Christina Galbato may have started as a travel blogger, but her career as a content creator has taken her on a different journey – helping other creators achieve their goals. “I started to notice a lot of the questions I was getting were less about ‘What are your travel tips for this?’ and more ‘How can I do what you do?” she shares. Galbato has made it her mission to help other bloggers and influencers earn success while remaining authentic and relatable. She sat down with us recently to share her top tips for attracting readers to a new blog.
Christina Galbato shares her top tips for bloggers hoping to grow their online followings.
1. Listen to your audience
Listening to your readers can help you create engaging content. When Christina realized her audience was interested in learning more about her business, she shifted gears and started creating content and classes that answered their questions. “I think the biggest thing has been constantly having conversations with my audience and understanding where they're at – remaining connected to what my audience wants to see is really important,” she explains.
2. Focus on branding
From your color scheme and imagery to the title of your blog, your site should let readers know at a glance exactly what to expect from your posts. “You always want to make sure the content you're creating is in line with your brand,” Christina says. Your site’s branding should always reflect the kind of content you’re promoting. For example, if you’re hoping to attract a high-end audience, she suggests going with “a more refined theme, maybe even adding some serif fonts as they tend to be more luxurious.”
3. Keep new readers coming back
Once someone has discovered your blog, it’s important to stay connected so they’ll know about your future posts. One of the best ways to do this is by offering bonus content in exchange for joining your mailing list. “You have to give people some sort of incentive to get on your list,” Christina says. “People only take action when there's something in it for them, so I would recommend creating some sort of freebie opt-in that your audience would be interested in.” Expert recommendations and educational content are great ideas for bonus posts.
4. Promote your blog online
So, how can you attract readers to your blog? Digital marketing can seem overwhelming at first, but Christina has a few suggestions to help you get started:
Learn SEO: “Before you even start writing blog posts,” Christina says, “I would get educated on SEO (search engine optimization) because that will really inform how you're writing your posts.” She recommends using KeySearchto find popular topics and keywords to help your blog rank in search results for your niche.
Get on Pinterest: “One of my favorite things about Pinterest is that you don't necessarily need to have a following for a pin of yours to really pick up,” Christina shares. It’s okay to start small – three or four well-designed pins that tie in to your niche are enough to bring new readers to your blog.
Give sneak peeks on social media:Blog posts are what Christina calls “macro content” – larger pieces that can be broken down into smaller pieces for use on social media or Web Stories. Social media is a great way to tease parts of your blog posts and entice your followers to click through to your blog. In her social posts, Christina shares, “I offer a tiny little snippet of what's in the blog post, and then tell people, ‘For more, for the juiciest stuff, you're going to have to go to the blog post.’"
For more tips from Christina – including how to build brand partnerships after you establish your blog – check out our full video interview. And don’t forget to visit Christina’s site to learn more.
At Google Arts & Culture we are always looking for ways to help people understand and learn about culture in new and engaging ways. Starting today, we are launching a new feature through which our 2,000 plus cultural partner institutions can create guided 3D tours about buildings, sculptures, furniture, and more from their collections. With the help of 3D Tours you can easily whiz around historic sites, monuments and places of interest while learning about their hidden details and historical backgrounds - all courtesy of 3D data from Google Earth.
So how about a personal guided tour through Tokyo’s tallest towers, Florence’s beautiful basilicas or South Africa’s historical halls? These and 16 other 3D Tours make use of ModelViewer — a tool through which interactive 3D models can easily be displayed on the web and in augmented reality. Not only will you be able to navigate smoothly to each stop of the tour but objects along the way can also be viewed in AR. So while you explore the heights of Tokyo Tower, you can discover its historic inspiration in your own home.
Take a tour of Florence’s Basilica of Santa Croces
Climb into a famous artwork
Another way we are bringing art and culture to life is through Art Filter, a feature in the Google Arts & Culture camera tab that applies machine learning and augmented reality to turn you into a masterpiece. Today we have added five new artworks and artifacts to Art Filter for you to immerse yourself in. For example, become the Roman god of seasons as Arcimboldo’s Vertumnus, or cast a stony glare through the head of Medusa.
