By Ivan Naranjo, C# Team Lead
For the past several months, all you .NET developers out there have been kicking the tires on
running .NET Core apps on App Engine flexible environment. Now, thanks to all your great feedback, we’re really happy to announce that .NET Core support is generally available on
App Engine flexible environment as well as
Container Engine. We support .NET Core 1.0, 1.1 and 2.0 with Google-supported Docker images that are optimized for running on
Google Cloud Platform (GCP).
Now that you can run your .NET Core apps on GCP in a supported fashion, the question becomes what’s the best way to get your apps there? In a nutshell, there are four basic methods for deploying an ASP.NET Core app to GCP, depending on your target environment:
- Deploy from Visual Studio directly using the Cloud Tools for Visual Studio extension
- Deploy a Framework Dependent Deployment bundle with "dotnet publish"
- Deploy to App Engine flexible environment with a custom Dockerfile
- Deploy to Container Engine with a custom Dockerfile
Method 1 is arguably the simplest, most direct way to get your app up and running on GCP, and takes care of creating all necessary components, including the Dockerfile, behind the scenes. Methods 2, 3 and 4 are appropriate when you cannot use Visual Studio, and can be performed directly from the command line. These methods require you to gather and create the several components necessary to deploy your app, including:
- Build artifacts, such as .dlls, that are the result of publishing your app and which include all the necessary dependencies to be able to run
- In the case of App Engine, an app.yaml file that defines the deployment, and that sits at the root of the app’s deployment files
Deploying your app will also require you to build a Docker image, for which you’ll need to create a Dockerfile that describes to the Docker service how to build the image. App Engine creates the Dockerfile for you while it deploys your app (see “Method 3: Deploy to App Engine with a custom Dockerfile” below). If you’re deploying to Container Engine, however, you’ll need to create the Dockerfile yourself.
Let’s take a deeper look at these four methods.
Method 1: Deploy from Visual Studio
To deploy your ASP.NET Core apps to GCP, you can use our
Cloud Tools for Visual Studio extension, which takes care of all the necessary details to deploy your app from right inside the Visual Studio IDE.
Method 2: Deploy a Framework Dependent Deployment bundle
The simplest way to deploy an app from the command line, meanwhile, is to deploy the result of running "dotnet publish" to create a
Framework Dependent Deployment bundle. This directory contains your app’s dlls and all of the dependencies referenced in your project files.
To deploy this directory to App Engine flexible environment, you also need to place your app.yaml in the build artifacts directory. To make this placement automatic, place the app.yaml file in the root of the startup project of the solution, next to the the .csproj file, and add app.yaml to .csproj as a file to be copied to the output. You can do this by adding the following snippet to .csproj:
<ItemGroup>
<None Include="app.yaml" CopyToOutputDirectory="PreserveNewest" />
</ItemGroup>
And here’s the minimum app.yaml file necessary to deploy to App Engine flexible:
runtime: aspnetcore
env: flex
This app.yaml indicates that you're using the “aspnetcore” runtime to run ASP.NET Core apps, and that you're running in App Engine flexible environment. You can further customize your app with these
additional app.yaml settings.
Once you’ve made the above change to your .csproj, publishing the app with the "dotnet publish" command copies app.yaml to the output directory. This creates a directory that's ready to be deployed.
To deploy this directory to App Engine flexible environment, follow these steps:
- From the startup project’s directory, run “dotnet publish” with the configuration of your choice, for example:
dotnet publish -c Release
This publishes the release build to the directory “bin\<configuration>\netcore<version>\publish” with the app’s deployment files, including app.yaml if you included it in .csproj.
