Originally posted on the Google Research Blog
By Slav Petrov, Senior Staff Research ScientistAt Google, we spend a lot of time thinking about how
computer systems can
read and
understand human language in order
to process it in
intelligent ways. Today, we are excited to share the fruits of our research with the broader community by releasing
SyntaxNet, an open-source neural network framework implemented in
TensorFlow that provides a foundation for
Natural Language Understanding (NLU) systems. Our release includes all the code needed to train new SyntaxNet models on your own data, as well as
Parsey McParseface, an English parser that we have trained for you and that you can use to analyze English text.
Parsey McParseface is built on powerful machine learning algorithms that learn to analyze the linguistic structure of language, and that can explain the functional role of each word in a given sentence. Because Parsey McParseface is the
most accurate such model in the world, we hope that it will be useful to developers and researchers interested in automatic extraction of information, translation, and other core applications of NLU.
How does SyntaxNet work?SyntaxNet is a framework for what’s known in academic circles as a
syntactic parser, which is a key first component in many NLU systems. Given a sentence as input, it tags each word with a part-of-speech (POS) tag that describes the word's syntactic function, and it determines the syntactic relationships between words in the sentence, represented in the dependency parse tree. These syntactic relationships are directly related to the underlying meaning of the sentence in question. To take a very simple example, consider the following dependency tree for
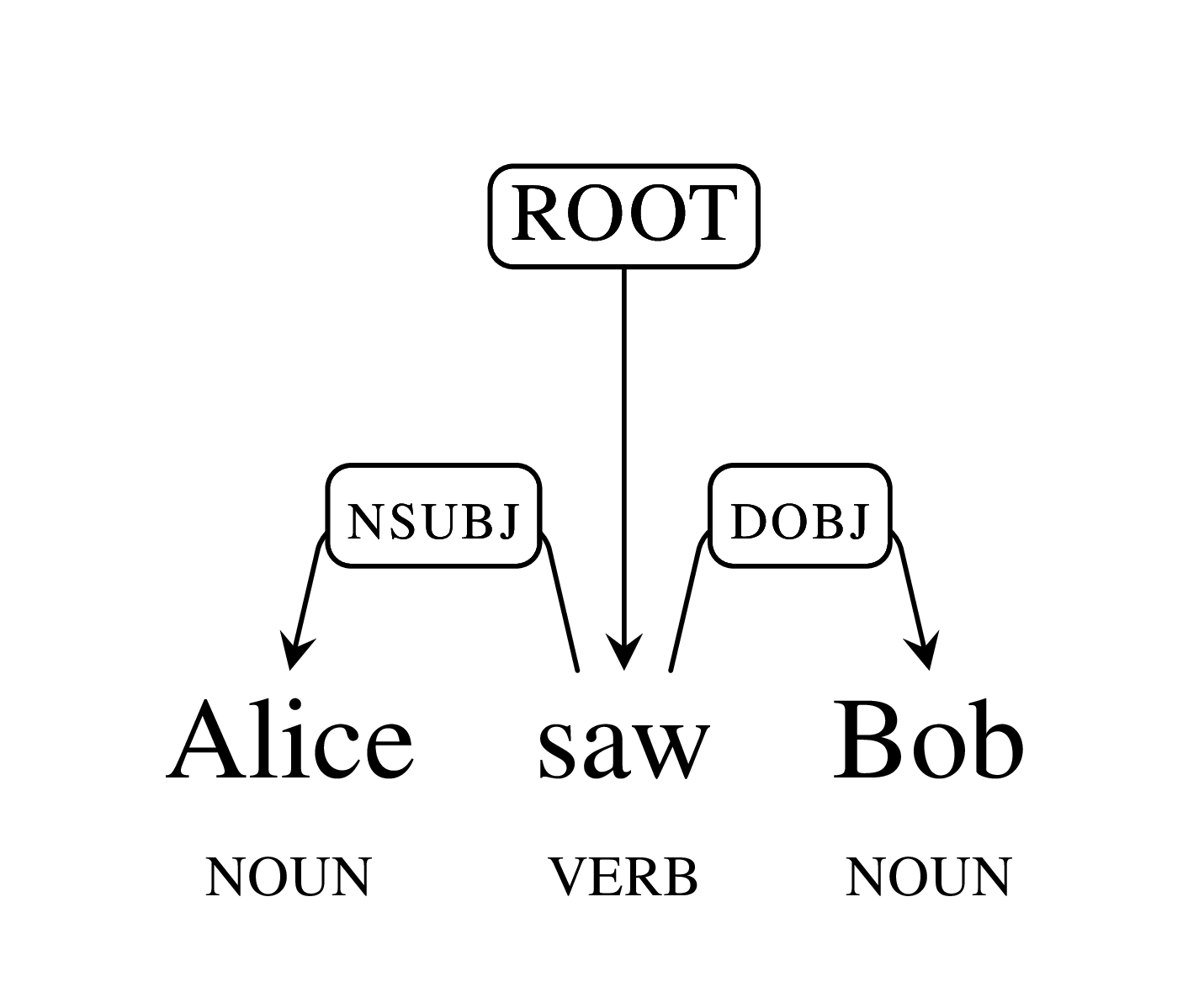
Alice saw Bob:
This structure encodes that
Alice and
Bob are nouns and
saw is a verb. The main verb
saw is the root of the sentence and
Alice is the subject (nsubj) of
saw, while
Bob is its direct object (dobj). As expected, Parsey McParseface analyzes this sentence correctly, but also understands the following more complex example:
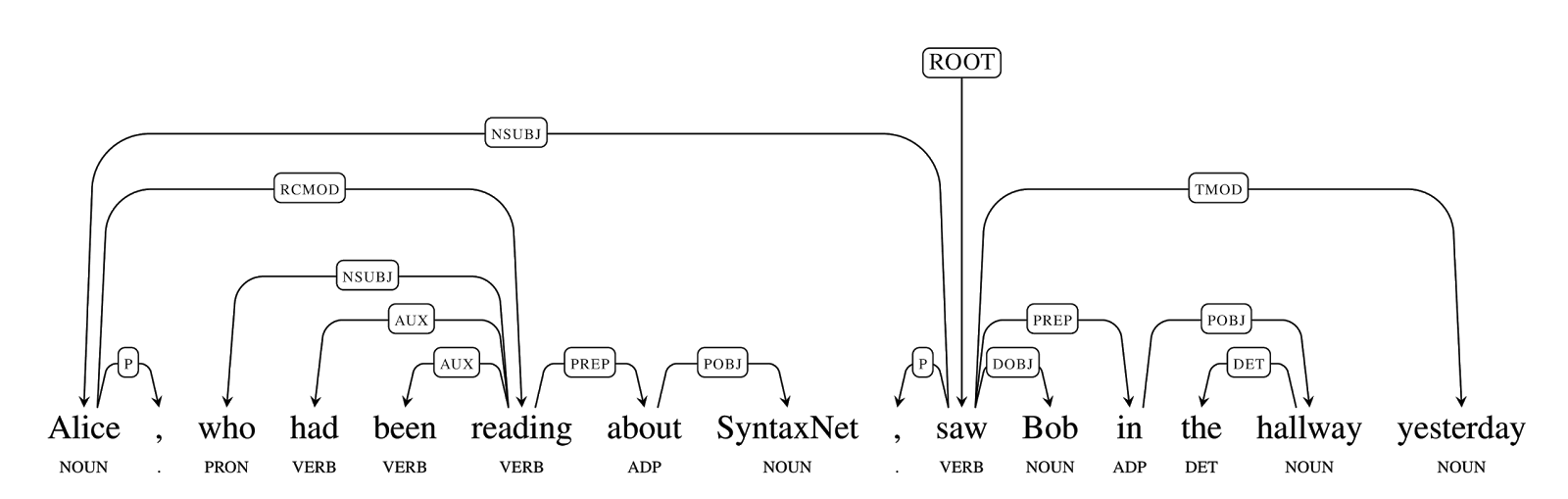
This structure again encodes the fact that
Alice and
Bob are the subject and object respectively of
saw, in addition that
Alice is modified by a relative clause with the verb
reading, that
saw is modified by the temporal modifier
yesterday, and so on. The grammatical relationships encoded in dependency structures allow us to easily recover the answers to various questions, for example
whom did Alice see?,
who saw Bob?,
what had Alice been reading about? or
when did Alice see Bob?.