Artwork of a blurry figure touching its face mid-scream.
A Gif of someone smiling using the Mona Lisa Art Filter.
Follow the history of Mona Lisa as you help reveal her elusive smile
A golden face surrounded by a silver and gold halo of serpents.
Celebrate Greek mythology as you learn the story of Medusa
How does it work?
Art Filter’s machine learning-based image processing positions the artifacts organically and smoothly on your head, or reacts to your facial expressions to make the filters as realistic as possible. What’s more, you can learn about each artwork from the fun facts that appear before the effect is applied.
We hope these 3D tours and new filter options will help you explore the hidden details of these historic artifacts and feel connected to cultural heritage around the world.
Find the tours on the Google Arts & Culture site or app. Art Filter is available in the Camera Tab of the free Google Arts & Culture app for Android and iOS.
Welcome to the latest edition of “My Path to Google,” where we talk to Googlers, interns and alumni about how they got to Google, what their roles are like and even some tips on how to prepare for interviews.
Today we spoke with Kiranmayi Bhamidimarri, a software engineer at our Bangalore office, who shares her story of joining Google after taking a year-and-a-half break from the workforce.
What’s your role at Google?
I am a software engineer for Google Cloud, where I work on Cloud Spanner — a database management and storage service. My team is focused on developing introspection tools for this system, which help our customers better understand any issues with their Spanner databases.
What was it like taking a break from the workforce?
Stepping back from the workforce marked a turning point in my life. Through a lot of reflection, I grew both as a person and as a professional during that period — even though I wasn’t working. For example, I discovered that I care deeply about diversity and inclusion in all aspects of my career, including the places I work. After taking the time to develop these bigger-picture perspectives and once I felt comfortable balancing things in my personal life, I started exploring returning to work.
What made you decide to apply to Google?
I came across the concept of Carer’s Leave and what this benefit looks like at Google. When a family member or loved one falls seriously ill, Google's Carer's Leave policy allows employees to take the time they need to provide or find care for them. I liked the idea of working at a company that helps employees support their family in times of need. This led me to researching Google’s culture overall. I loved that Google is an inclusive place that would allow me to bring my whole self to work and not leave my personal life behind — which became especially important to me after my career break.
How did you approach the Google application process after taking a career break?
At first, I was very nervous and told myself not to be too ambitious. I struggled with impostor syndrome and wasn’t sure if I would do well in the interviews, which I’d always heard were challenging. Then a friend who interviewed with Google shared her positive experience with me, and busted many myths. She explained, for example, that the interviews focus on thought process rather than the exact solution. She ultimately helped me realize my worth and put my best foot forward.
What was the interview process like for you?
When I first decided to apply, I asked a friend who recently joined Google for advice. He guided me through the process and even helped me with a referral, but I was rejected at the resume screening phase. At the time, my resume didn't reflect my actual skills and experience. I didn’t list everything I’d worked on, because I was afraid I had forgotten too much during my break to explain or answer questions. I was shrinking myself into someone else so they wouldn't expect so much from me.
My friend who referred me encouraged me to revamp my resume and try again. I reached out to some Google recruiters on LinkedIn, who took the time to speak with me and look at my updated resume. One of the recruiters set up a phone interview, and that kicked off the process.
What’s one thing you wish you could go back and tell yourself before applying?
It’s okay not to be perfect. During my phone interview, I answered one of the questions incorrectly. I was nervous and disappointed about the mistake, but the interviewer encouraged me to try again and I ultimately found the right solution. So I would tell myself that it's okay to make mistakes, as long as I learn from them and continue to grow.
