Many Google products (e.g., the Google Assistant, Search, Maps) come with built-in high-quality text-to-speech synthesis that produces natural sounding speech. Developers have been telling us they’d like to add text-to-speech to their own applications, so today we’re bringing this technology to Google Cloud Platform with Cloud Text-to-Speech.
To power voice response systems for call centers (IVRs) and enabling real-time natural language conversations
To enable IoT devices (e.g., TVs, cars, robots) to talk back to you
To convert text-based media (e.g., news articles, books) into spoken format (e.g., podcast or audiobook)
Cloud Text-to-Speech lets you choose from 32 different voices from 12 languages and variants. Cloud Text-to-Speech correctly pronounces complex text such as names, dates, times and addresses for authentic sounding speech right out of the gate. Cloud Text-to-Speech also allows you to customize pitch, speaking rate, and volume gain, and supports a variety of audio formats, including MP3 and WAV.
Rolling in the DeepMind
In addition, we're excited to announce that Cloud Text-to-Speech also includes a selection of high-fidelity voices built using WaveNet, a generative model for raw audio created by DeepMind. WaveNet synthesizes more natural-sounding speech and, on average, produces speech audio that people prefer over other text-to-speech technologies.
In late 2016, DeepMind introduced the first version of WaveNet — a neural network trained with a large volume of speech samples that's able to create raw audio waveforms from scratch. During training, the network extracts the underlying structure of the speech, for example which tones follow one another and what shape a realistic speech waveform should have. When given text input, the trained WaveNet model generates the corresponding speech waveforms, one sample at a time, achieving higher accuracy than alternative approaches.
Fast forward to today, and we're now using an updated version of WaveNet that runs on Google’s Cloud TPU infrastructure.The new, improved WaveNet model generates raw waveforms 1,000 times faster than the original model, and can generate one second of speech in just 50 milliseconds. In fact, the model is not just quicker, but also higher-fidelity, capable of creating waveforms with 24,000 samples a second. We’ve also increased the resolution of each sample from 8 bits to 16 bits, producing higher quality audio for a more human sound.
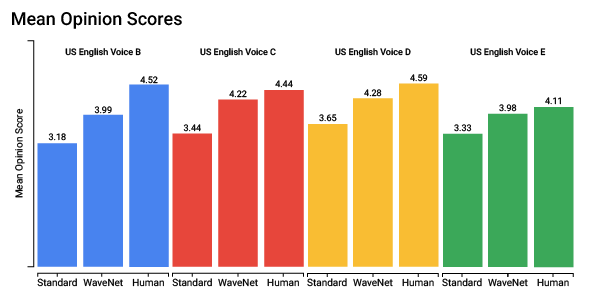
With these adjustments, the new WaveNet model produces more natural sounding speech. In tests, people gave the new US English WaveNet voices an average mean-opinion-score (MOS) of 4.1 on a scale of 1-5 — over 20% better than for standard voices and reducing the gap with human speech by over 70%. As WaveNet voices also require less recorded audio input to produce high quality models, we expect to continue to improve both the variety as well as quality of the WaveNet voices available to Cloud customers in the coming months.
Cloud Text-to-Speech is already helping multiple customers deliver a better experience to their end users. Customers include Cisco and Dolphin ONE.
“As the leading provider of collaboration solutions, Cisco has a long history of bringing the latest technology advances into the enterprise. Google’s Cloud Text-to-Speech has enabled us to achieve the natural sound quality that our customers desire."
— Tim Tuttle, CTO of Cognitive Collaboration, Cisco
“Dolphin ONE’s Calll.io telephony platform offers connectivity from a multitude of devices, at practically any location. We’ve integrated Cloud Text-to-Speech into our products and allow our users to create natural call center experiences. By using Google Cloud’s machine learning tools, we’re instantly delivering cutting-edge technology to our users.”
—Jason Berryman, Dolphin ONE
Get started today
With Cloud Text-to-Speech, you’re now a few clicks away from one of the most advanced speech technologies in the world. To learn more, please visit the documentation or our pricing page. To get started with our public beta or try out the new voices, visit the Cloud Text-to-Speech website.
By John Barrus, Product Manager for Cloud TPUs, Google Cloud and Zak Stone, Product Manager for TensorFlow and Cloud TPUs, Google Brain Team
Starting today, Cloud TPUs are available in beta on Google Cloud Platform (GCP) to help machine learning (ML) experts train and run their ML models more quickly.
Cloud TPUs are a family of Google-designed hardware accelerators that are optimized to speed up and scale up specific ML workloads programmed with TensorFlow. Built with four custom ASICs, each Cloud TPU packs up to 180 teraflops of floating-point performance and 64 GB of high-bandwidth memory onto a single board. These boards can be used alone or connected together via an ultra-fast, dedicated network to form multi-petaflop ML supercomputers that we call “TPU pods.” We will offer these larger supercomputers on GCP later this year.