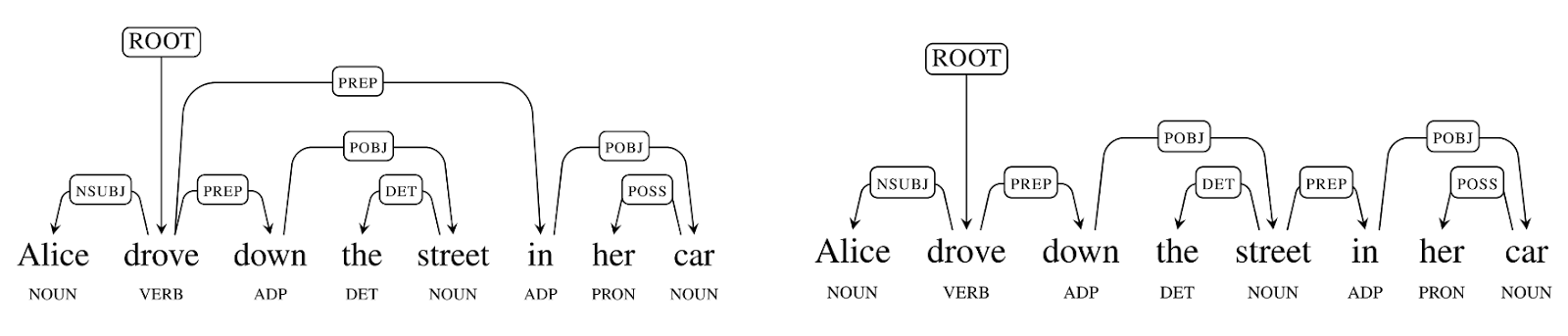
Why is Parsing So Hard For Computers to Get Right?One of the main problems that makes parsing so challenging is that human languages show remarkable levels of ambiguity. It is not uncommon for moderate length sentences - say 20 or 30 words in length - to have hundreds, thousands, or even tens of thousands of possible syntactic structures. A natural language parser must somehow search through all of these alternatives, and find the most plausible structure given the context. As a very simple example, the sentence
Alice drove down the street in her car has at least two possible dependency parses:
The first corresponds to the (correct) interpretation where Alice is driving in her car; the second corresponds to the (absurd, but possible) interpretation where the street is located in her car. The ambiguity arises because the preposition
in can either modify
drove or
street; this example is an instance of what is called
prepositional phrase attachment ambiguity.
Humans do a remarkable job of dealing with ambiguity, almost to the point where the problem is unnoticeable; the challenge is for computers to do the same. Multiple ambiguities such as these in longer sentences conspire to give a combinatorial explosion in the number of possible structures for a sentence. Usually the vast majority of these structures are wildly implausible, but are nevertheless possible and must be somehow discarded by a parser.
