We’re thrilled to introduce 25 open source organizations that are participating in Google Code-in 2017. The contest, now in its eighth year, offers 13-17 year old pre-university students an opportunity to learn and practice their skills while contributing to open source projects.
Google Code-in officially starts for students on November 28. Students are encouraged to learn about the participating organizations ahead of time and can get started by clicking on the links below:
Wikimedia: non-profit foundation dedicated to bringing free content to the world, operating Wikipedia
XWiki: a web platform for developing collaborative applications using the wiki paradigm
Zulip: powerful, threaded open source group chat with apps for every major platform
These mentor organizations are hard at work creating thousands of tasks for students to work on, including code, documentation, user interface, quality assurance, outreach, research and training tasks. The contest officially starts for students on Tuesday, November 28th at 9:00am PST.
“The underlying physical laws necessary for the mathematical theory of a large part of physics and the whole of chemistry are thus completely known, and the difficulty is only that the exact application of these laws leads to equations much too complicated to be soluble.” -Paul Dirac, Quantum Mechanics of Many-Electron Systems (1929)
In this passage, physicist Paul Dirac laments that while quantum mechanics accurately models all of chemistry, exactly simulating the associated equations appears intractably complicated. Not until 1982 would Richard Feynman suggest that instead of surrendering to the complexity of quantum mechanics, we might harness it as a computational resource. Hence, the original motivation for quantum computing: by operating a computer according to the laws of quantum mechanics, one could efficiently unravel exact simulations of nature. Such simulations could lead to breakthroughs in areas such as photovoltaics, batteries, new materials, pharmaceuticals and superconductivity. And while we do not yet have a quantum computer large enough to solve classically intractable problems in these areas, rapid progress is being made. Last year, Google published this paper detailing the first quantum computation of a molecule using a superconducting qubit quantum computer. Building on that work, the quantum computing group at IBM scaled the experiment to larger molecules, which made the cover of Nature last month.
Today, we announce the release of OpenFermion, the first open source platform for translating problems in chemistry and materials science into quantum circuits that can be executed on existing platforms. OpenFermion is a library for simulating the systems of interacting electrons (fermions) which give rise to the properties of matter. Prior to OpenFermion, quantum algorithm developers would need to learn a significant amount of chemistry and write a large amount of code hacking apart other codes to put together even the most basic quantum simulations. While the project began at Google, collaborators at ETH Zurich, Lawrence Berkeley National Labs, University of Michigan, Harvard University, Oxford University, Dartmouth College, Rigetti Computing and NASA all contributed to alpha releases. You can learn more details about this release in our paper, OpenFermion: The Electronic Structure Package for Quantum Computers.
One way to think of OpenFermion is as a tool for generating and compiling physics equations which describe chemical and material systems into representations which can be interpreted by a quantum computer1. The most effective quantum algorithms for these problems build upon and extend the power of classical quantum chemistry packages used and developed by research chemists across government, industry and academia. Accordingly, we are also releasing OpenFermion-Psi4 and OpenFermion-PySCF which are plugins for using OpenFermion in conjunction with the classical electronic structure packages Psi4 and PySCF.
The core OpenFermion library is designed in a quantum programming framework agnostic way to ensure compatibility with various platforms being developed by the community. This allows OpenFermion to support external packages which compile quantum assembly language specifications for diverse hardware platforms. We hope this decision will help establish OpenFermion as a community standard for putting quantum chemistry on quantum computers. To see how OpenFermion is used with diverse quantum programming frameworks, take a look at OpenFermion-ProjectQ and Forest-OpenFermion - plugins which link OpenFermion to the externally developed circuit simulation and compilation platforms known as ProjectQ and Forest.
The following workflow describes how a quantum chemist might use OpenFermion in order to simulate the energy surface of a molecule (for instance, by preparing the sort of quantum computation we described in our past blog post):
The researcher initializes an OpenFermion calculation with specification of:
An input file specifying the coordinates of the nuclei in the molecule.
The basis set (e.g. cc-pVTZ) that should be used to discretize the molecule.
The researcher uses the OpenFermion-Psi4 plugin or the OpenFermion-PySCF plugin to perform scalable classical computations which are used to optimally stage the quantum computation. For instance, one might perform a classical Hartree-Fock calculation to choose a good initial state for the quantum simulation.