We designed Cloud TPUs to deliver differentiated performance per dollar for targeted TensorFlow workloads and to enable ML engineers and researchers to iterate more quickly. For example:
Instead of waiting for a job to schedule on a shared compute cluster, you can have interactive, exclusive access to a network-attached Cloud TPU via a Google Compute Engine VM that you control and can customize.
Rather than waiting days or weeks to train a business-critical ML model, you can train several variants of the same model overnight on a fleet of Cloud TPUs and deploy the most accurate trained model in production the next day.
Using a single Cloud TPU and following this tutorial, you can train ResNet-50 to the expected accuracy on the ImageNet benchmark challenge in less than a day, all for well under $200!
ML model training, made easy
Traditionally, writing programs for custom ASICs and supercomputers has required deeply specialized expertise. By contrast, you can program Cloud TPUs with high-level TensorFlow APIs, and we have open-sourced a set of reference high-performance Cloud TPU model implementations to help you get started right away:
To save you time and effort, we continuously test these model implementations both for performance and for convergence to the expected accuracy on standard datasets.
Over time, we'll open-source additional model implementations. Adventurous ML experts may be able to optimize other TensorFlow models for Cloud TPUs on their own using the documentation and tools we provide.
By getting started with Cloud TPUs now, you’ll be able to benefit from dramatic time-to-accuracy improvements when we introduce TPU pods later this year. As we announced at NIPS 2017, both ResNet-50 and Transformer training times drop from the better part of a day to under 30 minutes on a full TPU pod, no code changes required.
Two Sigma, a leading investment management firm, is impressed with the performance and ease of use of Cloud TPUs.
"We made a decision to focus our deep learning research on the cloud for many reasons, but mostly to gain access to the latest machine learning infrastructure. Google Cloud TPUs are an example of innovative, rapidly evolving technology to support deep learning, and we found that moving TensorFlow workloads to TPUs has boosted our productivity by greatly reducing both the complexity of programming new models and the time required to train them. Using Cloud TPUs instead of clusters of other accelerators has allowed us to focus on building our models without being distracted by the need to manage the complexity of cluster communication patterns."
— Alfred Spector, Chief Technology Officer, Two Sigma
A scalable ML platform
Cloud TPUs also simplify planning and managing ML computing resources:
You can provide your teams with state-of-the-art ML acceleration and adjust your capacity dynamically as their needs change.
Instead of committing the capital, time and expertise required to design, install and maintain an on-site ML computing cluster with specialized power, cooling, networking and storage requirements, you can benefit from large-scale, tightly-integrated ML infrastructure that has been heavily optimized at Google over many years.
There’s no more struggling to keep drivers up-to-date across a large collection of workstations and servers. Cloud TPUs are preconfigured—no driver installation required!
You are protected by the same sophisticated security mechanisms and practices that safeguard all Google Cloud services.
“Since working with Google Cloud TPUs, we’ve been extremely impressed with their speed—what could normally take days can now take hours. Deep learning is fast becoming the backbone of the software running self-driving cars. The results get better with more data, and there are major breakthroughs coming in algorithms every week. In this world, Cloud TPUs help us move quickly by incorporating the latest navigation-related data from our fleet of vehicles and the latest algorithmic advances from the research community.
— Anantha Kancherla, Head of Software, Self-Driving Level 5, Lyft
Here at Google Cloud, we want to provide customers with the best cloud for every ML workload and will offer a variety of high-performance CPUs (including Intel Skylake) and GPUs (including NVIDIA’s Tesla V100) alongside Cloud TPUs.
Getting started with Cloud TPUs
Cloud TPUs are available in limited quantities today and usage is billed by the second at the rate of $6.50 USD / Cloud TPU / hour.
We’re thrilled to see the enthusiasm that customers have expressed for Cloud TPUs. To help us manage demand, please sign up here to request Cloud TPU quota and describe your ML needs. We’ll do our best to give you access to Cloud TPUs as soon as we can.
To learn more about Cloud TPUs, join us for a Cloud TPU webinar on February 27th, 2018.
[Editor’s note: Today we hear from Incentro, a digital service provider and Google partner, which recently built a digital asset management solution on top of GCP. It combines machine learning services like Cloud Vision and Speech APIs to easily find and tag digital assets, plus Cloud Pub/Sub and Cloud Functions for an automated, serverless solution. Read on to learn how they did it.]
Here at Incentro, we have a large customer base among media and publishing companies. Recently, we noticed that our customers struggle with storing and searching for digital media assets in their archives. It’s a cumbersome process that involves a lot of manual tagging. As a result, the videos are often stored without being properly tagged, making it nearly impossible to find and reuse these assets afterwards.
To eliminate this sort of manual labour and to generate more business value from these expensive video assets, we sought to create a solution that would take care of mundane tasks like tagging photos and videos. This solution is called Segona Media (https://segona.io/media), and lets our customers store assets and tag and index their digital assets automatically.
Segona Media management features
Segona Media currently supports images, video and audio assets. For each of these asset types, Google Cloud provides specific managed APIs to extract relevant content from the asset without customers having to tag them manually or transcribe them.
