By Travis Tomsu, Software Engineer, Spinnaker Team
Building a Java application requires a lot of files — source code, application libraries, build systems, build system dependencies and of course, the JDK. When you containerize an application, these files sometimes get left in, causing bloat. Over time, this bloat costs you both time and money by storing and moving unnecessary bits between your Docker registry and your container runtime.
A better way to help ensure your container is as small as possible is to separate the building of the application (and the tools needed to do so) from the assembly of the runtime container. Using
Google Cloud Container Builder, we can do just that, allowing us to build significantly leaner containers. These lean containers load faster and save on storage costs.
Container layers
Each line in a Dockerfile adds a new layer to a container. Let’s look at an example:
FROM busybox
COPY ./lots-of-data /data
RUN rm -rf /data
CMD ["/bin/sh"]
In this example, we copy the local directory, "lots-of-data", to the "data" directory in the container, and then immediately delete it. You might assume such an operation is harmless, but that's not the case.
The reason is because of Docker’s “
copy-on-write” strategy, which makes all previous layers read-only. If each successive command generates data that's not needed at container
runtime, nor deleted in the same command, that space cannot be reclaimed.
Spinnaker containers
Spinnaker is an open source, cloud-focused continuous delivery tool created by Netflix. Spinnaker is actively maintained by a community of partners, including Netflix and Google. It has a microservice architecture, with each component written in Groovy and Java, and uses Gradle as its build tool.
Spinnaker publishes each microservice container on Quay.io. Each service has nearly identical Dockerfiles, so we’ll use the
Gate service as the example. Previously, we had a Dockerfile that looked like this:
FROM java:8
COPY . workdir/
WORKDIR workdir
RUN GRADLE_USER_HOME=cache ./gradlew buildDeb -x test
RUN dpkg -i ./gate-web/build/distributions/*.deb
CMD ["/opt/gate/bin/gate"]
With Spinnaker, Gradle is used to do the build, which in this case builds a Debian package. Gradle is a great tool, but it downloads a large number of libraries in order to function. These libraries are essential to the building of the package, but aren’t needed at runtime. All of the runtime dependencies are bundled up in the package itself.
As discussed before, each command in the Dockerfile creates a new layer in the container. If data is generated in that layer and not deleted in the same command, that space cannot be recovered. In this case, Gradle is downloading hundreds of megabytes of libraries to the "cache" directory in order to perform the build, but we're not deleting those libraries.
A more efficient way to perform this build is to merge the two “RUN” commands, and remove all of the files (including the source code) when complete:
FROM java:8
COPY . workdir/
WORKDIR workdir
RUN GRADLE_USER_HOME=cache ./gradlew buildDeb -x test && \
dpkg -i ./gate-web/build/distributions/*.deb && \
cd .. && \
rm -rf workdir
CMD ["/opt/gate/bin/gate"]
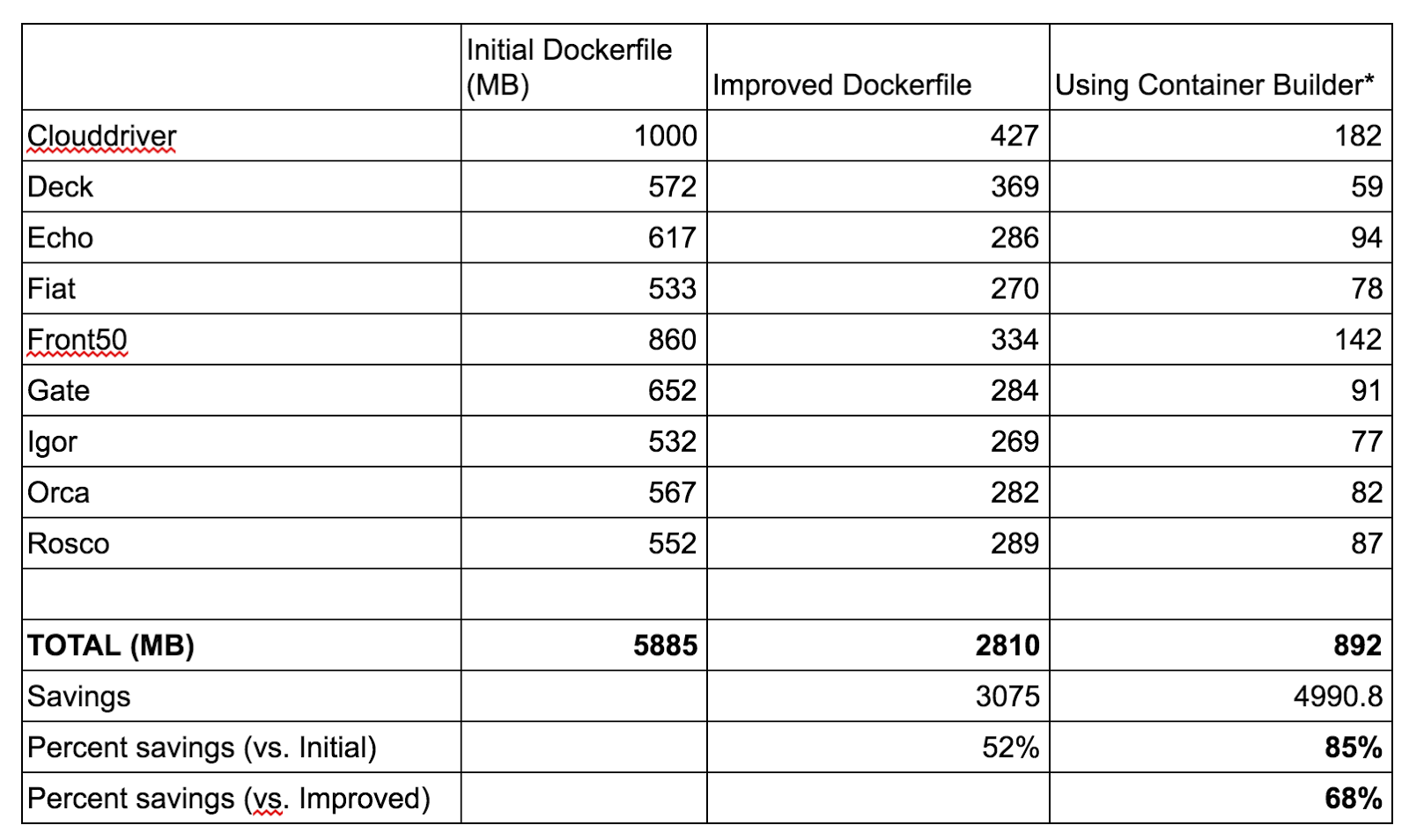