The researcher then specifies which electrons are most interesting to study on a quantum computer (known as an active space) and asks OpenFermion to map the equations for those electrons to a representation suitable for quantum bits, using one of the available procedures in OpenFermion, e.g. the Bravyi-Kitaev transformation.
The researcher selects a quantum algorithm to solve for the properties of interest and uses a quantum compilation framework such as OpenFermion-ProjectQ to output the quantum circuit in assembly language which can be run on a quantum computer. If the researcher has access to a quantum computer, they then execute the experiment.
A few examples of what one might do with OpenFermion are demonstrated in ipython notebooks here, here and here. While quantum simulation is widely recognized as one of the most important applications of quantum computing in the near term, very few quantum computer scientists know quantum chemistry and even fewer chemists know quantum computing. Our hope is that OpenFermion will help to close the gap between these communities and bring the power of quantum computing to chemists and material scientists. If you’re interested, please checkout our GitHub repository - pull requests welcome! By Ryan Babbush and Jarrod McClean, Quantum Software Engineers, Quantum AI Team
1 If we may be allowed one sentence for the experts: the primary function of OpenFermion is to encode the electronic structure problem in second quantization defined by various basis sets and active spaces and then to transform those operators into spin Hamiltonians using various isomorphisms between qubit and fermion algebras.↩
Crossposted on the Google Research Blog Machine learning has made huge advances in many applications including natural language processing, computer vision and recommendation systems by capturing complex input/output relationships using highly flexible models. However, a remaining challenge is problems with semantically meaningful inputs that obey known global relationships, like “the estimated time to drive a road goes up if traffic is heavier, and all else is the same.” Flexible models like DNNs and random forests may not learn these relationships, and then may fail to generalize well to examples drawn from a different sampling distribution than the examples the model was trained on.
Today we present TensorFlow Lattice, a set of prebuilt TensorFlow Estimators that are easy to use, and TensorFlow operators to build your own lattice models. Lattices are multi-dimensional interpolated look-up tables (for more details, see [1--5]), similar to the look-up tables in the back of a geometry textbook that approximate a sine function. We take advantage of the look-up table’s structure, which can be keyed by multiple inputs to approximate an arbitrarily flexible relationship, to satisfy monotonic relationships that you specify in order to generalize better. That is, the look-up table values are trained to minimize the loss on the training examples, but in addition, adjacent values in the look-up table are constrained to increase along given directions of the input space, which makes the model outputs increase in those directions. Importantly, because they interpolate between the look-up table values, the lattice models are smooth and the predictions are bounded, which helps to avoid spurious large or small predictions in the testing time.
How Lattice Models Help You
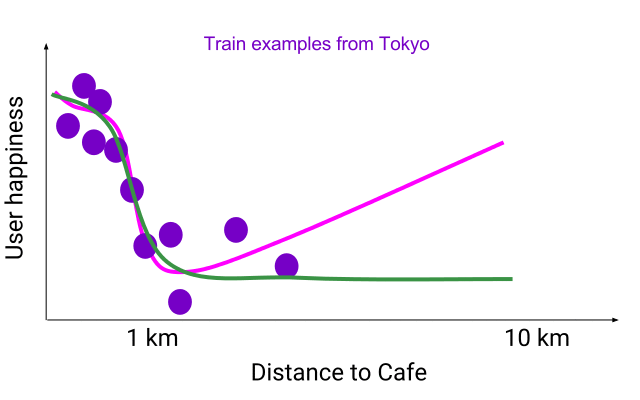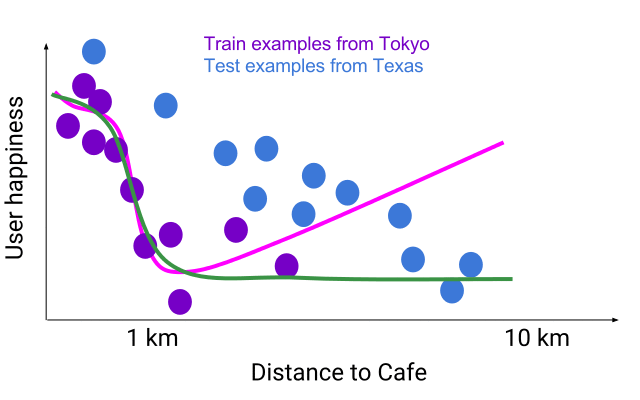
Suppose you are designing a system to recommend nearby coffee shops to a user. You would like the model to learn, “if two cafes are the same, prefer the closer one.” Below we show a flexible model (pink) that accurately fits some training data for users in Tokyo (purple), where there are many coffee shops nearby. The pink flexible model overfits the noisy training examples, and misses the overall trend that a closer cafe is better. If you used this pink model to rank test examples from Texas (blue), where businesses are spread farther out, you would find it acted strangely, sometimes preferring farther cafes!