I would also reassure myself that I won't be treated differently because of my career break. That was a big fear of mine, and I'm so happy I was proven wrong. I am grateful to everyone at Google who spoke to me about my hesitations with returning to the workforce, and provided mentorship and support. Now six months in, I continue to feel valued and encouraged to bring every part of myself to work.
Twenty years ago, Google opened its first office in Japan. Today, we are announcing new investments that will continue our support of the country’s vibrant news industry. These investments will help people find quality journalism and contribute to the sustainability of news organizations. They will also help newsrooms engage their readers in new ways, through the COVID-19 pandemic and beyond.
Launching Google News Showcase in Japan
To support news organizations and readers in Japan, we’re introducing Google News Showcase, our new curated online experience and licensing program. News Showcase panels display an enhanced view of an article or articles, giving participating publishers more ways to bring important news to readers and explain it in their own voice, along with more direct control of presentation and branding. The panels will appear across Google News on Android, iOS and the web, and in Discover on iOS and Android. They direct readers to the full articles on their websites, driving valuable traffic to those news organizations and enabling them to deepen their relationships with readers.
The primary goal of News Showcase is to highlight news publishers that are invested in comprehensive current events journalism in the public interest. We are giving them a new way to curate their high-quality content on Google’s News and Discover platforms, bringing essential news coverage to readers looking for it.
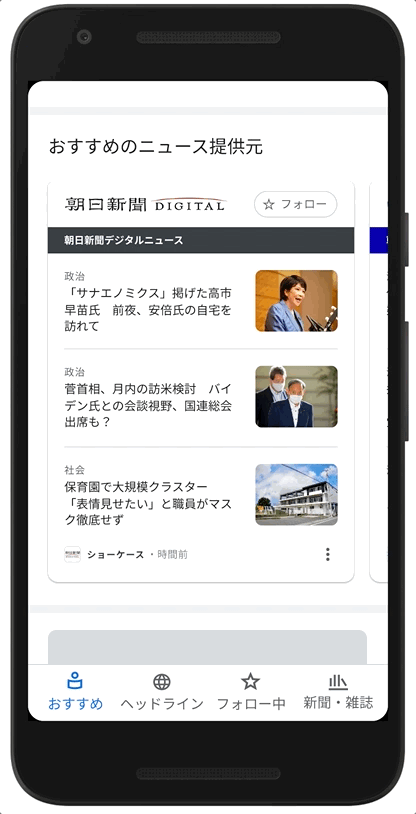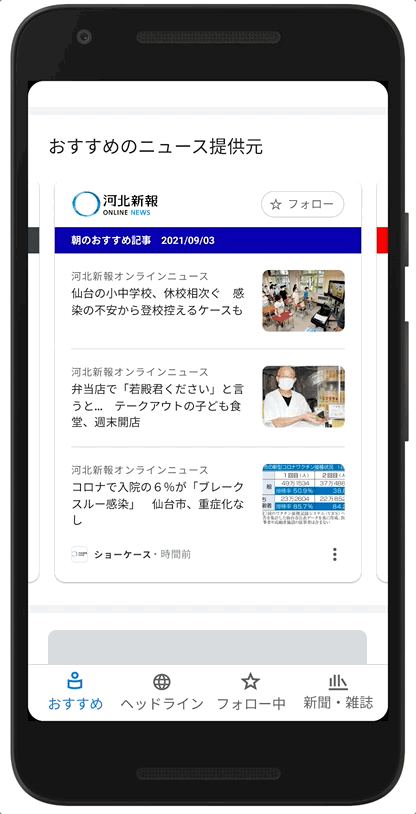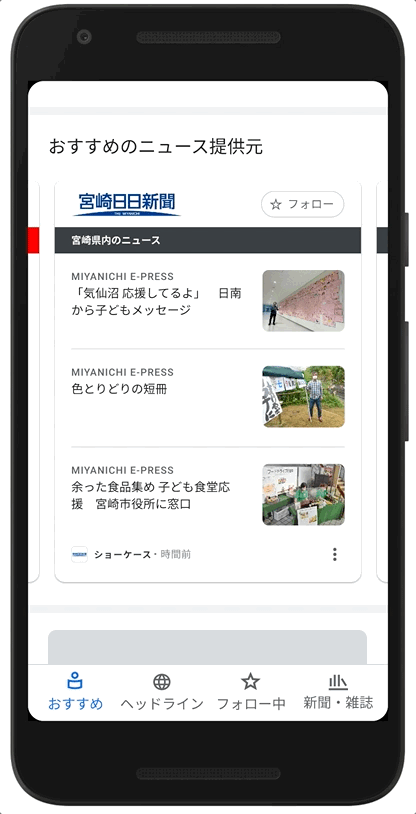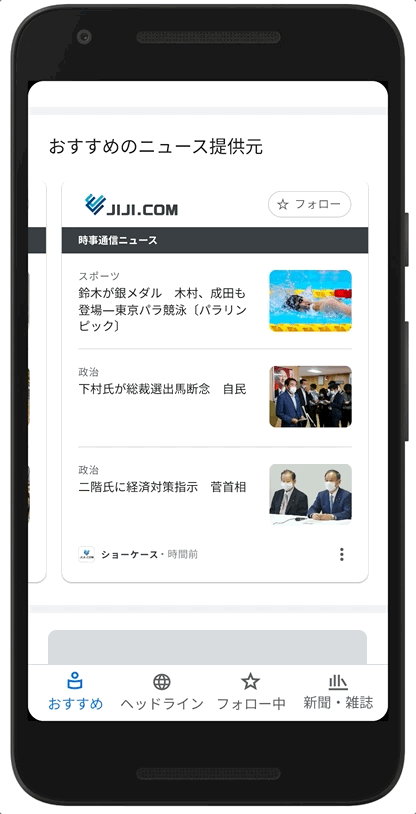
Examples of how News Showcase panels will look with the content of some of our news partners in Japan.
As part of our licensing agreements with publishers for News Showcase, we're also paying participating news organizations to give readers access to a limited amount of paywalled content. This feature means readers will have the opportunity to read more of a publisher’s articles than they would otherwise be able to, encouraging them to learn more about the publication — and potentially subscribe.