This took the final container size down from 652MB to 284MB, a savings of 56%. But can we do even better?
Enter Container Builder
Using
Container Builder, we're able to further separate building the application from building its runtime container.
The Container Builder team
publishes and maintains a series of Docker containers with common developer tools such as git, docker and the gcloud command line interface. Using these tools, we’ll define a "cloudbuild.yaml" file with one step to build the application, and another to assemble its final runtime environment.
Here's the "cloudbuild.yaml" file we'll use:
steps:
- name: 'java:8'
env: ['GRADLE_USER_HOME=cache']
entrypoint: 'bash'
args: ['-c', './gradlew gate-web:installDist -x test']
- name: 'gcr.io/cloud-builders/docker'
args: ['build',
'-t', 'gcr.io/$PROJECT_ID/$REPO_NAME:$COMMIT_SHA',
'-t', 'gcr.io/$PROJECT_ID/$REPO_NAME:latest',
'-f', 'Dockerfile.slim', '.']
images:
- 'gcr.io/$PROJECT_ID/$REPO_NAME:$COMMIT_SHA'
- 'gcr.io/$PROJECT_ID/$REPO_NAME:latest'
Let’s go through each step and explore what is happening.
Step 1: Build the application
- name: 'java:8'
env: ['GRADLE_USER_HOME=cache']
entrypoint: 'bash'
args: ['-c', './gradlew gate-web:installDist -x test']
Our lean runtime container doesn’t contain "dpkg", so we won't use the "buildDeb" Gradle task. Instead, we use a different task, "installDist", which creates the same directory hierarchy for easy copying.
Step 2: Assemble the runtime container
- name: 'gcr.io/cloud-builders/docker'
args: ['build',
'-t', 'gcr.io/$PROJECT_ID/$REPO_NAME:$COMMIT_SHA',
'-t', 'gcr.io/$PROJECT_ID/$REPO_NAME:latest',
'-f', 'Dockerfile.slim', '.']
Next, we invoke the Docker build to assemble the runtime container. We'll use a different file to define the runtime container, named "Dockerfile.slim". Its contents are below:
FROM openjdk:8u111-jre-alpine
COPY ./gate-web/build/install/gate /opt/gate
RUN apk --nocache add --update bash
CMD ["/opt/gate/bin/gate"]
The output of the "installDist" Gradle task from Step 1 already has the directory hierarchy we want (i.e. "gate/bin/", "gate/lib/", etc), so we can simply copy it into our target container.
One of the major savings is the choice of the Alpine Linux base layer, "openjdk:8u111-jre-alpine". Not only is this layer incredibly lean, but we also choose to only include the JRE, instead of the bulkier JDK that was necessary to build the application.
Step 3: Publish the image to the registry
images:
- 'gcr.io/$PROJECT_ID/$REPO_NAME:$COMMIT_SHA'
- 'gcr.io/$PROJECT_ID/$REPO_NAME:latest'
Lastly, we tag the container with the commit hash and crown it as the "latest" container. We then push this container to our Google Cloud Container Registry (grc.io) with these tags.
Conclusion
In the end, using Container Builder resulted in a final container size of 91.6MB, which is 85% smaller than our initial Dockerfile and even 68% smaller than our improved version.
*The major savings comes from separating the build and runtime environments, and from choosing a lean base layer for the final container.
Applying this approach across each microservice yielded similar results; our sum total container footprint shrunk from almost 6GB down to less than 1GB.