Slice through a model’s feature space where all the other inputs stay the same and only distance changes. A flexible function (pink) that is accurate on training examples from Tokyo (purple) predicts that a cafe 10km-away is better than the same cafe if it was 5km-away. This problem becomes more evident at test-time if the data distribution has shifted, as shown here with blue examples from Texas where cafes are spread out more.
A monotonic flexible function (green) is both accurate on training examples and can generalize for Texas examples compared to non-monotonic flexible function (pink) from the previous figure.
In contrast, a lattice model, trained over the same example from Tokyo, can be constrained to satisfy such a monotonic relationship and result in a monotonic flexible function (green). The green line also accurately fits the Tokyo training examples, but also generalizes well to Texas, never preferring farther cafes.
In general, you might have many inputs about each cafe, e.g., coffee quality, price, etc. Flexible models have a hard time capturing global relationships of the form, “if all other inputs are equal, nearer is better, ” especially in parts of the feature space where your training data is sparse and noisy. Machine learning models that capture prior knowledge (e.g. how inputs should impact the prediction) work better in practice, and are easier to debug and more interpretable.
Pre-built Estimators
We provide a range of lattice model architectures as TensorFlow Estimators. The simplest estimator we provide is the calibrated linear model, which learns the best 1-d transformation of each feature (using 1-d lattices), and then combines all the calibrated features linearly. This works well if the training dataset is very small, or there are no complex nonlinear input interactions. Another estimator is a calibrated lattice model. This model combines the calibrated features nonlinearly using a two-layer single lattice model, which can represent complex nonlinear interactions in your dataset. The calibrated lattice model is usually a good choice if you have 2-10 features, but for 10 or more features, we expect you will get the best results with an ensemble of calibrated lattices, which you can train using the pre-built ensemble architectures. Monotonic lattice ensembles can achieve 0.3% -- 0.5% accuracy gain compared to Random Forests [4], and these new TensorFlow lattice estimators can achieve 0.1 -- 0.4% accuracy gain compared to the prior state-of-the-art in learning models with monotonicity [5].
Build Your Own
You may want to experiment with deeper lattice networks or research using partial monotonic functions as part of a deep neural network or other TensorFlow architecture. We provide the building blocks: TensorFlow operators for calibrators, lattice interpolation, and monotonicity projections. For example, the figure below shows a 9-layer deep lattice network [5].
Example of a 9-layer deep lattice network architecture [5], alternating layers of linear embeddings and ensembles of lattices with calibrators layers (which act like a sum of ReLU’s in Neural Networks). The blue lines correspond to monotonic inputs, which is preserved layer-by-layer, and hence for the entire model. This and other arbitrary architectures can be constructed with TensorFlow Lattice because each layer is differentiable.
In addition to the choice of model flexibility and standard L1 and L2 regularization, we offer new regularizers with TensorFlow Lattice:
Monotonicity constraints [3] on your choice of inputs as described above.
Laplacian regularization [3] on the lattices to make the learned function flatter.
Torsion regularization [3] to suppress un-necessary nonlinear feature interactions.
We hope TensorFlow Lattice will be useful to the larger community working with meaningful semantic inputs. This is part of a larger research effort on interpretability and controlling machine learning models to satisfy policy goals, and enable practitioners to take advantage of their prior knowledge. We’re excited to share this with all of you. To get started, please check out our GitHub repository and our tutorials, and let us know what you think!
By Maya Gupta, Research Scientist, Jan Pfeifer, Software Engineer and Seungil You, Software Engineer
Acknowledgements
Developing and open sourcing TensorFlow Lattice was a huge team effort. We’d like to thank all the people involved: Andrew Cotter, Kevin Canini, David Ding, Mahdi Milani Fard, Yifei Feng, Josh Gordon, Kiril Gorovoy, Clemens Mewald, Taman Narayan, Alexandre Passos, Christine Robson, Serena Wang, Martin Wicke, Jarek Wilkiewicz, Sen Zhao, Tao Zhu
We are now accepting applications for open source organizations who want to participate in Google Code-in 2017. Google Code-in, a global online contest for pre-university students ages 13-17, invites students to learn by contributing to open source software.