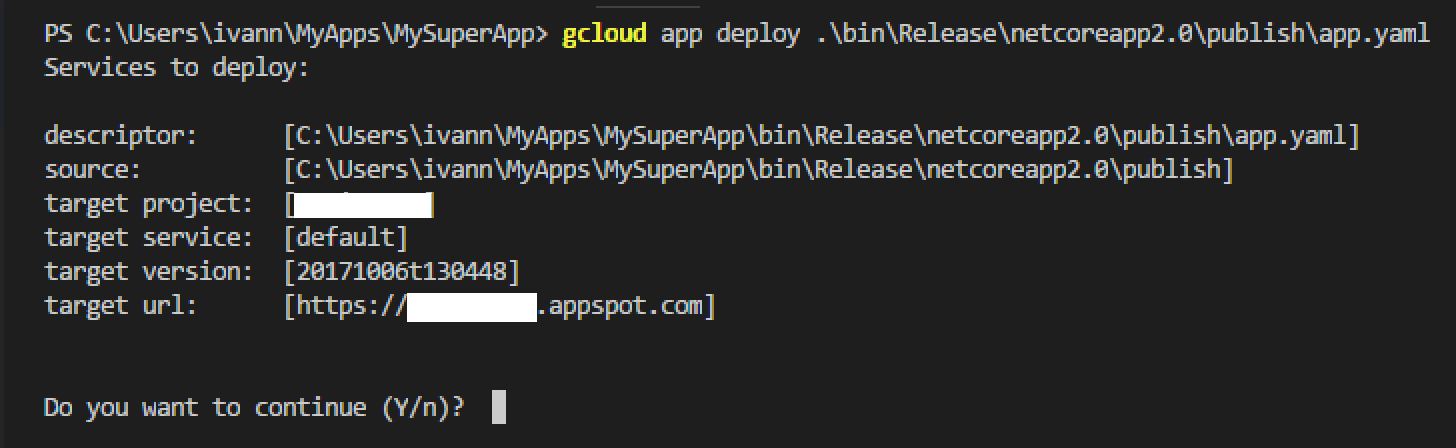
- Deploy the app to App Engine flexible by running:
gcloud app deploy
bin\<configuration>\netcore<version>\publish\app.yaml
This deploys the app to App Engine for you, and gcloud takes care of all of the complexities of wrapping your app into a Docker image.
Method 3: Deploy to App Engine with a custom Dockerfile
If you need more control over how your app’s container is built, you can specify your own Dockerfile. This happens when you need to install custom packages in the container, extra tools or need more control over the contents of the container.
In this case, you’ll need the following app.yaml:
runtime: custom
env: flex
The “runtime: custom” setting tells App Engine that you'll supply the Dockerfile to build your app’s image.
Next, you need to create a Dockerfile for your app. Here are two possible ways to write the Dockerfile, depending on your needs.
- Creating a Dockerfile for a published app
If you want to keep going down the published app route, you can specify a Dockerfile to build the app’s image based on a published directory. The Dockerfile looks like this:
FROM gcr.io/google-appengine/aspnetcore:2.0
ADD ./ /app
ENV ASPNETCORE_URLS=http://*:${PORT}
WORKDIR /app
ENTRYPOINT [ "dotnet", "MainProject.dll" ]
Notice how this Dockerfile example uses the “gcr.io/google-appengine/aspnetcore:2.0” as its base image. We've created a set of Docker images that are optimized for running ASP.NET Core apps in App Engine and Container Engine, and we highly recommend that you use them for your custom Dockerfiles. These are the same images we use when we generate Dockerfiles for you during deployment. Be sure to change it to refer to the correct .NET Core runtime version for your app.
To ensure that the Dockerfile is in the published directory, add it to your .csproj so it's published when the app is published. Assuming that the Dockerfile is in the root of the startup project, on the same level as .csproj and app.yaml, add the following snippet to .csproj:
<ItemGroup>
<None Include="app.yaml" CopyToOutputDirectory="PreserveNewest" />
<None Include="Dockerfile" CopyToOutputDirectory="PreserveNewest" />
</ItemGroup>
With this change, whenever you run “dotnet publish” both files are copied to the published directory. To deploy, just follow the same steps as before:
dotnet publish -c Release
gcloud app deploy
bin\<configuration>\netcore<version>\publish\app.yaml
- Creating a Dockerfile that compiles and publishes the app
If you can easily build your ASP.NET Core app on Linux, you should consider using a multi-stage Dockerfile that performs the restore and publish steps during the build process, before building the final app’s image. This makes it a bit more convenient to deploy the app, as the build is done during deployment.
