The promise and benefit of the cloud has always been flexibility, low cost, and pay-per-use. With Google Compute Engine, custom machine types let you create VM instances of any size and shape, and we automatically apply committed use and sustained use discounts to reduce your costs. Today, we are taking the concept of pay-for-use in Compute Engine even further with resource-based pricing.
With resource-based pricing we are making a number of changes behind the scenes that align how we treat metering of custom and predefined machine types, as well as how we apply discounts for sustained use discounts. Simply put, we’ve made changes to automatically provide you with more savings and an easy-to-understand monthly bill. Who doesn’t love that?
Resource-based pricing considers usage at a granular level. Instead of evaluating your usage based on which machine types you use, it evaluates how many resources you consume over a given time period. What does that mean? It means that a core is a core, and a GB of RAM is a GB of RAM. It doesn’t matter what combination of pre-defined machine types you are running. Now we look at them at the resource level—in the aggregate. It gets better, too, because sustained use discounts are now calculated regionally, instead of just within zones. That means you can accrue sustained use discounts even faster, so you can save even more automatically.
To better understand these changes, and to get an idea of how you can save, let’s take a look at how sustained use discounts worked previously, and how they’ll work moving forward.
- Previously, if you used a specific machine type (e.g. n1-standard-4) with four vCPUs for 50% of the month, you got an effective discount of 10%. If you used it for 75% of the month, you got an effective discount of 20%. If you use it for 100% of the month, you got an effective discount of 30%.
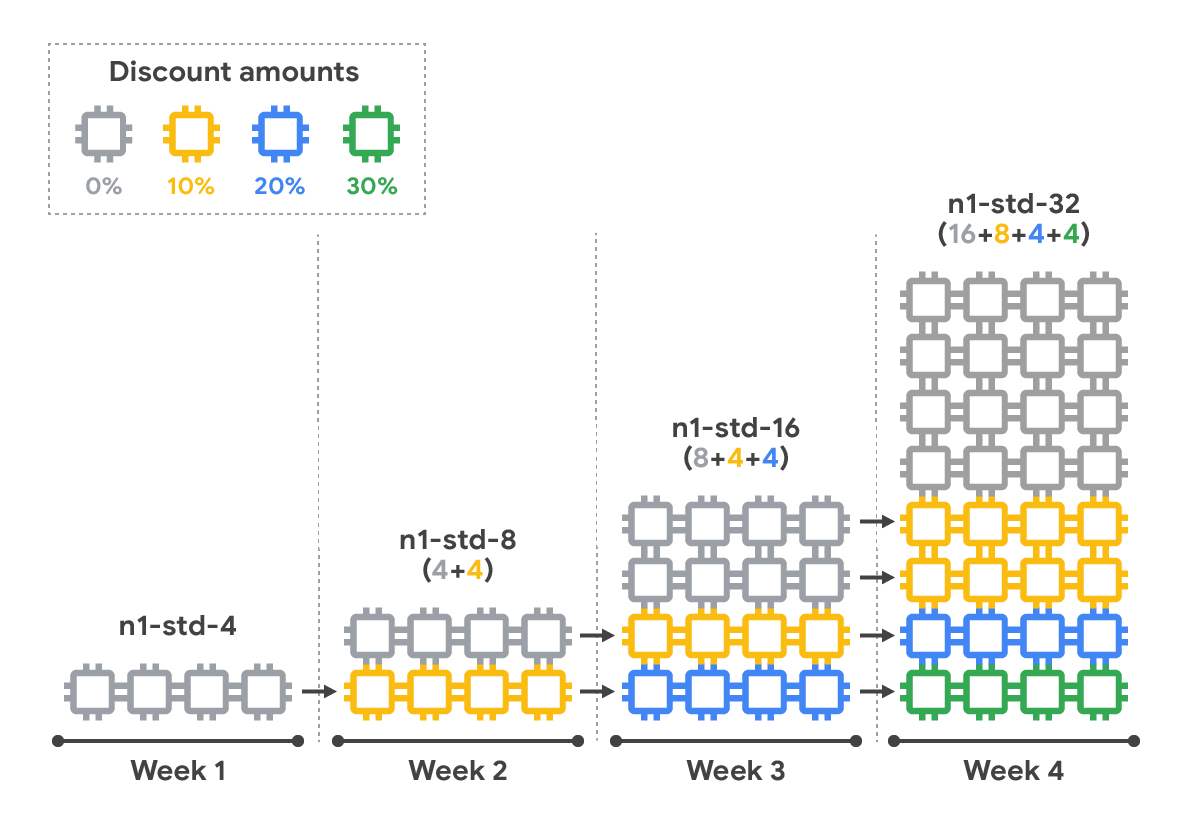
- Let’s say you were running a web-based service. You started the month running an n1-standard-4 with four vCPUs. In the second week user demand for your service increased and you scaled capacity. You started running an n1-standard-8 with eight vCPU. Ever increasing demand caused you to scale up again. In week three you began running an n1-standard-16 with sixteen vCPU. Due to your success you wound up scaling again—ending the month running an n1-standard-32 with thirty-two vCPU. In this scenario you wouldn’t receive any discount, because you didn’t run any of the machine types for up to 50% of the month.

With resource-based pricing, we no longer consider your machine type and instead, we add up all the resources you use across all your machines into a single total and then apply the discount. You do not need to take any action. You save automatically. Let’s look at the scaling example again, but this time with resource-based pricing.
- You began the month running four vCPU, and subsequently scaled to eight vCPU, sixteen vCPU and finally thirty-two vCPU. You ran four vCPU all month, or 100% of the time, so you receive a 30% discount on those vCPU. You ran another four vCPU for 75% of the month, so you receive a 20% discount on those vCPU. And finally, you ran another eight vCPU for half the month, so you receive a 10% discount on those vCPU. Sixteen vCPU were run for one week, so they did not qualify for a discount. Let’s visualize how this works, to reinforce what we’ve learned.
And because resource-based pricing applies at a regional level, it’s now even easier for you to benefit from sustained use discounts, no matter which machine types you use, or the number of zones in a region in which you operate. Resource-based pricing will take effect in the coming months. Visit the Resource-based pricing page to learn more.