 Learn more about our latest Pixel Drop, which includes new features like Pixel VIPs and Expressive Captions.
Learn more about our latest Pixel Drop, which includes new features like Pixel VIPs and Expressive Captions.
Pixel VIPs, Android 16 and more updates in the June Pixel Drop
Learn more about our latest Pixel Drop, which includes new features like Pixel VIPs and Expressive Captions.
 Pixel VIPs just landed with our June Pixel Drop. This new Contacts app widget lets you keep your closest family and friends even closer, displaying details like your las…
Pixel VIPs just landed with our June Pixel Drop. This new Contacts app widget lets you keep your closest family and friends even closer, displaying details like your las…
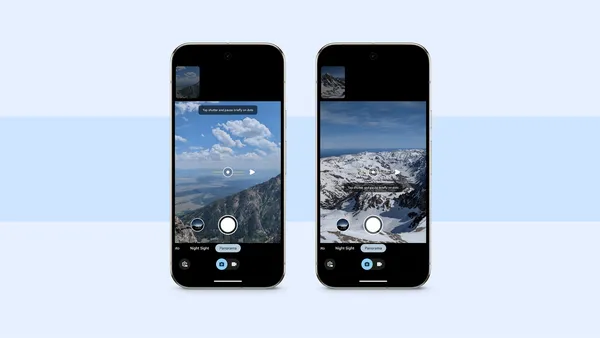 Learn more about Google Pixel’s new panorama mode as well as three tips on using it.
Learn more about Google Pixel’s new panorama mode as well as three tips on using it.
 Learn more about the Fitbit app’s running features that can track and analyze your running performance.
Learn more about the Fitbit app’s running features that can track and analyze your running performance.
 Pixel 9a is here! At just $499, our latest A-series device is packed with unbeatable value. It has a sleek, brand new design, the brightest display on an A-series ever a…
Pixel 9a is here! At just $499, our latest A-series device is packed with unbeatable value. It has a sleek, brand new design, the brightest display on an A-series ever a…
 Here are Google’s latest AI updates from March 2025.
Here are Google’s latest AI updates from March 2025.
 Learn more about Google’s latest Pixel A-series phone, Pixel 9a.
Learn more about Google’s latest Pixel A-series phone, Pixel 9a.