Working with young students is a special responsibility and each year we hear inspiring stories from mentors who participate. To ensure these new, young contributors have a great support system, we select organizations that have gained experience in mentoring students by previously taking part in Google Summer of Code.
Organizations must apply before Tuesday, October 24 at 16:00 UTC.
17 organizations were accepted last year, and over the last 7 years, 4,553 students from 99 different countries have completed more than 23,651 tasks for participating open source projects. Tasks fall into 5 categories:
Code: writing or refactoring
Documentation/Training: creating/editing documents and helping others learn more
Outreach/Research: community management, outreach/marketing, or studying problems and recommending solutions
Quality Assurance: testing and ensuring code is of high quality
User Interface: user experience research or user interface design and interaction
Once an organization is selected for Google Code-in 2017 they will define these tasks and recruit mentors who are interested in providing online support for students.
You can find a timeline, FAQ and other information about Google Code-in on our website. If you’re an educator interested in sharing Google Code-in with your students, you can find resources here.
We’re excited to announce 2017’s second round of Open Source Peer Bonus winners. Google Open Source established this program six years ago to encourage Googlers to recognize and celebrate the external developers contributing to the open source ecosystem Google depends on.
The Open Source Peer Bonus program works like this: Googlers nominate open source developers outside of the company who deserve recognition for their contributions to open source projects, including those used by Google. Nominees are reviewed by a volunteer team of engineers and the winners receive our heartfelt thanks and a small token of our appreciation.
To date, we’ve recognized nearly 600 open source contributors from dozens of countries who have contributed their time and talent to more than 400 open source projects. You can find past winners in recent blog posts: Fall 2016, Spring 2017.
Without further adieu, we’d like to recognize the latest round of winners and the projects they worked on. Here are the individuals who gave us permission to thank them publicly:
We’re headed to Vancouver this week, with about 25 Googlers who are incredibly excited to attend Node.js Interactive. With a mix of folks working on Cloud, Chrome, and V8, we’re going to be giving demos and answering questions at the Google booth.
A few of us are also going to be giving talks. Here’s a list of the talks Googlers will be giving at the conference, ranging from serverless Slack bots to JavaScript performance tuning.
Franzi is located in Munich, Germany where she works at Google on Chrome V8. Franzi, like James and Anna, is a member of the Node.js Core Technical Committee. She speaks across the globe on the topic of JavaScript virtual machines. She has a PhD in mathematics, but left academia to follow her true passion: writing code.
Franzi will discuss her perspective on Chrome V8 in Node.js, and what the Chrome V8 team is doing to continue to support Node.js. Want to know what the future of browser development looks like? This is a must-attend keynote.
If you were given a magic wand that would remove all implementation flaws from your web application, would it be free of security problems? If it took you more five seconds to say “No!” (or if, worse, you said “Yes!”), then you’re the target audience for this talk. If you’re in the target audience, don’t fret, much of the security community is there with you. After this talk, attendees will understand why the answer to the aforementioned question is an emphatic “No!” and they will learn an approach to decrease their chance of failing to consider an important vector of attack for their current and future web applications.
This year, V8 launched Ignition and Turbofan, the new compiler pipeline that handles all JavaScript code generation. Previously, achieving high performance in Node.js meant catering to the oddities of our now-deprecated Crankshaft compiler. This talk covers our new code generation architecture - what makes it special, a bit about how it works, and how to write high performance code for the new V8 pipeline.
Ever since v8-inspector was moved to V8's repository, we have been working on a number of new features for DevTools, usable for both Chrome and Node.js. The talk will demonstrate code coverage, type profiling, and give a deep dive into how evaluating a code snippet in DevTools console works in V8.
Memory leaks are hard. This talk with introduce developers to what memory leaks are, how they can exist in a garbage collected language, the available tooling that can help them understand and isolate memory leaks in their code. Specifically it will talk about heap snapshots, the new sampling heap profiler in V8, and other various other tools available in the ecosystem.
This talk will show you how to build both voice and chat bots using serverless technologies. Amir Shevat, Head of Developer Relations at Slack, has overseen 17K+ bots deployed on the platform. He will present a maturing model, as best practices, for enterprise bots covering all sorts of use cases ranging for devops, HR, and marketing. Alan Ho from Google Cloud will then show you how to use various serverless technologies to build these bots. He’ll give you a demo of Slack and Google Assistant bots incorporating Google’s latest serverless technology including Edge (API Management), CloudFunctions (Serverless Compute), Cloud Datastore, and API.ai.
