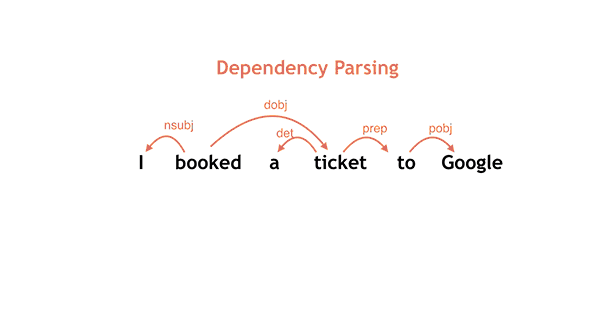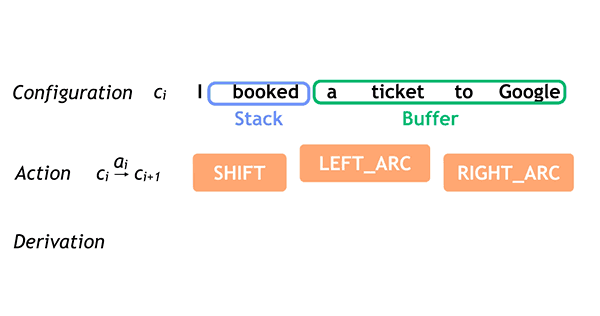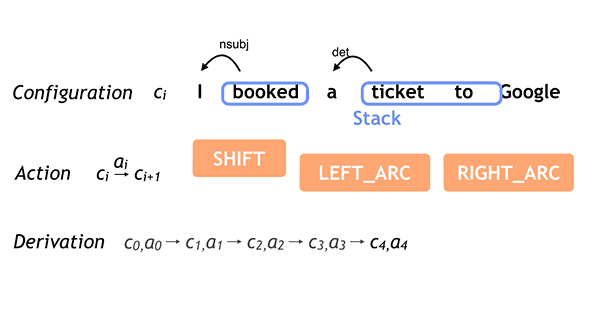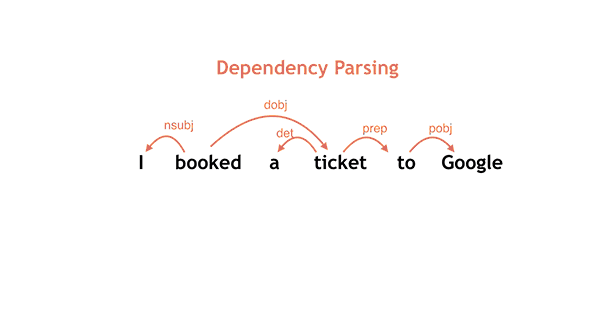
This is the fourth episode in the series of posts reporting on the work we are doing to build text-to-speech (TTS) systems for low resource languages. In the first episode, we described the crowdsourced acoustic data collection effort for Project Unison. In the second episode, we described how we built parametric voices based on that data. In the third episode, we described the compilation of a pronunciation lexicon for a TTS system. In this episode, we describe how to make a single TTS system speak many languages.
Developing TTS systems for any given language is a significant challenge, and requires large amounts of high quality acoustic recordings and linguistic annotations. Because of this, these systems are only available for a tiny fraction of the world's languages. A natural question that arises in this situation is, instead of attempting to build a high quality voice for a single language using monolingual data from multiple speakers, as we described in the previous three episodes, can we somehow combine the limited monolingual data from multiple speakers of multiple languages to build a single multilingual voice that can speak any language?
Building upon an initial investigation into creating a multilingual TTS system that can synthesize speech in multiple languages from a single model, we developed a new model that uses uniform phonological representation for all languages — the International Phonetic Alphabet (IPA). The model trained using this representation can synthesize both the languages seen in the training data as well as languages not observed in training. This has two main benefits: First, pooling training data from related languages increases phonemic coverage which results in improved synthesis quality of the languages observed in training. Finally, because the model contains many languages pooled together, there is a better chance that an “unseen” language will have a “related” language present in the model that will guide and aid the synthesis.