For images, Cloud Vision API extracts most of the content we need: labels, landmarks, text and image properties are all extracted and can be used to find an image.
For audio, Cloud Speech API showed us tremendous results in transcribing an audio track. After extracting the audio into speech, we also use Google Cloud Natural Language API to discover sentiment and categories in the transcription. This way, users can search for spoken text, but also search for categories of text and even sentiment.
For video, we typically use a combination of audio and image analysis. Cloud Video Intelligence API extracts labels and timeframes, and detects explicit content. On top of that, we process the audio track from a video the same way we process audio assets (see above). This way users can search content from the video as well as from spoken text in the video.
Segona Media architecture
The traditional way for developing a solution like this involves getting hardware running, determining and installing application servers, databases, storage nodes, etc. After developing and getting the solution into production you may then come across a variety of familiar challenges: the operating system needs to be updated or upgraded or databases don't scale to cope with unexpected production data. We didn't want any of this, so after careful consideration, decided on a completely managed solution and serverless architecture. That way we’d have no servers to maintain, we could leverage Google’s ongoing API improvements and our solution could scale to handle the largest archives we could find.
We wanted Segona Media to also be able to easily connect to common tools in the media and publishing industries. Adobe InDesign, Premiere, Photoshop and Digital Asset Management solutions must all be able to easily store and retrieve assets from Segona Media. We solved this by using GCP APIs that were already in place for storing assets in Google Cloud Storage and just take it from there. We retrieve assets using the managed Elasticsearch API that runs on GCP.
Each action that Segona Media performs is a separate Google Cloud Function, usually triggered mostly by a Cloud Pub/Sub queue. Using a Pub/Sub queue to trigger a Cloud Function is an easy and scalable way to publish new actions.
Here’s a high-level architecture view of Segona Media:
High Level Architecture
And here's how the assets flow through Segona Media:
An asset is uploaded/stored to a Cloud Storage bucket
This event triggers a Cloud Function, which generates a unique ID, extracts metadata from the file object, moves it to the appropriate bucket (with lifecycle management) and creates the asset in the Elasticsearch index (we run Elastic Cloud hosted on GCP).
This queues up multiple asset processors in Google Cloud Pub/Sub that are specific for an asset type and that extract relevant content from assets using Google APIs.
Media asset management
Now, let's see how Segona Media handles different types of media assets.
Images
Images have a lot of features on which you can search, which we do via a dedicated microservice processor.
We use ImageMagick to extract metadata from the image object itself. We extract all XMP and EXIF metadata that's embedded in the file itself. This information is then added to the Elastic index and makes the image searchable by, for example, copyright info or resolution.
Cloud Vision API extracts labels in the image, landmarks, text and image properties. This takes away manual tagging of objects in the image and makes a picture searchable for its contents.
Segona Media offers customers to create custom labels. For example, a television manufacturer might want to know the specific model of a television set in a picture. We’ve implemented custom predictions by building our own Tensorflow models trained on custom data, and we train and run predictions on Cloud ML Engine.
For easier serving of all assets, we also create a low resolution thumbnail of every image.
Audio
Processing audio is pretty straightforward. We want to be able to search for spoken text in audio files, and we use Cloud Speech API to extract text from the audio. We then feed the transcription into the Elasticsearch index, making the audio file searchable by every word.
Video
Video is basically the combination of everything we do with images and audio files. There are some minor differences though, so let's see what microservices we invoke for these assets:
First of all, we create a thumbnail so we can serve up a low-res image of the video. We take a thumbnail at 50% of the video. We do this by combining FFmpeg and FFprobe in Cloud Functions, and store this thumbnail alongside the video asset. Creating a thumbnail with Cloud Functions and FFmpeg is easy! Check out this code snippet: https://bitbucket.org/snippets/keesvanbemmel/keAkqe
Using the same FFmpeg architecture, we extract the audio stream from the video. This audio stream is then processed like any other audio file: We extract the text from spoken text in the audio stream and add it to the Elastic index so the video itself can also be found by searching for every word that's spoken. We extract the audio stream from the video in a single channel FLAC format as this gives us the best results.
We also extract relevant information from the video contents itself using Cloud Video Intelligence. We extract labels that are in the video as well as the timestamps for when the labels were created. This way, we know which objects are at what point in the video. Knowing the timestamps for a given label is a fantastic way to point a user to not only a video, but the exact moment in the video that contains the object they're looking for.
There you have it—a summary of how to do smart media tagging in a completely serverless fashion, without all the OS updates when scaling up or out, or of course, the infrastructure maintenance and support! This way we can focus on what we care about: bringing an innovative, scalable solution to our end customers. Any questions? Let us know! We love to talk about this stuff ;) Leave a comment below, email me at [email protected], or find us on Twitter at @incentro_.