ES Modules and Common JS go together like old bay seasoning and vanilla ice cream. This talk will dig into the inconsistencies of the two patterns, and how the Node.js project is dealing with reconciling the problem. The talk will look at the history of modules in the JavaScript ecosystem and the subtle difference between them. It will also skim over how ECMA-262 is standardized by the TC39, and how ES Modules were developed.
Node.js has had a transformational effect on the way we build software. However, convincing your organization to take a bet on Node.js can be difficult. My personal journey with Node.js has included convincing a few teams to take a bet on this technology, and this community. Let’s take a look at the case for Node.js we made at Google, and how you can make the case to bring it to your organization.
We can’t wait to see everyone and have some great conversations. Feel free to reach out to us on Twitter @googlecloud, or request an invite to the Google Cloud Slack community and join the #nodejs channel.
Today we are open sourcing Abseil, a collection of libraries drawn from the most fundamental pieces of Google’s internal codebase. These libraries are the nuts-and-bolts that underpin almost everything that Google runs. Bits and pieces of these APIs are embedded in most of our open source projects, and now we have brought them together into one comprehensive project. Abseil encompasses the most basic building blocks of Google’s codebase: code that is production tested and will be fully maintained for years to come.
By adopting these new Apache-licensed libraries, you can reap the benefit of years (over a decade in many cases) of our design and optimization work in this space. Our past experience is baked in.
Just as interesting, we’ve also prepared for the future: several types in Abseil’s C++ libraries are “pre-adoption” versions of C++17 types like string_view and optional - implemented in C++11 to the greatest extent possible. We look forward to moving more and more of our code to match the current standard, and using these new vocabulary types helps us make that transition. Importantly, in C++17 mode these types are merely aliases to the standard, ensuring that you only ever have one type for optional or string_view in a project at a time. Put another way: Abseil is focused on the engineering task of providing APIs that remain stable over time.
Consisting of the foundational C++ and Python code at Google, Abseil includes libraries that will grow to underpin other Google-backed open source projects like gRPC, Protobuf and TensorFlow. We love those projects, and we love the users of those projects - we want to ensure smooth usage for these things over time. In the next few months we’ll introduce new distribution methods to incorporate these projects as a collection into your project.
Continuing with the “over time” theme, Abseil aims for compatibility with major compilers, platforms and standard libraries for approximately 5 years. Our 5-year target also applies to language version: we assume everyone builds with C++11 at this point. (In 2019 we’ll start talking about requiring C++14 as our base language version.) This 5-year horizon is part of our balance between “support everything” and “provide modern implementations and APIs.”
Highlights of the initial release include:
Zero configuration: most platforms (OS, compiler, architecture) should just work.
Our primary synchronization type, absl::Mutex, has an elegant interface and has been extensively optimized.
Efficient support for handling time: absl::Time and absl::Duration are conceptually similar to std::chrono types, but are concrete (not class templates) and have defined behavior in all cases. Additionally, our clock-sampling API absl::Now() is more heavily optimized than most standard library calls for std::chrono::system_clock::now().
String handling routines: among internal users, we’ve been told that releasing absl::StrCat(), absl::StrJoin(), and absl::StrSplit() would itself be a big improvement for the open source C++ world.
The project has support for C++ and some Python. Over time we’ll tie those two projects together more closely with shared logging and command-line flag infrastructure. To start contributing, please see our contribution guidelines and fork us on GitHub. Check out our documentation and community page for information on how to contact us, ask questions or contribute to Abseil.
Google Open Source is proud to announce the 14th year of Google Summer of Code (GSoC)! Yes, GSoC is officially well into its teenage years - hopefully without that painful awkward stage - and we are excited to introduce more new student developers to the world of open source software development.
Over the last 13 years GSoC has provided over 13,000 university students from around the world with an opportunity to hone their skills by contributing to open source projects during their summer break. Participants gain invaluable experience working directly with mentors on open source projects, and earn a stipend upon successful completion of their project.
We’re excited to keep the tradition going! Applications for interested open source organizations open on January 4, 2018 and student applications open in March*.
Are you an open source project interesting in learning more? Visit the program site to learn about what it means to be a mentor organization and how to submit a good application. We welcome all types of organizations - both large and small - and each year about 20% of the organizations we accept are completely new to GSoC.