Exploring the Closely Related Languages of Indonesia
We applied this multilingual approach first to languages of Indonesia, where Standard Indonesian is the official national language, and is spoken natively or as a second language by more than 200 million people. Javanese, with roughly 90 million native speakers, and Sundanese, with approximately 40 million native speakers, constitute the two largest regional languages of Indonesia. Unlike Indonesian, which received a lot of attention by the computational linguists and speech scientists over the years, both Javanese and Sundanese are currently low-resourced due to the lack of openly available high-quality corpora. We collaborated with universities in Indonesia to collect crowd-sourced Javanese and Sundanese recordings.
Since our corpus of Standard Indonesian was much larger and recorded in a professional studio, our hypothesis was that combining three languages may result in significant improvements over the systems constructed using a “classical” monolingual approach. To test this, we first proceeded to analyze the similarities and crucial differences between the phonologies of these three languages (shown below) and used this information to design the phonological representation that allows maximum degree of sharing between the languages while preserving their crucial differences.
 |
| Joint phoneme inventory of Indonesian, Javanese, and Sundanese in International Phonetic Alphabet notation. |
Expanding to the More Diverse Language Families of South Asia
Next, we focused on the languages of South Asia spanning two very different language families: Indo-Aryan and Dravidian. Unlike the languages of Indonesia described above, these languages are much more diverse. In particular, they have significantly smaller overlap in their phonologies. The table below shows a superset of the languages in our experiment, including the variety of orthographies used, as well as modern words related to the Sanskrit word for “culture”. These languages show considerable variation within each group, but also such similarities across groups.
 |
| Descendants of Sanskrit word for “culture” across languages. |
In addition, we made sure our representation is driven by the phonology in use, rather than the orthography. For example, although there are distinct letters for long and short vowels in Marathi, they are not contrastive in a linguistic sense, so we used a single representation for them, increasing the robustness of our training data. Similarly, if two languages use one character that was historically related to the same Sanskrit letter to represent different sounds or different letters for a similar sound, our mapping reflected the phonological closeness rather than the historical or orthographic representation. Describing all the features of the unified phoneme inventory is outside the scope of this post, the details can be found in our recent paper.
 |
| Diagram illustrating our multilingual text-to-speech approach. The input text queries are processed by language-specific linguistic front-ends to generate pronunciations in a shared phonemic representation serving as input to the language-agnostic acoustic model. The model then generates audio for the respective queries. |
The results were encouraging: for most of the languages, the multilingual voices outperformed the voices that were constructed using traditional monolingual approach. We performed a further experiment with the Odia language, for which we had no training data, by attempting to synthesize it using the South Asian multilingual model. Subjective listening tests revealed that the native speakers of Odia judged the resulting audio to be acceptable and intelligible. The resulting voices for Marathi, Tamil, Telugu and Malayalam built using our multilingual approach in collaboration with the Speech team were announced at the recent “Google for India” event and are now powering Google Translate as well as other Google products.
Using crowd-sourcing in data collections was interesting from a research point of view and rewarding in terms of establishing fruitful collaborations with the native speaker communities. Our experiments with the Malayo-Polynesian, Indo-Aryan and Dravidian language families have shown that in most instances carefully sharing the data across multiple languages in a single multilingual acoustic model using deep learning techniques alleviates some of the severe data scarcity issues plaguing the low-resource languages and results in good quality voices used in Google products.
This TTS research is a first step towards applying speech and language technology to more of the world’s many languages, and it is our hope is that others will join us in this effort. To contribute to the research community we have open sourced corpora for Nepali, Sinhala, Bengali, Khmer, Javanese and Sundanese as we return from SLTU and Interspeech conferences, where we have been discussing this work with other researchers. We are planning on continuing to release additional datasets for other languages in our projects in the future.