By Chris Kleban and Michael Basilyan, GCE Product Managers
In May 2015, Google Cloud introduced Preemptible VM instances to dramatically change how you think about (and pay for) computational resources for high-throughput batch computing, machine learning, scientific and technical workloads. Then last year, we introduced lower pricing for Local SSDs attached to Preemptible VMs, expanding preemptible cloud resources to high performance storage. Now we're taking it even further by announcing the beta release of GPUs attached to Preemptible VMs.
You can now attach NVIDIA K80 and NVIDIA P100 GPUs to Preemptible VMs for $0.22 and $0.73 per GPU hour, respectively. This is 50% cheaper than GPUs attached to on-demand instances, which we also recently lowered. Preemptible GPUs will be a particularly good fit for large-scale machine learning and other computational batch workloads as customers can harness the power of GPUs to run distributed batch workloads at predictably affordable prices.
As a bonus, we're also glad to announce that our GPUs are now available in our us-central1 region. See our GPU documentation for a full list of available locations.
Resources attached to Preemptible VMs are the same as equivalent on-demand resources with two key differences: Compute Engine may shut them down after providing you a 30-second warning, and you can use them for a maximum of 24 hours. This makes them a great choice for distributed, fault-tolerant workloads that don’t continuously require any single instance, and allows us to offer them at a substantial discount. But just like its on-demand equivalents, preemptible pricing is fixed. You’ll always get low cost, financial predictability and we bill on a per-second basis.
Any GPUs attached to a Preemptible VM instance will be considered Preemptible and will be billed at the lower rate. To get started, simply append --preemptible to your instance create command in gcloud, specify scheduling.preemptible to true in the REST API or set Preemptibility to "On" in the Google Cloud Platform Console and then attach a GPU as usual. You can use your regular GPU quota to launch Preemptible GPUs or, alternatively, you can request a special Preemptible GPUs quota that only applies to GPUs attached to Preemptible VMs.
For users looking to create dynamic pools of affordable GPU power, Compute Engine’s managed instance groups can be used to automatically re-create your preemptible instances when they're preempted (if capacity is available). Preemptible VMs are also integrated into cloud products built on top of Compute Engine, such as Kubernetes Engine (GKE’s GPU support is currently in preview. The sign-up form can be found here).
"Preemptible GPU instances from GCP give us the best combination of affordable pricing, easy access and sufficient scalability. In our drug discovery programs, cheaper computing means we can look at more molecules, thereby increasing our chances of finding promising drug candidates. Preemptible GPU instances have advantages over the other discounted cloud offerings we have explored, such as consistent pricing and transparent terms. This greatly improves our ability to plan large simulations, control costs and ensure we get the throughput needed to make decisions that impact our projects in a timely fashion."
— Woody Sherman, CSO, Silicon Therapeutics
We’re excited to see what you build with GPUs attached to Preemptible VMs. If you want to share stories and demos of the cool things you've built with Preemptible VMs, reach out on Twitter, Facebook or G+.
By Alex Barrett and Barrett Williams, Google Cloud blog editors
The end of the year is a time for reflection . . . and making lists. As 2017 comes to a close, we thought we’d review some of the most memorable Google Cloud Platform (GCP) product announcements, white papers and how-tos, as judged by popularity with our readership.
As we pulled the data for this post, some definite themes emerged about your interests when it comes to GCP:
You love to hear about advanced infrastructure: CPUs, GPUs, TPUs, better network plumbing and more regions.
How we harden our infrastructure is endlessly interesting to you, as are tips about how to use our security services.
Open source is always a crowd-pleaser, particularly if it presents a cloud-native solution to an age-old problem.
You’re inspired by Google innovation — unique technologies that we developed to address internal, Google-scale problems.
So, without further ado, we present to you the most-read stories of 2017.
What’s the use of great infrastructure without somewhere to put it? 2017 was also a year of major geographic expansion. We started out the year with six regions, and ended it with 13, adding Northern Virginia, Singapore, Sydney, London, Germany, Sao Paolo and Mumbai. This was also the year that we shed our Earthly shackles, and expanded to Mars ;)
When you think about GCP and open source, Kubernetes springs to mind. We open-sourced the container management platform back in 2014, but this year we showed that GCP is an optimal place to run it. It’s consistently among the first cloud services to run the latest version (most recently, Kubernetes 1.8) and comes with advanced management features out of the box. And as of this fall, it’s certified as a conformant Kubernetes distribution, complete with a new name: Google Kubernetes Engine.
Part of Kubernetes’ draw is as a platform-agnostic stepping stone to the cloud. Accordingly, many of you flocked to stories about Kubernetes and containers in hybrid scenarios. Think Pivotal Container Service and Kubernetes’ role in our new partnership with Cisco. The developers among you were smitten with Cloud Container Builder, a stand-alone tool for building container images, regardless of where you deploy them.
But our open source efforts aren’t limited to Kubernetes — we also made significant contributions to Spinnaker 1.0, and helped launch the Istio and Grafeas projects. You ate up our "Partnering on open source" series, featuring the likes of HashiCorp, Chef, Ansible and Puppet. Availability-minded developers loved our Customer Reliability Engineering (CRE) team’s missive on release canaries, and with API design: Choosing between names and identifiers in URLs, our Apigee team showed them a nifty way to have their proverbial cake and eat it too.