Example of how some of the content from our News Showcase partners in Japan will look
What our partners have to say about News Showcase
"We are joining Google News Showcase to deliver high-quality news content in the Chunichi Shimbun and the Tokyo Shimbun to as many people as possible,” says Koji Hirata, Director and Editor-in-Chief of The Chunichi Shimbun, the top regional newspaper covering Tokai, Chubu and the Kanto/Tokyo Metropolitan region. “Apart from daily news, we will select unique stories that capture multiple perspectives and introduce them to users. Through Google News Showcase, we want readers to find a wide variety of information in the Chunichi Shimbun Web and the Tokyo Shimbun TOKYO Web that helps them make better choices for their life and future.”
“By participating in Google News Showcase, we look forward to extending the accurate and useful news we provide for people in Kyoto and Shiga,” says Tokuyuki Enjo, the Chief Editor of the Kyoto Shimbun, a local newspaper company covering the Kyoto and Shiga area. “In addition, we will work to bring content that touches upon the deep traditional culture and history of Kyoto to a broader audience than ever before.”
“We are thrilled to provide news from Okinawa Times globally through Google News Showcase,” says Kazue Yonamine, Director, Editor-in-Chief of The Okinawa Times, a local newspaper covering the Okinawa area. “Google's cooperation has become indispensable for the development of journalism. We aim to cooperate with each other and deliver useful information for the creation of a sustainable society.”
“As a local newspaper, our mission has been to deliver global and local news to the community in print. In the digital era, we need to expand our role to deliver local news to a broader global audience." said Seichiro Hanafusa, the webmaster of Shikoku Shimbun, the local newspaper covering the Shikoku region. "Google News Showcase is a tool for us to deliver our news articles across Japan as well as the world, and lets users easily subscribe to our content. With this opportunity, we will work even harder to create valuable content that motivates users to pay for."