Students, it’s never too early to start thinking about your proposal. You can check out the organizations that participated in Google Summer of Code 2017 as well as the projects students worked on. We also encourage you to explore other resources like the student and mentor guides and frequently asked questions.
You can always learn more on the program website. Please stay tuned for more details!
Applications often require access to small pieces of sensitive data at build or run time, referred to as secrets. Secrets are generally more sensitive than other environment variables or parts of your repository as they may grant access to additional data, such as user information.
HashiCorp Vault is a popular open source tool for secret management, which allows a developer to store, manage and control access to tokens, passwords, certificates, API keys and other secrets. Vault has authentication backends, which allow developers to use many kinds of identities to access Vault, including tokens, or usernames and passwords.
The following example shows how a user can enable and configure the GCP auth backend and then authenticate an instance with Vault. See the docs to learn more.
In the following example, an admin mounts the backend at auth/gcp and adds:
Credentials that the backend can use to verify the instance (requiring some read-only permissions)
A Vault-specific role (roles determine what Vault secrets the authenticating GCE VM instance can access, and can restrict login to a set of instances by zone or region, instance group, or GCP labels)
# Mount the backend at ‘auth/gcp’. $ vault auth-enable ‘gcp’ ...
# Add configuration. This can include credentials Vault will # use to make calls to GCP APIs to verify authenticating instances. $ vault write auth/gcp/config credentials=@path/to/creds.json ...
# Add configuration. This can include credentials Vault will # use to make calls to GCP APIs to verify authenticating instances. $ vault write auth/gcp/role/my-gce-role \ type='gce' \ policies=’dev,prod’ \ project_id=”project-123456” \ zone="us-central1-c" instance_group=”my-instance-group” \ labels=”foo:bar,prod:true,...” \ ...
Then, a Compute Engine instance can authenticate to the Vault server using the following script:
#! /bin/bash
# [START PARAMS] # Subtitute real vault address or env variable. VAULT_ADDR="https://vault.rocks"
# Substitute another service account for the VM instance or use the # built-in default. SERVICE_ACCOUNT="default"
# The instance will attempt login under this role. ROLE="my-gce-role" # [END PARAMS]
# Generate a metadata identity token JWT with the expected audience. # The GCP backend expect a JWT 'aud' claim ending in “vault/$ROLE”. AUD="$VAULT_ADDR/vault/$ROLE" TOKEN="$(curl -H "Metadata-Flavor: Google" \ http://metadata/computeMetadata/v1/instance/service-accounts/default/identity?audience=$AUD&format=full)"
We are excited to announce the 8th consecutive year of the Google Code-in (GCI) contest! Students ages 13 through 17 from around the world can learn about open source development working on real open source projects, with mentorship from active developers. GCI begins on Tuesday, November 28, 2017 and runs for seven weeks through to Wednesday, January 17, 2018.
Google Code-in is unique because not only do the students choose what they want to work on from the 2,000+ tasks created by open source organizations, but they have mentors available to help answer their questions as they work on each of their tasks.
Starting to work on open source software can be a daunting task in and of itself. How do I get started? Does the organization want my help? Am I too inexperienced? These are all questions that developers (of all ages) might consider before contributing to an open source organization.
The beauty of GCI is that participating open source organizations realize teens are often first time contributors, and the volunteer mentors are equipped with the patience and the experience to help these young minds become part of the open source community.
Open source communities thrive when there is a steady flow of new contributors who bring new perspectives, ideas, and enthusiasm. Over the last 7 years, GCI open source organizations have helped over 4,500 students from 99 countries become contributors. Many of these students are still contributing to open source years later. Dozens have gone on to become Google Summer of Code (GSoC) students and even mentors for other students.
The tasks open source organizations create vary in skill set and level, including beginner tasks any student can take on, such as “setup your development environment.” With tasks in five different categories, there’s something to fit almost any student’s skills:
Code: writing or refactoring
Documentation/Training: creating/editing documents and helping others learn more
Outreach/Research: community management, marketing, or studying problems and recommending solutions
Quality Assurance: testing and ensuring code is of high quality
User Interface: user experience research, user interface design, or graphic design
Open source organizations can apply to participate in Google Code-in starting on Monday, October 9, 2017. Google Code-in starts for students November 28th!
Visit the contest site g.co/gci to learn more about the contest and find flyers, slide decks, timelines and more.