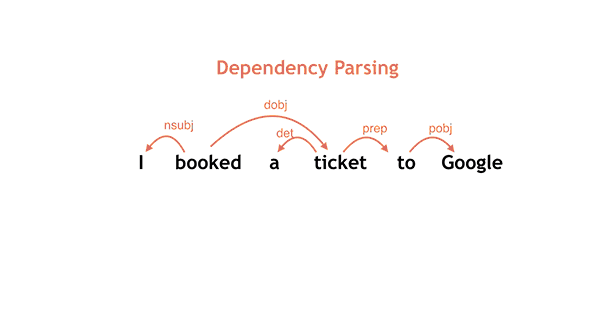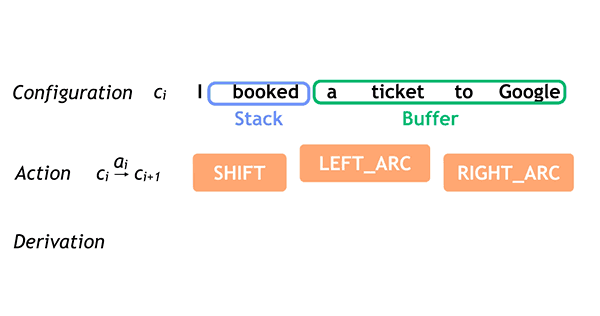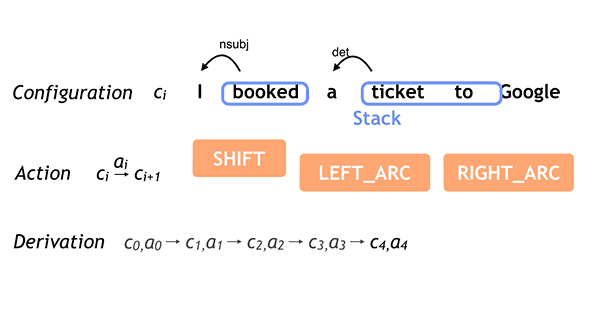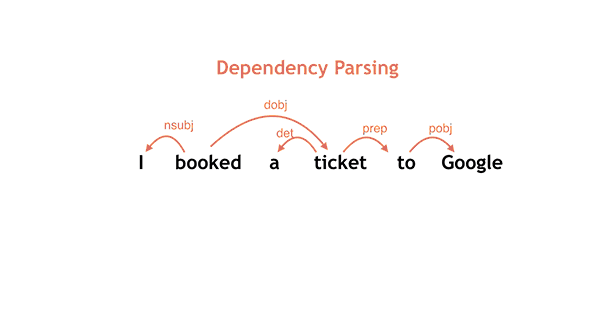
SyntaxNet applies neural networks to the ambiguity problem. An input sentence is processed from left to right, with dependencies between words being incrementally added as each word in the sentence is considered. At each point in processing many decisions may be possible—due to ambiguity—and a neural network gives scores for competing decisions based on their plausibility. For this reason, it is very important to use
beam search in the model. Instead of simply taking the first-best decision at each point, multiple partial hypotheses are kept at each step, with hypotheses only being discarded when there are several other higher-ranked hypotheses under consideration. An example of a left-to-right sequence of decisions that produces a simple parse is shown below for the sentence
I booked a ticket to Google.
Furthermore, as described in our
paper, it is critical to tightly
integrate learning and search in order to achieve the highest prediction accuracy. Parsey McParseface and other
SyntaxNet models are some of the most complex networks that we have trained with the
TensorFlow framework at Google. Given some data from the Google supported
Universal Treebanks project, you can train a parsing model on your own machine.
So How Accurate is Parsey McParseface?On a standard benchmark consisting of randomly drawn English newswire sentences (the 20 year old
Penn Treebank), Parsey McParseface recovers individual dependencies between words with over 94% accuracy, beating our own previous state-of-the-art results, which were already
better than any previous approach. While there are no explicit studies in the literature about human performance, we know from our in-house annotation projects that linguists trained for this task agree in 96-97% of the cases. This suggests that we are approaching human performance—but only on well-formed text. Sentences drawn from the web are a lot harder to analyze, as we learned from the
Google WebTreebank (released in 2011). Parsey McParseface achieves just over 90% of parse accuracy on this dataset.
While the accuracy is not perfect, it’s certainly high enough to be useful in many applications. The major source of errors at this point are examples such as the prepositional phrase attachment ambiguity described above, which require real world knowledge (e.g. that a street is not likely to be located in a car) and deep contextual reasoning. Machine learning (and in particular, neural networks) have made significant progress in resolving these ambiguities. But our work is still cut out for us: we would like to develop methods that can learn world knowledge and enable equal understanding of natural language across
all languages and contexts.
To get started, see the
SyntaxNet code and download the Parsey McParseface parser model. Happy parsing from the main developers, Chris Alberti, David Weiss, Daniel Andor, Michael Collins & Slav Petrov.