Logos of our Japan news partners for Google News Showcase
Expanded support through the Google News Initiative
Women Will Leadership Program: To promote a more inclusive culture for the news industry, we are launching a news-specific track of Google’s Women Will Leadership Program. Through two months of leadership skills training and problem solving workshops, this program will help women working in news to advance their careers and support companies seeking to drive change in the work environment.
GNI Local Lab:We’re expanding the GNI Local Lab to support local news publishers in Japan. We will train more than 40 news publishers across regional prefectures with workshops and knowledge-sharing sessions to help news organizations improve their site performance and provide hands-on implementation support to grow digital revenue streams for local publishers.
Build New Local: We are also supporting Build New Local, a project led by local newspapers to help them use technology to connect and digitally transform so they can become more sustainable and reach new audiences. Through Grow with Google and Google News Lab, Google has provided skills training in areas such as digital marketing and audience development. We also supported an idea hackathon, where local newspapers gathered to solve common challenges by sharing tips on design thinking from CSI: Lab, and a new business idea contest will start later this year.
Japan’s news industry has embraced technology to engage with readers and make data-driven decisions. We believe digital platforms can contribute to a sustainable, independent and diverse news industry, working with journalists, news outlets and news associations. We’re proud to be strengthening our commitment through News Showcase, along with our other News products and GNI programs, to support quality journalism.
Hi everyone! We've just released Chrome Beta 94 (94.0.4606.50) for Android: it's now available on Google Play.
You can see a partial list of the changes in the Git log. For details on new features, check out the Chromium blog, and for details on web platform updates, check here.
If you find a new issue, please let us know by filing a bug.
The Beta channel has been updated to 94.0.4606.50 for Windows ,linux and 94.0.4606.51 for Mac.
A full list of changes in this build is available in the log. Interested in switching release channels? Find out how here. If you find a new issue, please let us know by filing a bug. The community help forum is also a great place to reach out for help or learn about common issues.
The Stable channel is being updated to 93.0.4577.85 (Platform version: 14092.57.0) for most Chrome OS devices. Systems will be receiving updates over the next several days.
This build contains a number of features, bug fixes and security updates.
If you find new issues, please let us know by visiting our forum or filing a bug. Interested in switching channels Find out how. You can submit feedback using ‘Report an issue...’ in the Chrome menu (3 vertical dots in the upper right corner of the browser).
The Stable channel is being updated to 93.0.4577.85 (Platform version: 14092.57.0) for most Chrome OS devices. Systems will be receiving updates over the next several days.
This build contains a number of features, bug fixes and security updates.
If you find new issues, please let us know by visiting our forum or filing a bug. Interested in switching channels Find out how. You can submit feedback using ‘Report an issue...’ in the Chrome menu (3 vertical dots in the upper right corner of the browser).
The Stable channel is being updated to 93.0.4577.85 (Platform version: 14092.57.0) for most Chrome OS devices. Systems will be receiving updates over the next several days.
This build contains a number of features, bug fixes and security updates.
If you find new issues, please let us know by visiting our forum or filing a bug. Interested in switching channels Find out how. You can submit feedback using ‘Report an issue...’ in the Chrome menu (3 vertical dots in the upper right corner of the browser).
Posted by Vighnesh Birodkar, Research Software Engineer and Jonathan Huang, Research Scientist, Google Research
Instance segmentation is the task of grouping pixels in an image into instances of individual things, and identifying those things with a class label (countable objects such as people, animals, cars, etc., and assigning unique identifiers to each, e.g., car_1 and car_2). As a core computer vision task, it is critical to many downstream applications, such as self-driving cars, robotics, medical imaging, and photo editing. In recent years, deep learning has made significant strides in solving the instance segmentation problem with architectures like Mask R-CNN. However, these methods rely on collecting a large labeled instance segmentation dataset. But unlike bounding box labels, which can be collected in 7 seconds per instance with methods like Extreme clicking, collecting instance segmentation labels (called “masks”) can take up to 80 seconds per instance, an effort that is costly and creates a high barrier to entry for this research. And a related task, pantopic segmentation, requires even more labeled data.