Here’s what that Dockerfile looks like:
# First let’s build the app and publish it.
FROM gcr.io/cloud-builders/csharp/dotnet AS builder
COPY . /src
WORKDIR /src
RUN dotnet restore --packages /packages
RUN dotnet publish -c Release -o /published
# Now let's build the app's image.
FROM gcr.io/google-appengine/aspnetcore:2.0
COPY --from=builder /published /app
ENV ASPNETCORE_URLS=http://*:${PORT}
WORKDIR /app
ENTRYPOINT [ "dotnet", "multistage-2.0.dll" ]
This Dockerfile uses the “gcr.io/cloud-builders/csharp/dotnet” builder image that wraps the .NET SDKs for all supported versions of .NET Core.
The main advantage of this method is that you can put app.yaml and the Dockerfile in the root of your project, next to .csproj. Then, to deploy the app, simply run the following command:
gcloud app deploy app.yaml
This uploads your app sources to Cloud Builder where the build will take place. The resulting build artifacts will then be used to produce the final app image, which will be deployed to App Engine. You can also run tests during the build process, making this a complete CI/CD solution.
Method 4: Deploy to Container Engine
When you need more control over your workloads, or need to use protocols not supported by App Engine, you can use
Container Engine. Deploying to Container Engine is somewhat similar to deploying to App Engine
— you build a Docker image for your app and then deploy it to an existing cluster.
To build your app’s Docker image you can use either of the methods described above in Method 3
— a Dockerfile for a published app, or a Dockerfile that builds and publishes your app during the Docker build process.
Building the app’s Docker image
While you can use any of the strategies defined earlier when writing the Dockerfile for your app, if you want to deploy to Container Engine, you’ll need to build the Docker image yourself. You’ll also need to push the image to a repository from which Container Engine can read the image. The easiest way to do this is to push the image to
Cloud Container Registry, a private Docker image repository that stores images for your project in Cloud Storage.
The simplest way to build a Docker image and push it to Container Registry is to use
Cloud Container Builder, a hosted Docker service that builds Docker images and pushes them to Container Registry in a single operation. First, go to your app’s root deployment directory, which was created as part of “dotnet publish” or is the root of the project, depending on the option you chose. Then run the following command:
kubectl run myservice --image=gcr.io/<your project id>/<app name> --port=8080
This command builds a Docker image called gcr.io/$PROJECT_ID/<app name> where $PROJECT_ID is automatically substituted for your GCP project ID and <app name> is the name of your app.
Deploying the image to a Container Engine cluster
Next, you’ll need to deploy the image you just created to Container Engine. But first, to interact with Container Engine, you need to install
kubectl, which allows you to interact with your cluster from the command line.
The easiest way to install kubectl is to let gcloud do it for you by running:
gcloud components install kubectl
You must also store your cluster’s credentials on your machine so
kubectl can access them. Once you’ve create your Container Engine cluster, run the following command to get those credentials:
gcloud container clusters get-credentials
Now let’s see how to deploy your app to Container Engine. First, create a deployment to run the image. You can do this easily from the command line with the following command:
kubectl run myservice --image=gcr.io/<your project id>/<app name> --port=8080
This creates a new Kubernetes deployment on which to run your app, as well as all the necessary pods. You can even specify the number of replicas of your code to run using the
--replicas=n parameter, where
n is any number of your choosing.
Note: Here, we assume that your Docker containers export port 8080, the default for App Engine flexible environment, and that you expose services from port 80. To change these defaults, read about how to configure HTTPS support for public Kubernetes services.
Then, expose this deployment so it can be seen from outside of your cluster. The easiest way to do this is with the following command:
kubectl expose deployment myservice --port=80 --target-port=8080
--type=LoadBalancer
This exposes the deployment that you created above with a service of type LoadBalancer, indicating that this is a public service with a public IP address.
In conclusion
We're really excited to bring .NET developers to GCP. Whether you like App Engine flexible environment, or prefer the power that Container Engine gives you, we have you covered. We're also investing in making you really productive as a .NET developer on GCP. For more information on how to build apps with .NET for GCP, visit
our .NET page, where you can learn about our .NET libraries and more.
We're fully committed to open source. You can find all our images in the
https://github.com/GoogleCloudPlatform/aspnet-docker repo. We look forward to your feedback, feel free to open issues on the
aspnet-docker repo with your ideas and suggestions.