Google innovation
In distributed database circles, Google’s Spanner is legendary, so many of you were delighted when we announced Cloud Spanner and a discussion of how it defies the CAP Theorem. Having a scalable database that offers strong consistency and great performance seemed to really change your conception of what’s possible — as did Cloud IoT Core, our platform for connecting and managing “things” at scale. CREs, meanwhile, showed you the Google way to handle an incident.
Lastly, we want to thank all our customers, partners and readers for your continued loyalty and support this year, and wish you a peaceful, joyful, holiday season. And be sure to rest up and visit us again Next year. Because if you thought we had a lot to say in 2017, well, hold onto your hats.
Hi there! I’m Merry, Santa’s CIE (Chief Information Elf), responsible for making sure computers help us deliver joy to the world each Christmas. My elf colleagues are really busy getting ready for the big day (or should I say night?), but this year, my team has things under control, thanks to our fully cloud-native architecture running on Google Cloud Platform (GCP)! What’s that? You didn’t know that the North Pole was running in the cloud? How else did you think that we could scale to meet the demands of bringing all those gifts to all those children around the world?
You see, North Pole Operations have evolved quite a lot since my parents were young elves. The world population increased from around 1.6 billion in the early 20th century to 7.5 billion today. The elf population couldn’t keep up with that growth and the increased production of all these new toys using our old methods, so we needed to improve efficiency.
Of course, our toy list has changed a lot too. It used to be relatively simple — rocking horses, stuffed animals, dolls and toy trucks, mostly. The most complicated things we made when I was a young elf were Teddy Ruxpins (remember those?). Now toy cars and even trading card games come with their own apps and use machine learning.
This is where I come in. We build lots of computer programs to help us. My team is responsible for running hundreds of microservices. I explain microservices to Santa as a computer program that performs a single service. We have a microservice for processing incoming letters from kids, another microservice for calculating kids’ niceness scores, even a microservice for tracking reindeer games rankings.
Here's an example of the Letter Processing Microservice, which takes handwritten letter in all languages (often including spelling and grammatical errors) and turns each one into text.
Each microservice runs on one or more computers (also called virtual machines or VMs). We tried to run it all from some computers we built here at the North Pole but we had trouble getting enough electricity for all these VMs (solar isn’t really an option here in December). So we decided to go with GCP. Santa had some reservations about “the Cloud” since he thought it meant our data would be damaged every time it rained (Santa really hates rain). But we managed to get him a tour of a data center (not even Santa can get in a Google data center without proper clearances), and he realized that cloud computing is really just a bunch of computers that Google manages for us.
Google lets us use projects, folders and orgs to group different VMs together. Multiple microservices can make up an application and everything together makes up our system. Our most important and most complicated application is our Christmas Planner application. Let’s talk about a few services in this application and how we make sure we have a successful Christmas Eve.
Our Christmas Planner application includes microservices for a variety of tasks: microservices generate lists of kids that are naughty or nice, as well as a final list of which child receives which gift based on preferences and inventory. Microservices plan the route, taking into consideration inclement weather and finally, generate a plan for how to pack the sleigh.
Small elves, big data
Our work starts months in advance, tracking naughty and nice kids by relying on parent reports, teacher reports, police reports and our mobile elves. Keeping track of almost 2 billion kids each year is no easy feat. Things really heat up around the beginning of December, when our army of Elves-on-the-Shelves are mobilized, reporting in nightly.
We send all this data to a system called BigQuery where we can easily analyze the billions of reports to determine who's naughty and who's nice in just seconds.
Deck the halls with SLO dashboards
Our most important service level indicator or SLI is “child delight”. We target “5 nines” or 99.999% delightment level meaning 99,999/100,000 nice children are delighted. This limit is our service level objective or SLO and one of the few things everyone here in the North Pole takes very seriously. Each individual service has SLOs we track as well.
We use Stackdriver for dashboards, which we show in our control center. We set up alerting policies to easily track when a service level indicator is below expected and notify us. Santa was a little grumpy since he wanted red and green to be represented equally and we explained that the red warning meant that there were alerts and incidents on a service, but we put candy canes on all our monitors and he was much happier.
Merry monitoring for all
We have a team of elite SREs (Site Reliability Elves, though they might be called Site Reliability Engineers by all you folks south of the North Pole) to make sure each and every microservice is working correctly, particularly around this most wonderful time of the year. One of the most important things to get right is the monitoring.
For example, we built our own “internet of things” or IoT where each toy production station has sensors and computers so we know the number of toys made, what their quota was and how many of them passed inspection. Last Tuesday, there was an alert that the number of failed toys had shot up. Our SREs sprang into action. They quickly pulled up the dashboards for the inspection stations and saw that the spike in failures was caused almost entirely by our baby doll line. They checked the logs and found that on Monday, a creative elf had come up with the idea of taping on arms and legs rather than sewing them to save time. They rolled back this change immediately. Crisis averted. Without the proper monitoring and logging, it would be very difficult to find and fix the issue, which is why our SREs consider it the base of their gift reliability pyramid.