The partially supervised instance segmentation setting, where only a small set of classes are labeled with instance segmentation masks and the remaining (majority of) classes are labeled only with bounding boxes, is an approach that has the potential to reduce the dependence on manually-created mask labels, thereby significantly lowering the barriers to developing an instance segmentation model. However this partially supervised approach also requires a stronger form of model generalization to handle novel classes not seen at training time—e.g., training with only animal masks and then tasking the model to produce accurate instance segmentations for buildings or plants. Further, naïve approaches, such as training a class-agnostic Mask R-CNN, while ignoring mask losses for any instances that don’t have mask labels, have not worked well. For example, on the typical “VOC/Non-VOC” benchmark, where one trains on masks for a subset of 20 classes in COCO (called “seen classes”) and is tested on the remaining 60 classes (called “unseen classes”), a typical Mask R-CNN with Resnet-50 backbone gets to only ~18% mask mAP (mean Average Precision, higher is better) on unseen classes, whereas when fully supervised it can achieve a much higher >34% mask mAP on the same set.
In “The surprising impact of mask-head architecture on novel class segmentation”, to be presented at ICCV 2021, we identify the main culprits for Mask R-CNN’s poor performance on novel classes and propose two easy-to-implement fixes (one training protocol fix, one mask-head architecture fix) that work in tandem to close the gap to fully supervised performance. We show that our approach applies generally to crop-then-segment models, i.e., a Mask R-CNN or Mask R-CNN-like architecture that computes a feature representation of the entire image and then subsequently passes per-instance crops to a second-stage mask prediction network—also called a mask-head network. Putting our findings together, we propose a Mask R-CNN–based model that improves over the current state-of-the-art by a significant 4.7% mask mAP without requiring more complex auxiliary loss functions, offline trained priors, or weight transfer functions proposed by previous work. We have also open sourced the code bases for two versions of the model, called Deep-MAC and Deep-MARC, and published a colab to interactively produce masks like the video demo below.
A demo of our model, DeepMAC, which learns to predict accurate masks, given user specified boxes, even on novel classes that were not seen at training time. Try it yourself in the colab. Image credits: Chris Briggs, Wikipedia and Europeana.
Impact of Cropping Methodology in Partially Supervised Settings An important step of crop-then-segment models is cropping—Mask R-CNN is trained by cropping a feature map as well as the ground truth mask to a bounding box corresponding to each instance. These cropped features are passed to another neural network (called a mask-head network) that computes a final mask prediction, which is then compared against the ground truth crop in the mask loss function. There are two choices for cropping: (1) cropping directly to the ground truth bounding box of an instance, or (2) cropping to bounding boxes predicted by the model (called, proposals). At test time, cropping is always performed with proposals as ground truth boxes are not assumed to be available.
Cropping to ground truth boxes vs. cropping to proposals predicted by a model during training. Standard Mask R-CNN implementations use both types of crops, but we show that cropping exclusively to ground truth boxes yields significantly stronger performance on novel categories.
We consider a general family of Mask R-CNN–like architectures with one small, but critical difference from typical Mask R-CNN training setups: we crop using ground truth boxes (instead of proposal boxes) at training time.
Typical Mask R-CNN implementations pass both types of crops to the mask head. However, this choice has traditionally been considered an unimportant implementation detail, because it does not affect performance significantly in the fully supervised setting. In contrast, for partially supervised settings, we find that cropping methodology plays a significant role—while cropping exclusively to ground truth boxes during training doesn’t change the results significantly in the fully supervised setting, it has a surprising and dramatic positive impact in the partially supervised setting, performing significantly better on unseen classes.
