Posted by Alex Olwal, Research Scientist, Google Augmented Reality and Artem Dementyev, Hardware Engineer, Google Research As consumer electronics and internet-connected appliances are becoming more common, homes are beginning to embrace various types of connected devices that offer functionality like music control, voice assistance, and home automation. A graceful integration of devices requires adaptation to existing aesthetics and user styles rather than simply adding screens, which can easily disrupt a visual space, especially when they become monolithic surfaces or black screens when powered down or not actively used. Thus there is an increasing desire to create connected ambient computing devices and appliances that can preserve the aesthetics of everyday materials, while providing on-demand access to interaction and digital displays.
 |
| Illustration of how hidden interfaces can appear and disappear in everyday surfaces, such as a mirror or the wood paneling of a home appliance. |
In “Hidden Interfaces for Ambient Computing: Enabling Interaction in Everyday Materials through High-Brightness Visuals on Low-Cost Matrix Displays”, presented at ACM CHI 2022, we describe an interface technology that is designed to be embedded underneath materials and our vision of how such technology can co-exist with everyday materials and aesthetics. This technology makes it possible to have high-brightness, low-cost displays appear from underneath materials such as textile, wood veneer, acrylic or one-way mirrors, for on-demand touch-based interaction.
 |
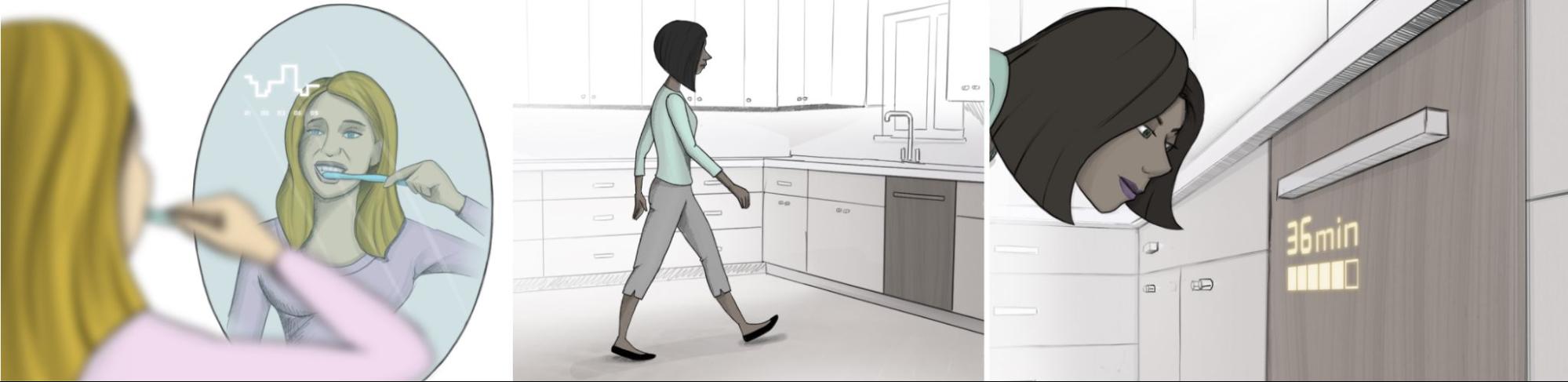
| Hidden interface prototypes demonstrate bright and expressive rendering underneath everyday materials. From left to right: thermostat under textile, a scalable clock under wood veneer, and a caller ID display and a zooming countdown under mirrored surfaces. |
Parallel Rendering: Boosting PMOLED Brightness for Ambient Computing
While many of today’s consumer devices employ active-matrix organic light-emitting diode (AMOLED) displays, their cost and manufacturing complexity is prohibitive for ambient computing. Yet other display technologies, such as E-ink and LCD, do not have sufficient brightness to penetrate materials.
To address this gap, we explore the potential of passive-matrix OLEDs (PMOLEDs), which are based on a simple design that significantly reduces cost and complexity. However, PMOLEDs typically use scanline rendering, where active display driver circuitry sequentially activates one row at a time, a process that limits display brightness and introduces flicker.