All I want for Christmas is machine learning
Running things in Google Cloud has another benefit: we can use technology they’ve developed at Google. One of our most important services is our gift matching service, which takes 50 factors as input including the child’s wish list, niceness score, local regulations, existing toys, etc., and comes up with the final list of which gifts should be delivered to this child. Last year, we added machine learning or ML, where we gave the Cloud ML engine the last 10 years of inputs, gifts and child and parent delight levels. It automatically learned a new model to use in gift matching based on this data.
Using this new ML model, we reduced live animal gifts by 90%, ball pits by 50% and saw a 5% increase in child delight and a 250% increase in parent delight.
Tis the season for sharing
Know someone who loves technology that might enjoy this article or someone who reminds you of Santa — someone with many amazing skills but whose eyes get that “reindeer-in-the-headlights look” when you talk about cloud computing? Share this article with him or her and hopefully you’ll soon be chatting about all the cool things you can do with cloud computing over Christmas cookies and eggnog... And be sure to tell them to sign up for a free trial — Google Cloud’s gift to them!
Whether you're looking to build your next big application, learn some really cool technology concepts or gain some hands-on development experience, Google Cloud Platform (GCP) is a great development platform. But where do you start?
Lots of customers talk to us about their varying application development needs — for example, what are the best tools to use for web and mobile app development, how do I scale my application back-end and how do I add data processing and intelligence to my application? In this blog, we’ll share some resources to help you identify which products are best suited to your development goals.
To help you get started, here are a few resources such as quick start guides, videos and codelabs for services across web and mobile app development, developer tools, data processing and analytics and monitoring:
Web and mobile app development:
Google App Engine offers a fully managed serverless platform that allows you to build highly scalable web and mobile applications. If you're looking for a zero-config application hosting service that will let you auto-scale from zero to infinite-size without having to manage any infrastructure, look no further than App Engine
Cloud Functions is another great event-driven serverless compute platform you can use to build microservices at the functions level, scale to infinite size and pay only for what you use. If you're looking for a lightweight compute platform to run your code in response to user actions, analytics, authentication events or for telemetry data collection, real-time processing and analysis, Cloud Functions has everything you need to be agile and productive.
Developer tools provide plugins to build, deploy and debug code using your favorite IDEs, such as IntelliJ, Eclipse, Gradle and Maven. You can use either cloud SDK or a browser-based command line to build your apps. Cloud Source Repositories that come as a part of developer tools let you host private Git repos and organize the associated code. Below are a sampling of resources, check out the developer tools section for more.
BigQuery offers a fast, highly scalable, low cost and fully managed data warehouse on which you can perform analytics. Cloud Pub/Sub allows you to ingest event streams from anywhere, at any scale, for simple, reliable, real-time stream analytics. BigQuery and Pub/Sub work seamlessly with services like Cloud Machine Learning Engine to help you add an intelligence layer to your application.
Google Stackdriver provides powerful monitoring, logging and diagnostics. It equips you with insight into the health, performance and availability of cloud-powered applications, enabling you to find and fix issues faster. It's natively integrated with GCP, other cloud providers and popular open source packages.
I hope this gives you enough content to keep you engaged and provide great learning experiences of the different application development services on GCP. Looking for tips and tricks as you're building your applications? Check out this link for details. Sign up for your free trial today and get a $300 GCP credit!
By Alex Barrett and Barrett Williams, Google Cloud blog editors
The end of the year is a time for reflection . . . and making lists. As 2017 comes to a close, we thought we’d review some of the most memorable Google Cloud Platform (GCP) product announcements, white papers and how-tos, as judged by popularity with our readership.
As we pulled the data for this post, some definite themes emerged about your interests when it comes to GCP:
You love to hear about advanced infrastructure: CPUs, GPUs, TPUs, better network plumbing and more regions.
How we harden our infrastructure is endlessly interesting to you, as are tips about how to use our security services.
Open source is always a crowd-pleaser, particularly if it presents a cloud-native solution to an age-old problem.
You’re inspired by Google innovation — unique technologies that we developed to address internal, Google-scale problems.
So, without further ado, we present to you the most-read stories of 2017.
What’s the use of great infrastructure without somewhere to put it? 2017 was also a year of major geographic expansion. We started out the year with six regions, and ended it with 13, adding Northern Virginia, Singapore, Sydney, London, Germany, Sao Paolo and Mumbai. This was also the year that we shed our Earthly shackles, and expanded to Mars ;)
When you think about GCP and open source, Kubernetes springs to mind. We open-sourced the container management platform back in 2014, but this year we showed that GCP is an optimal place to run it. It’s consistently among the first cloud services to run the latest version (most recently, Kubernetes 1.8) and comes with advanced management features out of the box. And as of this fall, it’s certified as a conformant Kubernetes distribution, complete with a new name: Google Kubernetes Engine.
