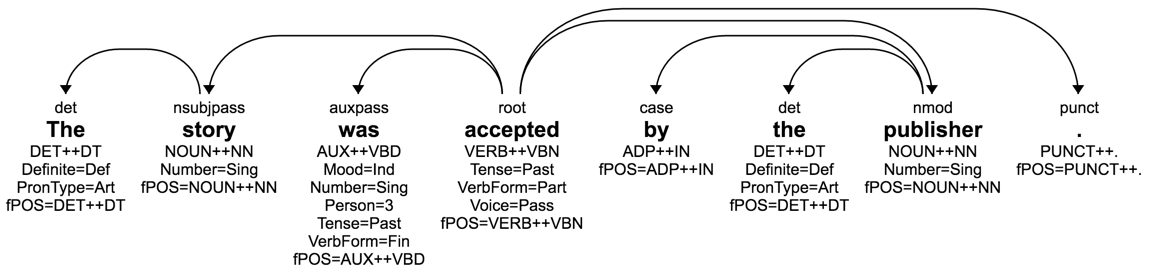
| Parse trees showing dependency labels, parts of speech, and morphology. |
Using the same set of labels across languages can help us understand how sentences in different languages, or variations in the same language, convey the same meaning. In all of the above examples, the root indicates the main verb of the sentence and there is a passive nominal subject (indicated by the arc labeled with ‘nsubjpass’) and a passive auxiliary (‘auxpass’). If you look closely, you will also notice some differences because the grammar of each language differs. For example, English uses the preposition ‘by,’ where Russian uses morphology to mark that the phrase ‘the publisher (издателем)’ is in instrumental case -- the meaning is the same, it is just expressed differently.
Google has been involved in the Universal Dependencies project since its inception and we are very excited to be able to bring together our efforts on datasets and modeling. We hope that this release will facilitate research progress in building computer systems that can understand all of the world’s languages.
Parsey's Cousins can be found on GitHub, along with Parsey McParseface and SyntaxNet.