Instead, we propose a system that uses parallel rendering, where as many rows as possible are activated simultaneously in each operation by grouping rectilinear shapes of horizontal and vertical lines. For example, a square can be shown with just two operations, in contrast to traditional scanline rendering that needs as many operations as there are rows. With fewer operations, parallel rendering can output significantly more light in each instant to boost brightness and eliminate flicker. The technique is not strictly limited to lines and rectangles even if that is where we see the most dramatic performance increase. For example, one could add additional rendering steps for antialiasing (i.e., smoothing of) non-rectilinear content.
 |
| Illustration of scanline rendering (top) and parallel rendering (bottom) operations of an unfilled rectangle. Parallel rendering achieves bright, flicker-free graphics by simultaneously activating multiple rows. |
Rendering User Interfaces and Text
We show that hidden interfaces can be used to create dynamic and expressive interactions. With a set of fundamental UI elements such as buttons, switches, sliders, and cursors, each interface can provide different basic controls, such as light switches, volume controls and thermostats. We created a scalable font (i.e., a set of numbers and letters) that is designed for efficient rendering in just a few operations. While we currently exclude letters “k, z, x” with their diagonal lines, they could be supported with additional operations. The per-frame-control of font properties coupled with the high frame rate of the display enables very fluid animations — this capability greatly expands the expressivity of the rectilinear graphics far beyond what is possible on fixed 7-segment LED displays.
In this work, we demonstrate various examples, such as a scalable clock, a caller ID display, a zooming countdown timer, and a music visualizer.
Realizing Hidden Interfaces with Interactive Hardware
To implement proof-of-concept hidden interfaces, we use a PMOLED display with 128×96 resolution that has all row and column drivers routed to a connector for direct access. We use a custom printed circuit board (PCB) with fourteen 16-channel digital-to-analog converters (DACs) to directly interface those 224 lines from a Raspberry Pi 3 A+. The touch interaction is enabled by a ring-shaped PCB surrounding the display with 12 electrodes arranged in arc segments.
Comparison to Existing Technologies
We compared the brightness of our parallel rendering to both the scanline on the same PMOLED and a small and large state-of-the-art AMOLED. We tested brightness through six common materials, such as wood and plastic. The material thickness ranged from 0.2 mm for the one-way mirror film to 1.6 mm for basswood. We measured brightness in lux (lx = light intensity as perceived by the human eye) using a light meter near the display. The environmental light was kept dim, slightly above the light meter’s minimum sensitivity. For simple rectangular shapes, we observed 5–40x brightness increase for the PMOLED in comparison to the AMOLED. The exception was the thick basswood, which didn’t let much light through for any rendering technology.
 |
| Example showing performance difference between parallel rendering on the PMOLED (this work) and a similarly sized modern 1.4″ AMOLED. |
To validate the findings from our technical characterization with more realistic and complex content, we evaluate the number “2”, a grid of checkboxes, three progress bars, and the text “Good Life”. For this more complex content, we observed a 3.6–9.3x brightness improvement. These results suggest that our approach of parallel rendering on PMOLED enables display through several materials, and outperforms common state-of-the-art AMOLED displays, which seem to not be usable for the tested scenarios.