Part of Kubernetes’ draw is as a platform-agnostic stepping stone to the cloud. Accordingly, many of you flocked to stories about Kubernetes and containers in hybrid scenarios. Think Pivotal Container Service and Kubernetes’ role in our new partnership with Cisco. The developers among you were smitten with Cloud Container Builder, a stand-alone tool for building container images, regardless of where you deploy them.
But our open source efforts aren’t limited to Kubernetes — we also made significant contributions to Spinnaker 1.0, and helped launch the Istio and Grafeas projects. You ate up our "Partnering on open source" series, featuring the likes of HashiCorp, Chef, Ansible and Puppet. Availability-minded developers loved our Customer Reliability Engineering (CRE) team’s missive on release canaries, and with API design: Choosing between names and identifiers in URLs, our Apigee team showed them a nifty way to have their proverbial cake and eat it too.
Google innovation
In distributed database circles, Google’s Spanner is legendary, so many of you were delighted when we announced Cloud Spanner and a discussion of how it defies the CAP Theorem. Having a scalable database that offers strong consistency and great performance seemed to really change your conception of what’s possible — as did Cloud IoT Core, our platform for connecting and managing “things” at scale. CREs, meanwhile, showed you the Google way to handle an incident.
Lastly, we want to thank all our customers, partners and readers for your continued loyalty and support this year, and wish you a peaceful, joyful, holiday season. And be sure to rest up and visit us again Next year. Because if you thought we had a lot to say in 2017, well, hold onto your hats.
From chatbots to IoT devices, conversational apps provide a richer and more natural experience for users. Dialogflow (formerly API.AI) was created for exactly that purpose — to help developers build interfaces that offer engaging, personal interactions.
We’ve seen hundreds of thousands of developers use Dialogflow to create conversational apps for customer service, commerce, productivity, IoT devices and more. Developers have consistently asked us to add enterprise capabilities, which is why today we’re announcing the beta release of Dialogflow Enterprise Edition. The enterprise edition expands on all the benefits of Dialogflow, offering greater flexibility and support to meet the needs of large-scale businesses. In addition, we're also announcing speech integration within Dialogflow, enabling developers to build rich voice-based applications.
Here’s a little more on what Dialogflow offers:
Conversational interaction powered by machine learning: Dialogflow uses natural language processing to build conversational experiences faster and iterate more quickly. Provide a few examples of what a user might say and Dialogflow will build a unique model that can learn what actions to trigger and what data to extract so it provides the most relevant and precise responses to your users.
Build once and deploy everywhere: Use Dialogflow to build a conversational app and deploy it on your website, your app or 32 different platforms, including the Google Assistant and other popular messaging services. Dialogflow also supports multiple languages and multilingual experiences so you can reach users around the world.
Advanced fulfillment options: Fulfillment defines the corresponding action in response to whatever a user says, such as processing an order for a pizza or triggering the right answer to your user's question. Dialogflow allows you to connect to any webhook for fulfillment whether it's hosted in the public cloud or on-premises. Dialogflow’s integrated code editor allows you to code, test and implement these actions directly within Dialogflow's console.
Voice control with speech recognition: Starting today, Dialogflow enables your conversational app to respond to voice commands or voice conversations. It's available within a single API call, combining speech recognition with natural language understanding.
Flexibility and scale: Dialogflow Enterprise Edition offers higher default quotas so it’s easier to scale your app up or down based on user demand.
Unlimited pay-as-you-go voice support: While both the standard and enterprise editions now allow your conversational app to detect voice commands or respond to voice conversations, Dialogflow Enterprise Edition offers unlimited pay-as-you-go voice support.
Companies such as Uniqlo, PolicyBazaar and Strayer University have already used Dialogflow to design and deploy conversational experiences.
Creating new online shopping experiences for Uniqlo
UNIQLO is a modern Japanese retailer that operates nearly 1,900 stores worldwide. The company integrated a chatbot into its mobile app to provide quick, relevant answers to a range of customer questions, regardless of whether customers are shopping online or in-store. This makes the shopping experience easier and more enjoyable. Since deploying the chatbot, 40% of users have interacted with it on a weekly basis.
“Our shopping chatbot was developed using Dialogflow to offer a new type of shopping experience through a messaging interface, with responses continually being improved through machine learning. Going forward, we’re also looking to expand the functionality to include voice recognition and multiple languages.”
— Shinya Matsuyama, Director of Global Digital Commerce, Uniqlo
Changing the way we buy insurance with PolicyBazaar
PolicyBazaar is the leading insurance marketplace in India, founded in the year 2008, with the purpose of educating consumers, enabling easy comparisons and purchasing insurance products. The company today hosts over 80 million visitors yearly, and records nearly 150,000 transactions a month.
Using Dialogflow Enterprise Edition, PolicyBazaar created and deployed a conversational assisted chatbot, PBee, to better serve its visitors and transform the way customers purchase insurance online. The company has been using the logging and training module to track top customer requests and improve fulfillment capabilities. In just a few months, PBee now handles over 60% of customer queries over chat, resulting in faster fulfillment of requests from its users.
