Many Google products (e.g., the Google Assistant, Search, Maps) come with built-in high-quality text-to-speech synthesis that produces natural sounding speech. Developers have been telling us they’d like to add text-to-speech to their own applications, so today we’re bringing this technology to Google Cloud Platform with Cloud Text-to-Speech.
You can use Cloud Text-to-Speech in a variety of ways, for example:
- To power voice response systems for call centers (IVRs) and enabling real-time natural language conversations
- To enable IoT devices (e.g., TVs, cars, robots) to talk back to you
- To convert text-based media (e.g., news articles, books) into spoken format (e.g., podcast or audiobook)
Rolling in the DeepMind
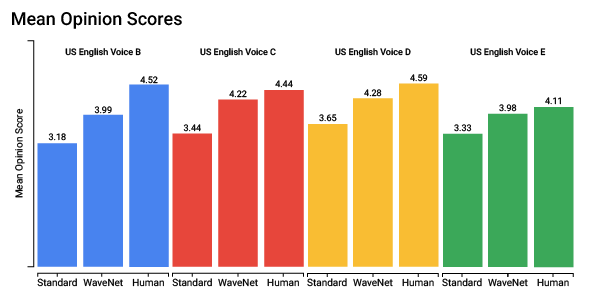
In addition, we're excited to announce that Cloud Text-to-Speech also includes a selection of high-fidelity voices built using WaveNet, a generative model for raw audio created by DeepMind. WaveNet synthesizes more natural-sounding speech and, on average, produces speech audio that people prefer over other text-to-speech technologies.
In late 2016, DeepMind introduced the first version of WaveNet — a neural network trained with a large volume of speech samples that's able to create raw audio waveforms from scratch. During training, the network extracts the underlying structure of the speech, for example which tones follow one another and what shape a realistic speech waveform should have. When given text input, the trained WaveNet model generates the corresponding speech waveforms, one sample at a time, achieving higher accuracy than alternative approaches.
Fast forward to today, and we're now using an updated version of WaveNet that runs on Google’s Cloud TPU infrastructure.The new, improved WaveNet model generates raw waveforms 1,000 times faster than the original model, and can generate one second of speech in just 50 milliseconds. In fact, the model is not just quicker, but also higher-fidelity, capable of creating waveforms with 24,000 samples a second. We’ve also increased the resolution of each sample from 8 bits to 16 bits, producing higher quality audio for a more human sound.

“As the leading provider of collaboration solutions, Cisco has a long history of bringing the latest technology advances into the enterprise. Google’s Cloud Text-to-Speech has enabled us to achieve the natural sound quality that our customers desire."
— Tim Tuttle, CTO of Cognitive Collaboration, Cisco
“Dolphin ONE’s Calll.io telephony platform offers connectivity from a multitude of devices, at practically any location. We’ve integrated Cloud Text-to-Speech into our products and allow our users to create natural call center experiences. By using Google Cloud’s machine learning tools, we’re instantly delivering cutting-edge technology to our users.”
—Jason Berryman, Dolphin ONE
Get started today
With Cloud Text-to-Speech, you’re now a few clicks away from one of the most advanced speech technologies in the world. To learn more, please visit the documentation or our pricing page. To get started with our public beta or try out the new voices, visit the Cloud Text-to-Speech website.