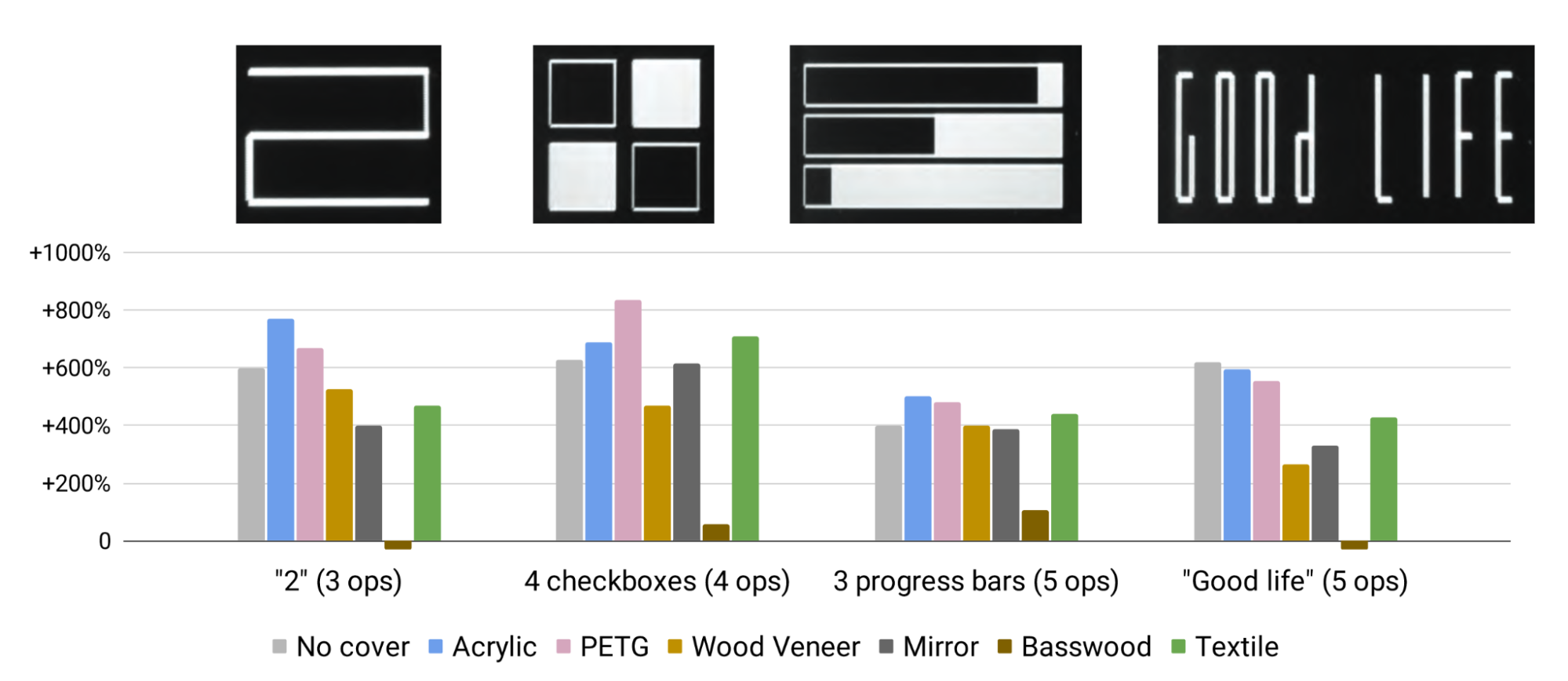 |
| Brightness experiments with additional shapes that require different numbers of operations (ops). Measurements are shown in comparison to large state-of-the-art AMOLED displays. |
What's Next?
In this work, we enabled hidden interfaces that can be embedded in traditional materials and appear on demand. Our lab evaluation suggests unmet opportunities to introduce hidden displays with simple, yet expressive, dynamic and interactive UI elements and text in traditional materials, especially wood and mirror, to blend into people’s homes.
In the future, we hope to investigate more advanced parallel rendering techniques, using algorithms that could also support images and complex vector graphics. Furthermore, we plan to explore efficient hardware designs. For example, application-specific integrated circuits (ASICs) could enable an inexpensive and small display controller with parallel rendering instead of a large array of DACs. Finally, longitudinal deployment would enable us to go deeper into understanding user adoption and behavior with hidden interfaces.
Hidden interfaces demonstrate how control and feedback surfaces of smart devices and appliances could visually disappear when not in use and then appear when in the user's proximity or touch. We hope this direction will encourage the community to consider other approaches and scenarios where technology can fade into the background for a more harmonious coexistence with traditional materials and human environments.
Acknowledgements
First and foremost, we would like to thank Ali Rahimi and Roman Lewkow for the collaboration, including providing the enabling technology. We also thank Olivier Bau, Aaron Soloway, Mayur Panchal and Sukhraj Hothi for their prototyping and fabrication contributions. We thank Michelle Chang and Mark Zarich for visual designs, illustrations and presentation support. We thank Google ATAP and the Google Interaction Lab for their support of the project. Finally, we thank Sarah Sterman and Mathieu Le Goc for helpful discussions and suggestions.