Since deploying the chatbot, the company has seen a five-fold increase in customers using their chat interface for auto insurance, and chat now contributes to 40% of the company's auto insurance sales.
“Dialogflow is by far the best platform for text-based conversational chatbots. With it, we derive all the benefits of machine learning without restrictions on the frontend. Through our chatbot, we are now closing over 13,000 sales totaling a premium of nearly $2 million (USD) every month and growing at a 30% month-over-month rate.”
— Ashish Gupta, CTO & CPO, Policybazaar.com
For more on the differences between the standard and the enterprise editions of Dialogflow, we recommend reading our documentation.
We look forward to seeing what you'll build during our public beta. To learn more about Dialogflow Enterprise Edition, visit our product page.
Editor’s note: Today’s blog post comes from Alex Olivier, product manager at Qubit. He’ll be taking us through the solution Qubit provided for Ubisoft, one of the world’s largest gaming companies, to help them personalize customer experiences through data analysis.
Our platform helps brands across a range of sectors — from retail and gaming to travel and hospitality — deliver a personalized digital experience for users. To do so, we analyze thousands of data points throughout a customer’s journey, taking the processing burden away from our clients. This insight prompts our platform to make a decision — for example, including a customer in a VIP segment, or identifying a customer’s interest in a certain product — and adapts the visitor’s experience accordingly.
As one of the world's largest gaming companies, Ubisoft faced a problem that challenges many enterprises: a data store so big it was difficult and time-consuming to analyze. “Data took between fifteen and thirty minutes to process,” explained Maxime Bosvieux, EMEA Ecommerce Director at Ubisoft. “This doesn’t sound like much, but the modern customer darts from website to website, and if you’re unable to provide them with the experience they’re looking for, when they’re looking for it, they’ll choose the competitor who can.” That’s when they turned to Qubit and Google Cloud Platform.
A cloud native approach.
From early on, we made the decision to be an open ecosystem so as to provide our clients and partners with flexibility across technologies. When designing our system, we saw that the rise of cloud computing could transform not only how platform companies like ours process data, but also how they interface with customers. By providing Cloud-native APIs across the stack, our clients could seamlessly use open source tools and utilities with Qubit’s systems that run on GCP. Many of these tools interface with gsutil via the command-line, call BigQuery, or even upload to Cloud Storage buckets via CyberDuck.
We provision and provide our clients access to their own GCP project. The project contains all data processed and stored from their websites, apps and back-end data sources. Clients can then access both batch and streaming data, be it a user's predicted preferred category, a real-time calculation of lifetime value, or which customer segment the user belongs to. A client can access this data within seconds, regardless of their site’s traffic volume at that moment.
Bringing it all together for Ubisoft.
One of the first things Ubisoft realized is that they needed access to all of their data, regardless of the source. Qubit Live Tap gave Ubisoft access to the full take of their data via BigQuery (and through BI tools like Google Analytics and Looker). Our system manages all data processing and schema management, and reports out actionable next steps. This helps speed up the process of understanding the customer in order to provide better personalization. Using BigQuery’s scaling abilities, Live Tap generates machine learning and AI driven insights for clients like Ubisoft. This same system also lets them access their data in other BI and analytics tools such as Google Data Studio.
We grant access to clients like Ubisoft through a series of views in their project that point back to their master data store. The BigQuery IAM model (permissions provisioning for shared datasets) allows views to be authorized across multiple projects, removing the need to do batch copies between instances, which might cause some data to become stale. As Qubit streams data into the master tables, the views have direct access to it: analysts who perform queries in their own BigQuery project get access to the latest, real-time data.
Additionally, because the project provided is a complete GCP environment, clients like Ubisoft can also provision additional resources. We have clients who create their own Dataproc clusters, or import data provided by Qubit in BigQuery or via a PubSub topic to perform additional analysis and machine learning in a single environment. This process avoids the data wrangling problems commonly encountered in closed systems.
By combining Google Cloud Dataflow, Bigtable and BigQuery, we’re able to process vast amounts of data quickly and at petabyte-scale. During a typical month, Qubit’s platform will provide personalized experiences for more than 100 million users, surface 28 billion individual visitor experiences from ML-derived conclusions on customer data and use AI to simulate more than 2.3 billion customers journeys.
All of this made a lot of sense to Ubisoft. “We’re a company famous for innovating quickly and pushing the limits of what can be done,” Maxime Bosvieux told us. “That requires stable and robust technology that leverages the latest in artificial intelligence to build our segmentation and personalization strategies.”
Helping more companies move to the cloud with effective and efficient migrations.
We’re thrilled that the infrastructure we built with GCP has helped clients like Ubisoft scale data processing far beyond previous capabilities. Our integration into the GCP ecosystem is making this scalability even more attractive to organizations switching to the cloud. While porting data to a new provider can be daunting, we’re helping our clients make a more manageable leap to GCP.