Performance of Mask R-CNN on unseen classes when trained with either proposals and ground truth (the default) or with only ground truth boxes. Training mask heads with only ground truth boxes yields a significant boost to performance on unseen classes, upwards of 9% mAP. We report performance with the ResNet-101-FPN backbone.
Unlocking the Full Generalization Potential of the Mask Head Even more surprisingly, the above approach unlocks a novel phenomenon—with cropping-to-ground truth enabled during training, the mask head of Mask R-CNN takes on a disproportionate role in the ability of the model to generalize to unseen classes. As an example, in the following figure, we compare models that all have cropping-to-ground-truth enabled, but different out-of-the-box mask-head architectures on a parking meter, cell phone, and pizza (classes unseen during training).
Mask predictions for unseen classes with four different mask-head architectures (from left to right: ResNet-4, ResNet-12, ResNet-20, Hourglass-20, where the number refers to the number of layers of the neural network). Despite never having seen masks from the ‘parking meter’, ‘pizza’ or ‘mobile phone’ class, the rightmost mask-head architecture can segment these classes correctly. From left to right, we show better mask-head architectures predicting better masks. Moreover, this difference is only apparent when evaluating on unseen classes — if we evaluate on seen classes, all four architectures exhibit similar performance.
Particularly notable is that these differences between mask-head architectures are not as obvious in the fully supervised setting. Incidentally, this may explain why previous works in instance segmentation have almost exclusively used shallow (i.e., low number of layers) mask heads, as there has been no benefit to the added complexity. Below we compare the mask mAP of three different mask-head architectures on seen versus unseen classes. All three models do equally well on the set of seen classes, but the deep hourglass mask heads stand out when applied to unseen classes. We find hourglass mask heads to be the best among the architectures we tried and we use hourglass mask heads with 50 or more layers to get the best results.
Performance of ResNet-4, Hourglass-10 and Hourglass-52 mask-head architectures on seen and unseen classes. There is a significant difference in performance on unseen classes, even though the performance on seen classes barely changes.
Finally, we show that our findings are general, holding for a variety of backbones (e.g., ResNet, SpineNet, Hourglass) and detector architectures including anchor-based and anchor-free detectors and even when there is no detector at all.
Putting It Together To achieve the best result, we combined the above findings: We trained a Mask R-CNN model with cropping-to-ground-truth enabled and a deep Hourglass-52 mask head with a SpineNet backbone on high resolution images (1280x1280). We call this model Deep-MARC (Deep Mask heads Above R-CNN). Without using any offline training or other hand-crafted priors, Deep-MARC exceeds previous state-of-the-art models by > 4.5% (absolute) mask mAP. Demonstrating the general nature of this approach, we also see strong results with a CenterNet-based (as opposed to Mask R-CNN-based) model (called Deep-MAC), which also exceeds the previous state of the art.
Comparison of Deep-MAC and Deep-MARC to other partially supervised instance segmentation approaches like MaskX R-CNN, ShapeMask and CPMask.
Conclusion We develop instance segmentation models that are able to generalize to classes that were not part of the training set. We highlight the role of two key ingredients that can be applied to any crop-then-segment model (such as Mask R-CNN): (1) cropping-to-ground truth boxes during training, and (2) strong mask-head architectures. While neither of these ingredients have a large impact on the classes for which masks are available during training, employing both leads to significant improvement on novel classes for which masks are not available during training. Moreover, these ingredients are sufficient for achieving state-of-the-art-performance on the partially-supervised COCO benchmark. Finally, our findings are general and may also have implications for related tasks, such as panoptic segmentation and pose estimation.
Acknowledgements We thank our co-authors Zhichao Lu, Siyang Li, and Vivek Rathod. We thank David Ross and our anonymous ICCV reviewers for their comments which played a big part in improving this research.










{kind=link}